When we were working with LinkedLists, we could access all items by just “looping through”, from one element to the next, printing as we go along.
But… for a BinarySearchTree, since our structure can now branch as we traverse it… How do we “loop through” a BST?
Two fundamentally different ways to traverse every node in our BST
“Opposites” of each other, so that one is often extremely efficient and the other extremely inefficient for a given task
Your job as a data scientist is to think carefully about which one is more efficient for a given goal!
Two Ways to Traverse: IRL Version
Imagine we’re trying to learn about a topic \(\tau\) using Wikipedia, so we find its article \(\tau_0\)
There are two “extremes” in terms of strategies we could follow for learning, given the contents of the article as well as the links it contains to other articles
Note Depth-First Search (DFS)
Open \(\tau_0\) and start reading it; When we encounter a link we always click it and immediately start reading the new article.
If we hit an article with no links (or a dead end/broken link), we finish reading it and click the back button, picking up where we left off in the previous article. When we reach the end of \(\tau_0\), we’re done!
Note Breadth-First Search (BFS)
Bookmark \(\tau_0\) in a folder called “Level 0 Articles”; open and start reading it
When we encounter a link, we put it in a “Level 1 Articles” folder, but continue reading \(\tau_0\) until we reach the end.
We then open all “Level 1 Articles” in new tabs, placing links we encounter in these articles into a “Level 2 Articles” folder, that we only start reading once all “Level 1 Articles” are read
We continue like this, reading “Level 3 Articles” once we’re done with “Level 2 Articles”, “Level 4 Articles” once we’re done with “Level 3 Articles”, and so on. (Can you see a sense in which this is the “opposite” of DFS?)
Warning: node None_0, port f1 unrecognized
Warning: node None_1, port f1 unrecognized
Warning: node None_2, port f1 unrecognized
Warning: node None_3, port f1 unrecognized
Warning: node None_4, port f1 unrecognized
Warning: node None_5, port f1 unrecognized
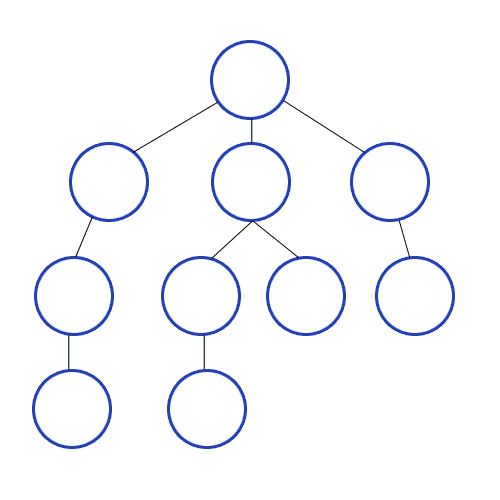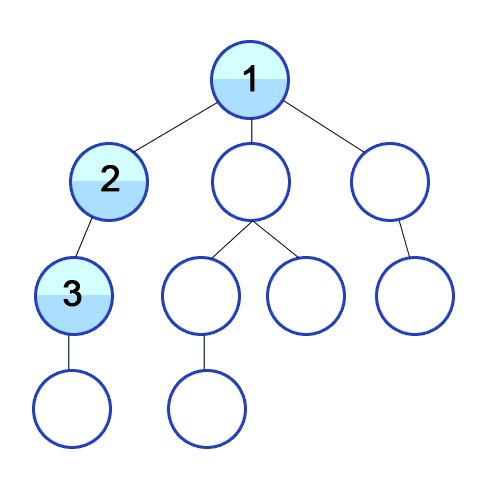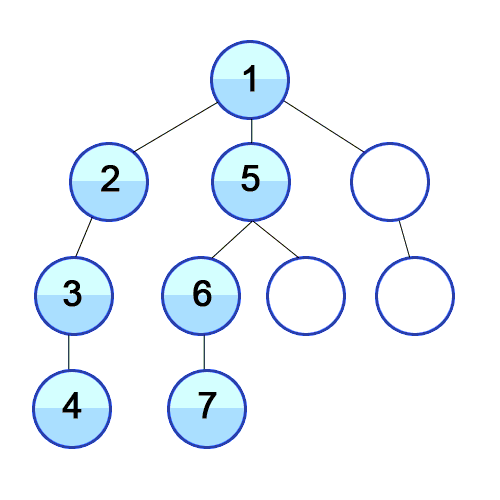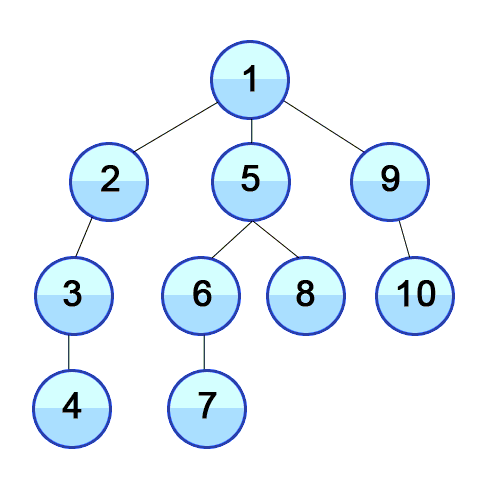
Depth-First Search (DFS): With this approach, we iterate through the BST by always taking the left child as the “next” child until we hit a leaf node (which means, we cannot follow this left-child pointer any longer, since a leaf node does not have a left child or a right child!), and only at that point do we back up and take the right children we skipped.
