(Spoiler alert, so you know I’m not lying to you: this is a LinkedList with some additional structure!)
You just got hired as a cashier (Safeway cashiering alum myself 🫡)
The scanner is broken (spoiler #2: the scanner uses a hash table), so you start writing down items along with their prices, one-by-one, as items come in…
As the list gets longer, it gets harder and harder to find where you wrote down a specific item and its price
As you now know, you could use linear search, \(\overline{O}(n)\), or if you ensure alphabetical order (an invariant!), you could use binary, divide-and-conquer search, \(\overline{O}(\log_2(n))\)
We can do even better: \(\overline{O}(1)\). First w/magic, but then math
Strange-At-First Technique for Algorithm Analysis: Oracles
What if we had a magical wizard who could just tell us where to find an item we were looking for?
Sounds like I’m joking/saying “what if we had a billion $ and infinite charisma and could fly and walk through walls”
Yet, through the magic of math/CS, there are concrete hashing algorithms which ensure (in a mathematically-provable way!) “almost certain” \(\overline{O}(1)\) lookup time
Mathematical Strategy of Oracles
We’ll use a concrete, simplified hash function to illustrate
Mathematically we’ll be able to get something like
Our hash function: hash(item) = first letter of item
\[
h(\texttt{x}) = \texttt{x[0]}
\]
h('Banana') = 'B', h('Monkey') = 'M'
With this function in hand, we can create a length-26 array, one slot for each letter in alphabet, and then write down (item, price) pairs in whatever slot item hashes to
The Importance of Differentiating Operations: Insertion vs. Lookup
So far, we have \(\overline{O}(1)\)insertion via hashing
We also get \(\overline{O}(1)\)lookup!
When customer hands us an item (say, 'Banana'), we compute the hash (B), look in that slot, and obtain the price for bananas.
We also get \(\overline{O}(1)\)updating (hash to find the old price, update it to have new price) and \(\overline{O}(1)\)deletion (hash to find the slot containing the item, then erase it from that slot)
So What’s the Catch???
BLUEBERRIES show up to ruin our day (as usual 😞)
We hash, so far so good: h('Blueberries') = 'B'
But then we go to the B slot and see that (Bananas, 10) is already there!!! Wtf do we do here… don’t panic!
The answer? We open our HW2 from DSAN 5500 and remember that we have our lovely friend the LinkedList that we can use whenever and however we want!
Arrays vs. Linked Lists
Jeff is hiding something here… Why jump to LinkedList? Why not just… another length-26 array, for example?
For this we open up our Week 1 slides and remember the stack vs. heap distinction: we know how many letters in the alphabet, we don’t know how many items starting with B (or, if we do, we want to be able to expand/contract our price list to handle new/discontinued items)
Terminology for this kind of “hybrid” data structure: HashTable is an Array that “degenerates into” a LinkedList (when there are collisions)
Look How Far We Came!
Last week: Only structure we knew allowing insertion (LinkedList) was \(\overline{O}(n)\) for everythihg
This week: New structure where suddenly everything is \(\overline{O}(1)\), except in “unlucky” cases, in which it partially “degenerates” into a LinkedList
\(\implies\) By taking core data structures/algorithms from your toolkit, you can “piece together” hybrid structures whose whole (runtime) is better than the sum of its parts
Hash Tables: tl;dr Edition
Keys\(k \in \mathcal{K}\) are plugged into a (deterministic) hash function\(h: \mathcal{K} \rightarrow \{1, \ldots, N\}\), producing an index where \(k\) is stored
If nothing at that index yet, store \((k,v)\) in empty slot
If already an item at that index, we have a ⚠️collision⚠️
We could just throw away the old value (HW2 Part 1)
Otherwise, need a way to store multiple items in one slot… (a way to dynamically grow storage at given index)
Solution you know so far: Linked Lists
New solution: Binary Search Trees!
Binary Search Trees
If you’ve been annoyed by how long we’ve talked about Linked Lists for… this is where it finally pays off!
BST: The Final Missing Data Structure
Just a glorified LinkedList! We’ll be able to take our HashMap and “drop in” the BST to play the role LinkedList is playing right now
If collision, we’ll create a BST with its \(\overline{O}(\log(n))\) operations, rather than a LinkedList with its \(\overline{O}(n)\) operations
\(\implies\)HashMap will go from:
\(\overline{O}(1)\) best-case but \(\overline{O}(n)\) worst-case to
\(\overline{O}(1)\) best-case but \(\overline{O}(\log_2(n))\) worst-case!
