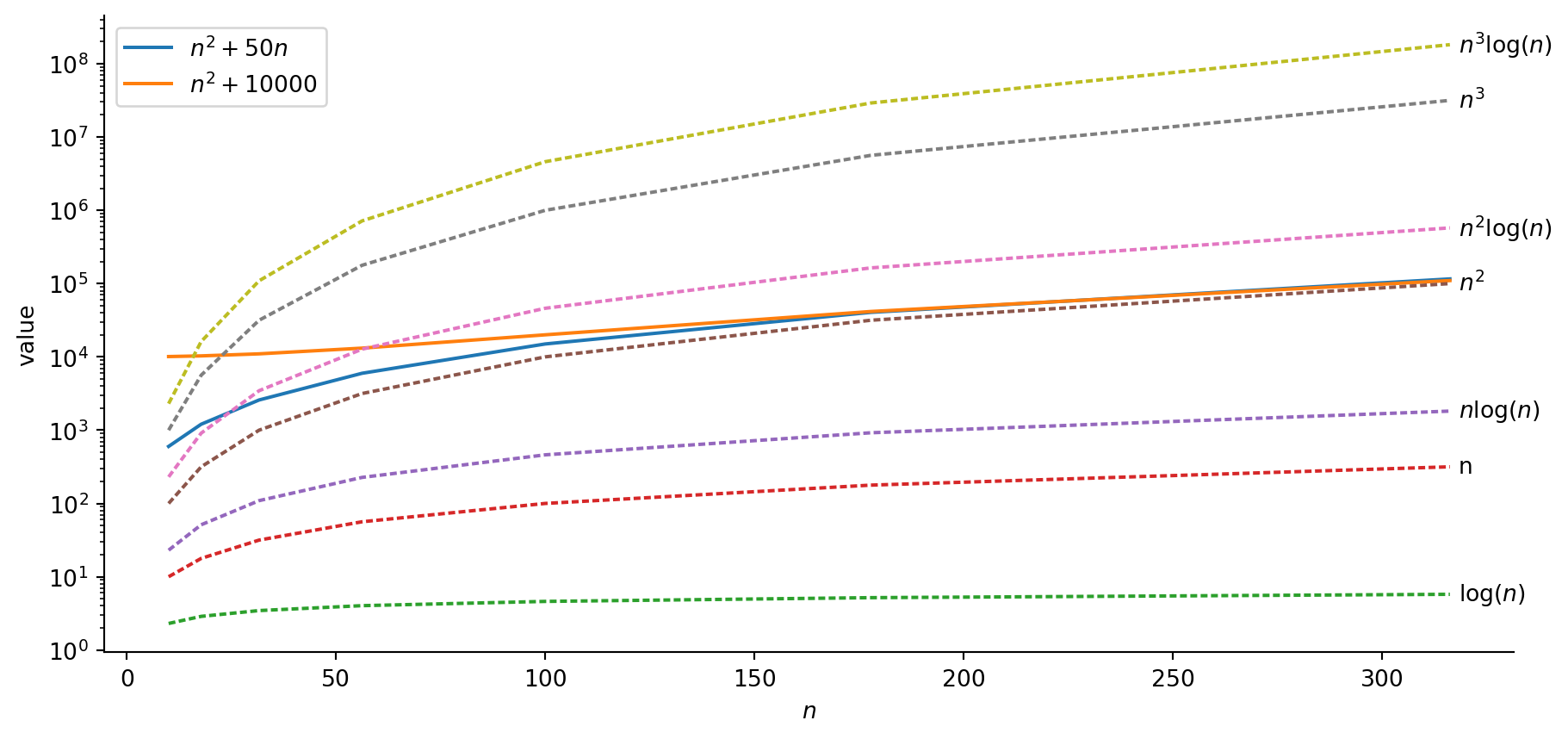
So, there’s a sense in which \(T(n) \approx n^2\), for “sufficiently large” values of \(n\)…
Let’s work our way towards formalizing the \(\approx\)!