Breadth-First Search (BFS): This is the “opposite” of DFS in the sense that we traverse the tree level-by-level, never moving to the next level of the tree until we’re sure that we have visited every node on the current level.
Two Ways to Traverse: Underlying Data Structures Version
Now that you have some intuition, you may be thinking that they might require very different code to implement 🤔
This is where mathematical-formal linkage between the two becomes helpful!
It turns out (and a full-on algorithmic theory course makes you prove) that
Depth-First Search can be accomplished by processing nodes in an order determined by adding each to a stack, while
Breadth-First Search can be accomplished by processing nodes in an order determined by adding each to a queue!
\(\implies\) Literally identical code, “pulling out” the word stack and replacing it with the word queue within your code (or vice-versa).
With Software Engineer Hat on, you’ll see this as a job for an abstraction layer!
Two Ways to Traverse: HW2 Version
You’ll make a class called NodeProcessor, with a singleiterate_over(tree) function
This function—without any changes in the code or even any if statements!—will be capable of both DFS and BFS
It will take in a ThingContainer (could be a stack or a queue, you won’t know which), which has two functions:
put_new_thing_in(new_thing)
take_existing_thing_out()
Three Animals in the DFS Species
DFS Procedure
Algorithm
Pre-Order Traversal
1. Print node 2. Traverse left subtree 3. Traverse right subtree
In-Order Traversal 🧐‼️
1. Traverse left subtree 2. Print node 3. Traverse right subtree
Post-Order Traversal
1. Traverse left subtree 2. Traverse right subtree 3. Print node
The Three Animals Traverse our Inventory Tree
Code
visualize(bst)
Warning: node None_0, port f1 unrecognized
Warning: node None_1, port f1 unrecognized
Warning: node None_2, port f1 unrecognized
Warning: node None_3, port f1 unrecognized
Warning: node None_4, port f1 unrecognized
Warning: node None_5, port f1 unrecognized
Final Notes for HW3
The last part challenges you to ask: why stop at a hash based on just the first letter of the key?
We could just as easily use the first two letters:
h('AA') = 0, h('AB') = 1, …, h('AZ') = 25,
h('BA') = 26, h('BB') = 27, …, h('BZ') = 51,
h('CA') = 52, …, h('ZZ') = 675.
You will see how this gets us even closer to the elusive \(O(1)\)! And we could get even closer with three letters, four letters, … 🤔🤔🤔
Functional Programming (FP)
Functions vs. Functionals
You may have noticed: map() and reduce() are “meta-functions”: functions that take other functions as inputs
When a program doesn’t work, each function is an interface point where you can check that the data are correct. You can look at the intermediate inputs and outputs to quickly isolate the function that’s responsible for a bug. (from Python’s “Functional Programming HowTo”)
Scenario: Run code, check the output, and… it’s wrong 😵 what do you do?
Usual approach: Read lines one-by-one, figuring out what they do, seeing if something pops out that seems wrong; adding comments like # Convert to lowercase
Easy case: found typo in punctuation removal code. Fix the error, add comment like # Remove punctuation
Rule 1 of FP: transform these comments into function names
Hard case: Something in load_text() modifies a variable that later on breaks remove_punct() (Called a side-effect)
Rule 2 of FP: NO SIDE-EFFECTS!
(Does this way of diagramming a program look familiar?)
With side effects: ❌ \(\implies\) issue is somewhere earlier in the chain 😩🏃♂️
No side effects: ❌ \(\implies\) issue must be in remove_punct()!!! 😎 ⏱️ = 💰
If It’s So Useful, Why Doesn’t Everyone Do It?
Trapped in imperative (sequential) coding mindset: Path dependency / QWERTY
Reason we need to start thinking like this is: it’s 1000x harder to debug parallel code! So we need to be less ad hoc in how we write+debug, from here on out! 🙇♂️🙏
The title relates to a classic Economics joke (the best kind of joke): “An economist and a CEO are walking down the street, when the CEO points at the ground and tells the economist, ‘look! A $20 bill on the ground!’ The economist keeps on walking, scoffing at the CEO: ‘don’t be silly, if there was a $20 bill on the ground, somebody would have picked it up already’.”