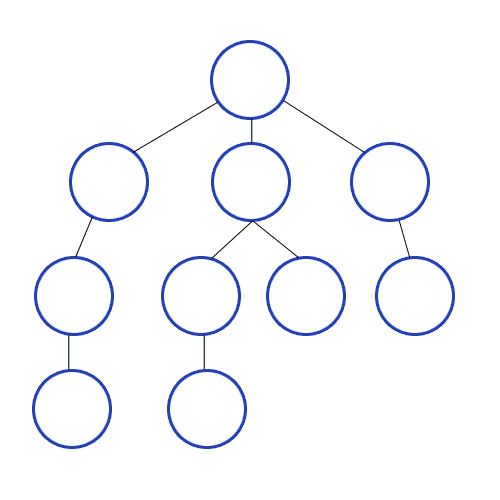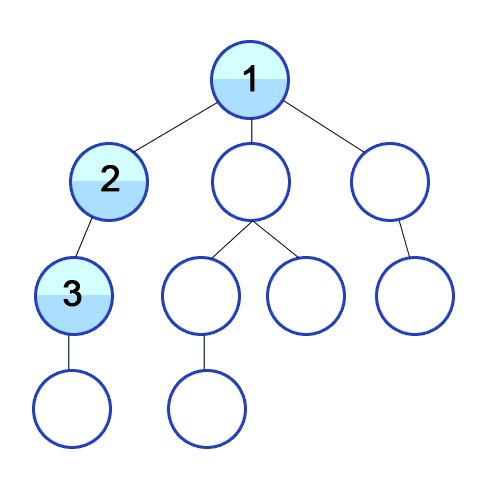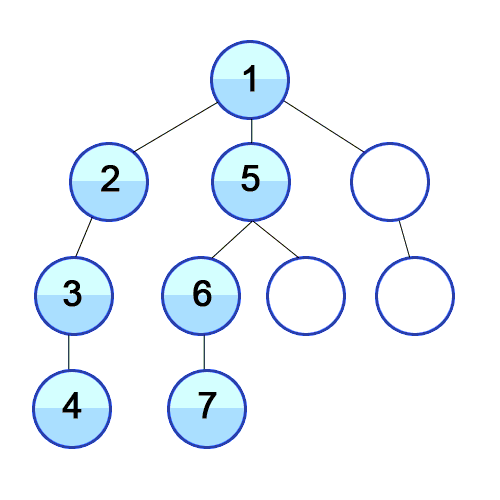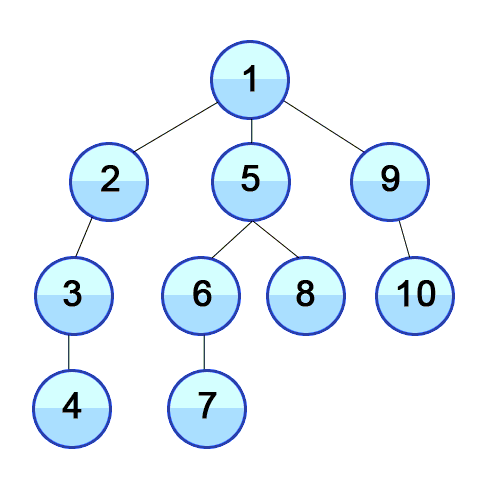
Breadth-First Search (BFS)
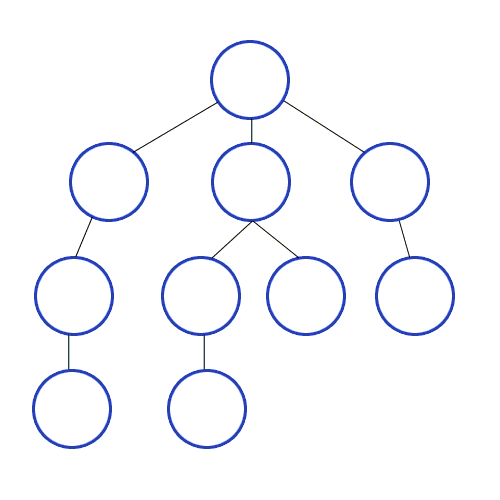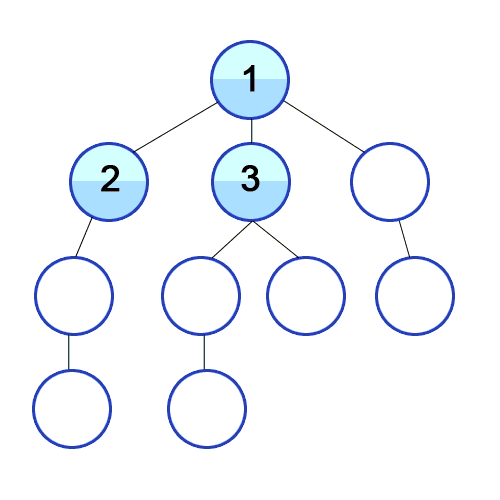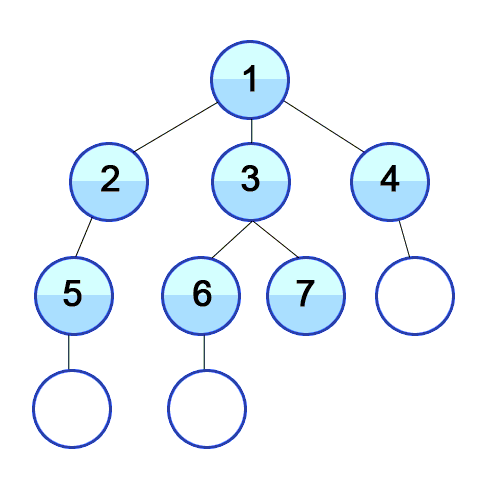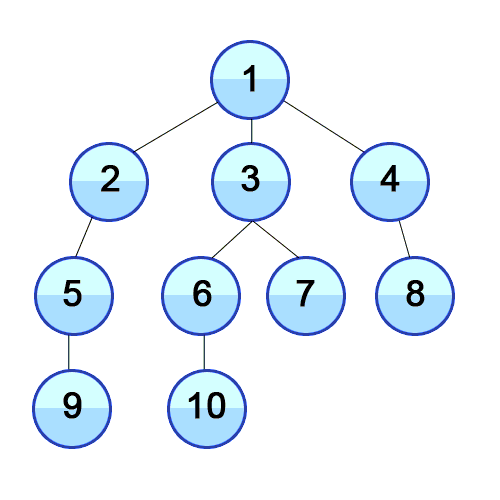
- Bookmark \(\tau_0\) in a folder called “Level 0 Articles”; open and start reading it
- When we encounter a link, we put it in a “Level 1 Articles” folder, but continue reading \(\tau_0\) until we reach the end.
- We then open all “Level 1 Articles” in new tabs, placing links we encounter in these articles into a “Level 2 Articles” folder, that we only start reading once all “Level 1 Articles” are read
- We continue like this, reading “Level 3 Articles” once we’re done with “Level 2 Articles”, “Level 4 Articles” once we’re done with “Level 3 Articles”, and so on. (Can you see a sense in which this is the “opposite” of DFS?)