The Figure You Can Make In Your Head All Semester
Code
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsn_vals = [np.power(10, k) for k in np.arange(1, 2.75, 0.25)]runtime_df = pd.DataFrame({'$n$': n_vals})runtime_df['$n^2 + 50n$'] = runtime_df['$n$'].apply(lambda x: np.power(x, 2) +50*x)runtime_df['$n^2 + 10000$'] = runtime_df['$n$'].apply(lambda x: np.power(x, 2) +10000)runtime_df['$\log(n)$'] = runtime_df['$n$'].apply(lambda x: np.log(x))runtime_df['n'] = runtime_df['$n$'].copy()runtime_df['$n\log(n)$'] = runtime_df['$n$'].apply(lambda x: x * np.log(x))runtime_df['$n^2$'] = runtime_df['$n$'].apply(lambda x: np.power(x, 2))runtime_df['$n^2\log(n)$'] = runtime_df['$n$'].apply(lambda x: np.power(x,2) * np.log(x))runtime_df['$n^3$'] = runtime_df['$n$'].apply(lambda x: np.power(x, 3))runtime_df['$n^3logn$'] = runtime_df['$n$'].apply(lambda x: np.power(x, 3) * np.log(x))# Get the max values, for labeling the ends of linesmax_vals = runtime_df.max().to_dict()plot_df = runtime_df.melt(id_vars=['$n$'])#print(plot_df)style_map = {col: ''if (col =='$n^2 + 50n$') or (col =='$n^2 + 10000$') else (2,1) for col in runtime_df.columns}fig, ax = plt.subplots(figsize=(11,5))sns.lineplot(plot_df, x='$n$', y='value', hue='variable', style='variable', dashes=style_map)#plt.xscale('log')plt.yscale('log')# extract the existing handles and labelsh, l = ax.get_legend_handles_labels()# slice the appropriate section of l and h to include in the legendax.legend(h[0:2], l[0:2])for label, val in max_vals.items():if (label =='$n$') or (label =='$n^2 + 50n$') or (label =='$n^2 + 10000$'):continueif'logn'in label: label = label.replace('logn', r'\log(n)') ax.text(x = max_vals['$n$'] +2, y = val, s=label, va='center')# Hide the right and top spinesax.spines[['right', 'top']].set_visible(False)plt.show()
<>:9: SyntaxWarning:
"\l" is an invalid escape sequence. Such sequences will not work in the future. Did you mean "\\l"? A raw string is also an option.
<>:11: SyntaxWarning:
"\l" is an invalid escape sequence. Such sequences will not work in the future. Did you mean "\\l"? A raw string is also an option.
<>:13: SyntaxWarning:
"\l" is an invalid escape sequence. Such sequences will not work in the future. Did you mean "\\l"? A raw string is also an option.
<>:9: SyntaxWarning:
"\l" is an invalid escape sequence. Such sequences will not work in the future. Did you mean "\\l"? A raw string is also an option.
<>:11: SyntaxWarning:
"\l" is an invalid escape sequence. Such sequences will not work in the future. Did you mean "\\l"? A raw string is also an option.
<>:13: SyntaxWarning:
"\l" is an invalid escape sequence. Such sequences will not work in the future. Did you mean "\\l"? A raw string is also an option.
/var/folders/n2/m7_fj5vx6c50_yj7g23mwmq00000gn/T/ipykernel_79292/1423556624.py:9: SyntaxWarning:
"\l" is an invalid escape sequence. Such sequences will not work in the future. Did you mean "\\l"? A raw string is also an option.
/var/folders/n2/m7_fj5vx6c50_yj7g23mwmq00000gn/T/ipykernel_79292/1423556624.py:11: SyntaxWarning:
"\l" is an invalid escape sequence. Such sequences will not work in the future. Did you mean "\\l"? A raw string is also an option.
/var/folders/n2/m7_fj5vx6c50_yj7g23mwmq00000gn/T/ipykernel_79292/1423556624.py:13: SyntaxWarning:
"\l" is an invalid escape sequence. Such sequences will not work in the future. Did you mean "\\l"? A raw string is also an option.
For low values of \(n\), \(n^2 + 10000\) looks “far away from” \(n^2\)
…But we care about how the algorithm scales with input size!
Takeaway: As \(n \rightarrow \infty\), highest-degree terms dominate!