Linked Lists + Divide-and-Conquer = BSTs
By now, the word “Linked List” should make you groan, cross your arms and start tapping your feet with impatience
“Here we go again… the Linked List is gonna make us traverse through every single element before we reach the one we’re looking for” 😖
Linked List = Canon in D
Binary Search Tree = Canon in D played by Hiromi Uehara…
Warning: node None_0, port f1 unrecognized
Warning: node None_1, port f1 unrecognized
Warning: node None_2, port f1 unrecognized
Warning: node None_3, port f1 unrecognized
Warning: node None_4, port f1 unrecognized
Warning: node None_5, port f1 unrecognized
Practical Considerations
Hash Maps: Only useful if keys are hashable
Python has a built-in collections.abc.Hashable class, such that hash(my_obj) works iff isinstance(my_obj, Hashable)
Binary Search Trees: Only useful if keys have an ordering
“Standard” classes (int, str, datetime) come with implementations of ordering, but if you make your own class you need to implement the ordering for it!
(Linked Lists still work for non-hashable/orderable objects!)
Why ==, <, >= “Just Work”
Not magic! Someone has explicitly written a set of functions telling Python what to do when it sees e.g. obj1 < obj2
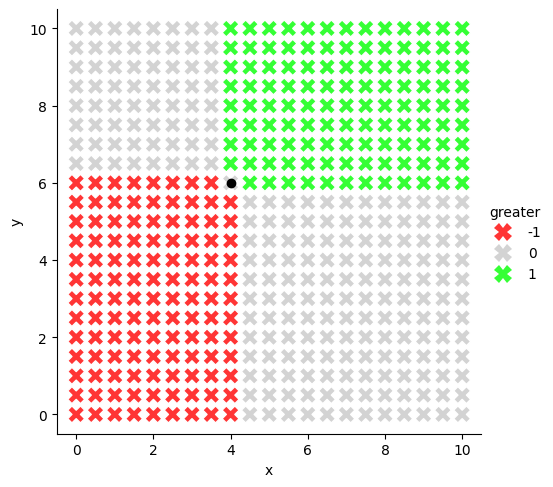
Example: let’s implement an ordering of vectors \(\mathbf{x} \in \mathbb{R}^2\) based on Pareto dominance
Ordering Vectors via Pareto Dominance
Back to BSTs
For HW2, we provide you with an InventoryItem class
When we were working with LinkedLists, we could access all items by just “looping through”, from one element to the next, printing as we go along.
But… for a BinarySearchTree, since our structure can now branch as we traverse it… How do we “loop through” a BST?
Two fundamentally different ways to traverse every node in our BST
“Opposites” of each other, so that one is often extremely efficient and the other extremely inefficient for a given task
Your job as a data scientist is to think carefully about which one is more efficient for a given goal!
Two Ways to Traverse: IRL Version
Imagine we’re trying to learn about a topic \(\tau\) using Wikipedia, so we find its article \(\tau_0\)
There are two “extremes” in terms of strategies we could follow for learning, given the contents of the article as well as the links it contains to other articles
Note Depth-First Search (DFS)
Open \(\tau_0\) and start reading it; When we encounter a link we always click it and immediately start reading the new article.
If we hit an article with no links (or a dead end/broken link), we finish reading it and click the back button, picking up where we left off in the previous article. When we reach the end of \(\tau_0\), we’re done!
Note Breadth-First Search (BFS)
Bookmark \(\tau_0\) in a folder called “Level 0 Articles”; open and start reading it
When we encounter a link, we put it in a “Level 1 Articles” folder, but continue reading \(\tau_0\) until we reach the end.
We then open all “Level 1 Articles” in new tabs, placing links we encounter in these articles into a “Level 2 Articles” folder, that we only start reading once all “Level 1 Articles” are read
We continue like this, reading “Level 3 Articles” once we’re done with “Level 2 Articles”, “Level 4 Articles” once we’re done with “Level 3 Articles”, and so on. (Can you see a sense in which this is the “opposite” of DFS?)