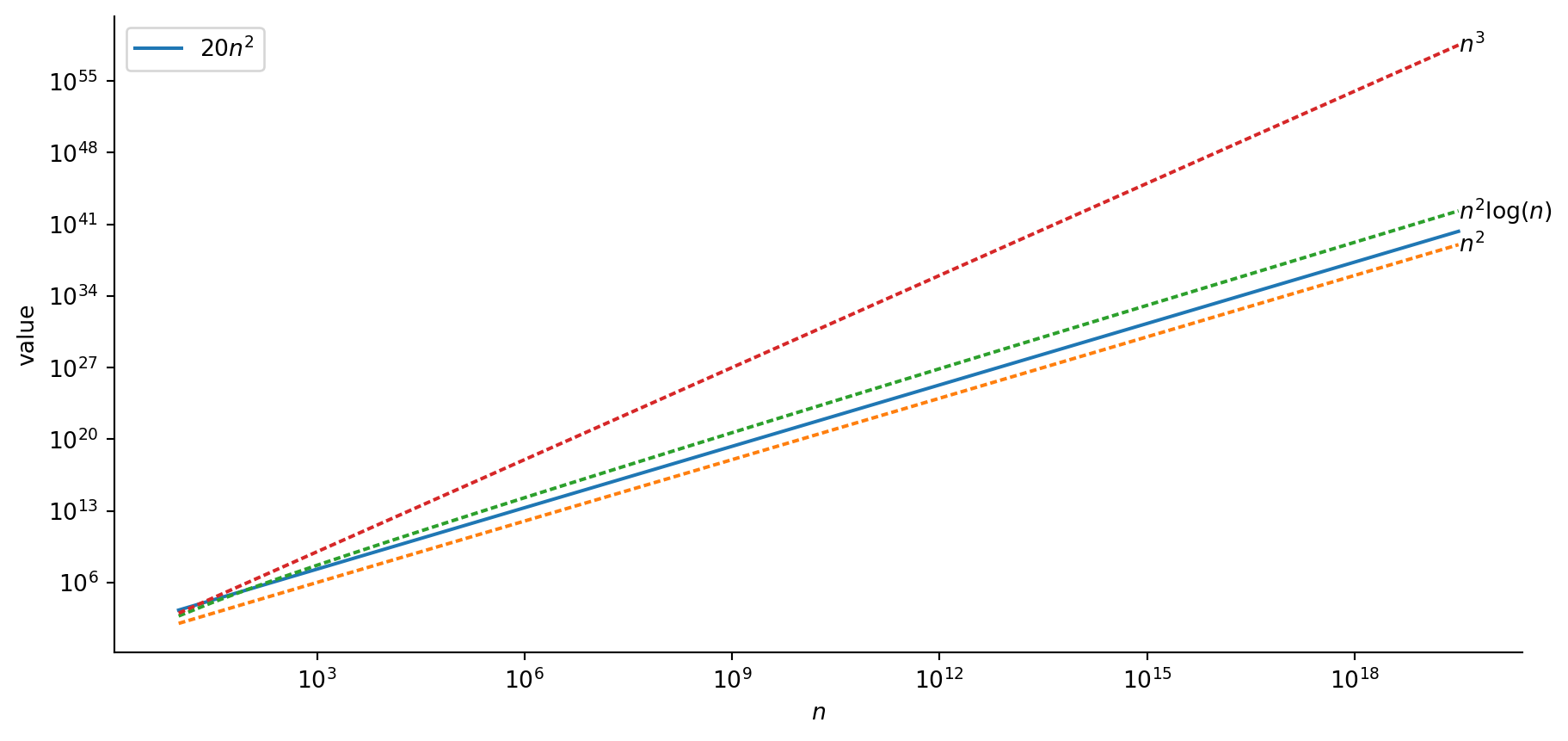
Constants On Highest-Degree Terms Also Go Away
(Though this is harder to see, without a log-log plot:)
Code
n_vals = [np.power(10, k) for k in np.arange(1, 20, 0.5)]rt_const_df = pd.DataFrame({'$n$': n_vals})rt_const_df['$20n^2$'] = rt_const_df['$n$'].apply(lambda x: 20*np.power(x,2))rt_const_df['$n^2$'] = rt_const_df['$n$'].apply(lambda x: np.power(x,2))rt_const_df['$n^2logn$'] = rt_const_df['$n$'].apply(lambda x: np.power(x,2) * np.power(np.log(x),2))rt_const_df['$n^3$'] = rt_const_df['$n$'].apply(lambda x: np.power(x,3))# Get the max values, for labeling the ends of linesmax_vals = rt_const_df.max().to_dict()plot_df_const = rt_const_df.melt(id_vars=['$n$'])style_map = {col: ''if (col =='$20n^2$') else (2,1) for col in rt_const_df.columns}fig_const, ax_const = plt.subplots(figsize=(11,5))sns.lineplot(plot_df_const, x='$n$', y='value', hue='variable', style='variable', dashes=style_map)plt.xscale('log')plt.yscale('log')# extract the existing handles and labelsh_const, l_const = ax_const.get_legend_handles_labels()# slice the appropriate section of l and h to include in the legendax_const.legend(h_const[0:1], l_const[0:1])for label, val in max_vals.items():if (label =='$n$') or (label =='$20n^2$'):continueif'logn'in label: label = label.replace('logn', r'\log(n)') ax_const.text(x = max_vals['$n$'] +10**4, y = val, s=label, va='center')# Hide the right and top spinesax_const.spines[['right', 'top']].set_visible(False)plt.show()
Formalizing Big-O Notation
Let \(f, g: \mathbb{N} \rightarrow \mathbb{N}\). Then we write \(f(n) = O(g(n))\) when there exists a threshold\(n_0 > 0\) and a constant\(K > 0\) such that \[
\forall n \geq n_0 \left[ f(n) \leq K\cdot g(n) \right]
\]
In words: beyond a certain point \(n_0\), \(f(n)\) is bounded above by \(K\cdot g(n)\).
Proof: Let \(K = 50\). Then \[
\begin{align*}
&n^2 + 50n \leq 50n^2 \iff n + 50 \leq 50n \\
&\iff 49n \geq 50 \iff n \geq \frac{50}{49}.
\end{align*}
\]
So if we choose \(n_0 = 2\), the chain of statements holds. \(\blacksquare\)
Bounding Insertion Sort Runtime
Runs in \(T(n) = O(n^2)\) (use constants from prev slide)
Can similarly define lower bound\(T(n) = \Omega(f(n))\)
\(O\) = “Big-Oh”, \(\Omega\) = “Big-Omega”
Need to be careful with \(O(f(n))\) vs. \(\Omega(f(n))\) however: difference between “for all inputs” vs. “for some inputs”:
NoteBounding Worst-Case Runtime
By saying that the worst-case running time of an algorithm is \(\Omega(n^2)\), we mean that for every input size \(n\) above a certain threshold, there is at least one input of size \(n\) for which the algorithm takes at least \(cn^2\) time, for some positive constant \(n\). It does not necessarily mean that the algorithm takes at least \(cn^2\) time for all inputs.
Intuition for Lower Bound
Spoiler: Insertion sort also runs in \(T(n) = \Omega(n^2)\) time. How could we prove this?
Given any value \(n > n_0\), we need to construct an input for which Insertion-Sort requires \(cn^2\) steps: consider a list where \(n/3\)greatest values are in first \(n/3\) slots:
All \(n/3\) values in \(\textrm{L}\) pass, one-by-one, through the \(n/3\) slots in \(\textrm{M}\) (since they must end up in \(\textrm{R}\)) \(\implies (n/3)(n/3) = n^2/9 = \Omega(n^2)\) steps!
Final definition (a theorem you could prove if you want!): \(\Theta\) = “Big-Theta”
If \(T(n) = \overline{O}(g(n))\) and \(T(n) = \Omega(g(n))\), then \(T(n) = \Theta(n)\)
\(\implies\)most “informative” way to characterize insertion sort is \(\boxed{T(n) = \Theta(n^2)}\)
Why Can’t We Learn Data Structures and Algorithms Separately?
Data Structure Choice \(\Leftrightarrow\) Algorithmic Efficiency for Task
Question: “Is this algorithm efficient?”
Answer: “…Efficient for what?”
Do we need to be able to insert quickly?
Do we need to be able to sort quickly?
Do we need to be able to search quickly?
Are we searching for individual items or for ranges?
Basic Data Structures
Recall: Primitives
bool
int
float
None
Now we want to put these together, to form… structures! 👀
Structures are the things that live in the heap; the stack just points to them
Tuples
Fixed-size collection of \(N\) objects
Unless otherwise specified, we’re talking about \(2\)-tuples
Example: We can locate something on the Earth by specifying two floats: latitude and longitude!
Code
gtown_loc = (38.9076, -77.0723)gtown_loc
(38.9076, -77.0723)
But what if we don’t know in advance how many items we want to store? Ex: how can we store users for a new app?
Sequences
In General: Mapping of integer indices to objects
x = ['a','b','c']
\(\implies\)x[0] = 'a'
\(\implies\)x[1] = 'b'
\(\implies\)x[2] = 'c'
In Python: list
Nice built-in language constructs for looping over lists, and especially for performing operations on each element
Looping Over Sequences
C/C++/Java:
List<String> myList =Arrays.asList("a","b","c");for(int i =0; i < x.size(); i++){System.out.println(myList.get(i));}
a
b
c
Python:
Code
my_list = ['a','b','c']for list_element in my_list:print(list_element)
a
b
c
List Comprehensions: Apply [Operation] to Each Element
Construct new list by applying operation to each element:
Code
my_nums = [4,5,6,7]my_squares = [num **2for num in my_nums]my_squares
[16, 25, 36, 49]
Can also filter the elements of the list with if:
Code
my_odd_squares = [num **2for num in my_nums if num %2==1]my_odd_squares
[25, 49]
Sets
Efficient for finding unique elements:
prefs_morn = ['None','None','None','Vegan','Vegan','None','Gluten Free']print(f"Number of responses: {len(prefs_morn)}")
Number of responses: 7
unique_prefs_morn =set(prefs_morn)print(f"Unique preferences: {unique_prefs_morn}")print(f"Number of unique preferences: {len(unique_prefs_morn)}")
Unique preferences: {'Vegan', 'None', 'Gluten Free'}
Number of unique preferences: 3
Ordering / indexing of elements is gone!