from hw2 import IterAlgorithm, NodeProcessorvisualize(bst)
Warning: node None_0, port f1 unrecognized
Warning: node None_1, port f1 unrecognized
Warning: node None_2, port f1 unrecognized
Warning: node None_3, port f1 unrecognized
Warning: node None_4, port f1 unrecognized
Warning: node None_5, port f1 unrecognized
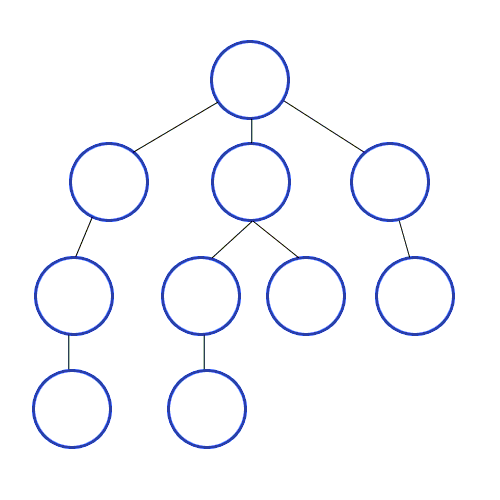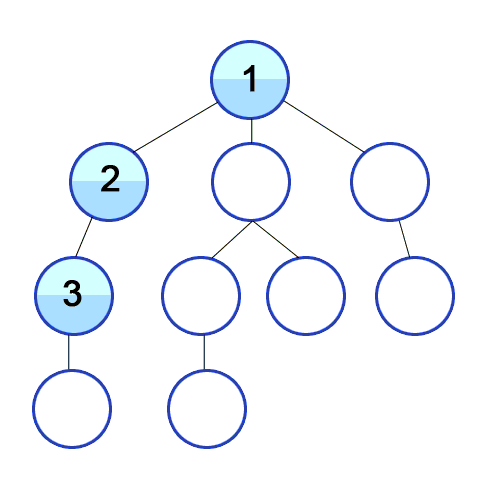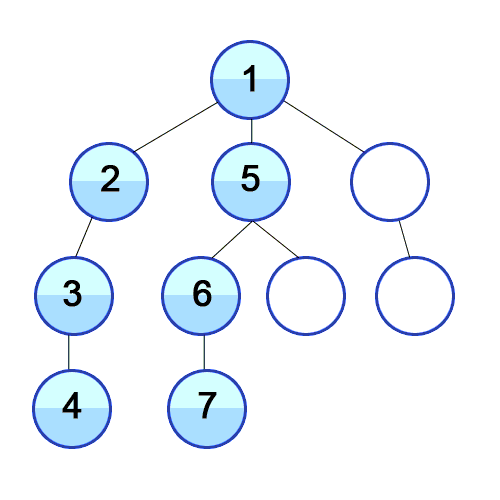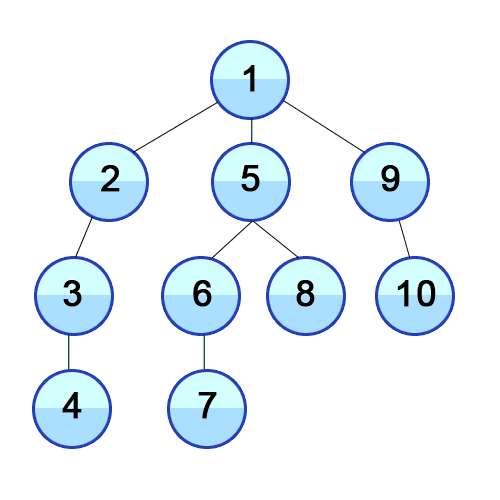
Depth-First Search (DFS): With this approach, we iterate through the BST by always taking the left child as the “next” child until we hit a leaf node (which means, we cannot follow this left-child pointer any longer, since a leaf node does not have a left child or a right child!), and only at that point do we back up and take the right children we skipped.
Breadth-First Search (BFS): This is the “opposite” of DFS in the sense that we traverse the tree level-by-level, never moving to the next level of the tree until we’re sure that we have visited every node on the current level.
Two Ways to Traverse: Underlying Data Structures Version
Now that you have some intuition, you may be thinking that they might require very different code to implement 🤔
This is where the mathematical-formal linkage between the two becomes ultra helpful!
It turns out (and a full-on algorithmic theory course makes you prove) that
Depth-First Search can be accomplished by processing nodes in an order determined by adding each to a stack, while
Breadth-First Search can be accomplished by processing nodes in an order determined by adding each to a queue!
\(\implies\) Literally identical code, “pulling out” the word stack and replacing it with the word queue within your code (or vice-versa).
If you have your Software Engineer Hats on, you’ll recognize this as a job for an abstraction layer!
Two Ways to Traverse: HW2 Version
You’ll make a class called NodeProcessor, with a singleiterate_over(tree) function
This function—without any changes in the code or even any if statements!—will be capable of both DFS and BFS
It will take in a ThingContainer (could be a stack or a queue, you won’t know which), which has two functions:
put_new_thing_in(new_thing)
take_existing_thing_out()
Three Animals in the DFS Species
DFS Procedure
Algorithm
Pre-Order Traversal
1. Print node 2. Traverse left subtree 3. Traverse right subtree
In-Order Traversal 🧐‼️
1. Traverse left subtree 2. Print node 3. Traverse right subtree
Post-Order Traversal
1. Traverse left subtree 2. Traverse right subtree 3. Print node
The Three Animals Traverse our Inventory Tree
Code
visualize(bst)
Warning: node None_0, port f1 unrecognized
Warning: node None_1, port f1 unrecognized
Warning: node None_2, port f1 unrecognized
Warning: node None_3, port f1 unrecognized
Warning: node None_4, port f1 unrecognized
Warning: node None_5, port f1 unrecognized
Final Notes for HW2
The last part challenges you to ask: why stop at a hash based on just the first letter of the key?
We could just as easily use the first two letters:
h('AA') = 0, h('AB') = 1, …, h('AZ') = 25,
h('BA') = 26, h('BB') = 27, …, h('BZ') = 51,
h('CA') = 52, …, h('ZZ') = 675.
You will see how this gets us even closer to the elusive \(O(1)\)! And we could get even closer with three letters, four letters, … 🤔🤔🤔