unique_prefs_morn[2]
---------------------------------------------------------------------------TypeError Traceback (most recent call last)
CellIn[18], line 1----> 1unique_prefs_morn[2]TypeError: 'set' object is not subscriptable
But, supports set operators from math! →
Union (\(M \cup E\)):
prefs_eve = ['None','None','Vegan','None','None']unique_prefs_eve =set(prefs_eve)unique_prefs_either = unique_prefs_morn.union(unique_prefs_eve)print(f"Preferences in either event: {unique_prefs_either}")
Preferences in either event: {'Vegan', 'None', 'Gluten Free'}
Intersection (\(M \cap E\)):
unique_prefs_both = unique_prefs_morn.intersection(unique_prefs_eve)print(f"Preferences in both events: {unique_prefs_both}")
Preferences in both events: {'Vegan', 'None'}
Set Difference (\(M \setminus E\) or \(E \setminus M\)):
unique_prefs_mornonly = unique_prefs_morn - unique_prefs_eveprint(f"Preferences only in the morning: {unique_prefs_mornonly}")unique_prefs_eveonly = unique_prefs_eve - unique_prefs_mornprint(f"Preferences only in the evening: {unique_prefs_eveonly}")
Preferences only in the morning: {'Gluten Free'}
Preferences only in the evening: set()
Maps / Dictionaries
While other language like Java have lots of fancy types of Map, Python has a single type, the dictionary:
How many steps did this take? How about for a list with \(5\) elements? \(N\) elements?
Last Example: Pairwise-Concat + End Check
Code
printed_items = []cur_pointer1 = users.rootwhile cur_pointer1 isnotNone: cur_pointer2 = users.rootwhile cur_pointer2 isnotNone:print(cur_pointer1.content + cur_pointer2.content) printed_items.append(cur_pointer1.content) printed_items.append(cur_pointer2.content) cur_pointer2 = cur_pointer2.next cur_pointer1 = cur_pointer1.nextcheck_pointer = users.rootwhile check_pointer isnotNone:if check_pointer.content in printed_items:print(f"Phew. {check_pointer.content} printed at least once.")else:print(f"Oh no! {check_pointer.content} was never printed!!!") check_pointer = check_pointer.next
JeffJeff
JeffAlma
JeffBo
AlmaJeff
AlmaAlma
AlmaBo
BoJeff
BoAlma
BoBo
Phew. Jeff printed at least once.
Phew. Alma printed at least once.
Phew. Bo printed at least once.
Generalizing
Algorithms are “efficient” relative to how their runtime scales as the objects grow larger and larger!
Tuple operations take 1 step no matter what
For lists, retrieving the first element takes 1 step no matter what, but retrieving the last element takes \(n\) steps!
Crucial to think asymptotically to wrap our heads around this!
References
Cormen, Thomas H., Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. 2001. Introduction To Algorithms. MIT Press. https://books.google.com?id=NLngYyWFl_YC.
Master Theorem: Let \(a > 0\) and \(b > 1\) be constants, and let \(f(n)\) be a driving function defined and nonnegative on all sufficiently large reals. Define \(T(n)\) on \(n \in \mathbb{N}\) by
\[
T(n) = aT(n/b) + f(n)
\]
where \(aT(n/b) = a'T(\lfloor n/b \rfloor) + a''T(\lceil n/b \rceil)\) for some \(a' \geq 0\) and \(a'' \geq 0\) satisfying \(a = a' + a''\). Then the asymptotic behavior of \(T(n)\) can be characterized as follows:
If there exists \(\epsilon > 0\) such that \(f(n) = O(n^{\log_b(a) - \epsilon})\), then \(T(n) = \Theta(n^{\log_b(a)})\)
If there exists \(k \geq 0\) such that \(f(n) = \Theta(n^{\log_b(a)}\log_2^k(n))\), then \(T(n) = \Theta(n^{\log_b(a)}\log_2^{k+1}(n))\).
If there exists \(\epsilon > 0\) such that \(f(n) = \Omega(n^{\log_b(a) + \epsilon})\), and if \(f(n)\) satisfies the regularity condition\(af(n/b) \leq cf(n)\) for some constant \(c < 1\) and all sufficiently large \(n\), then \(T(n) = \Theta(f(n))\).