source("../dsan-globals/_globals.r")Week 5A: Moments and Covariance
DSAN 5100: Probabilistic Modeling and Statistical Computing
Section 01
Class Sessions
Moments of a Distribution: Expectation and Variance
\[ \DeclareMathOperator*{\argmax}{argmax} \DeclareMathOperator*{\argmin}{argmin} \newcommand{\bigexp}[1]{\exp\mkern-4mu\left[ #1 \right]} \newcommand{\bigexpect}[1]{\mathbb{E}\mkern-4mu \left[ #1 \right]} \newcommand{\definedas}{\overset{\small\text{def}}{=}} \newcommand{\definedalign}{\overset{\phantom{\text{defn}}}{=}} \newcommand{\eqeventual}{\overset{\text{eventually}}{=}} \newcommand{\Err}{\text{Err}} \newcommand{\expect}[1]{\mathbb{E}[#1]} \newcommand{\expectsq}[1]{\mathbb{E}^2[#1]} \newcommand{\fw}[1]{\texttt{#1}} \newcommand{\given}{\mid} \newcommand{\green}[1]{\color{green}{#1}} \newcommand{\heads}{\outcome{heads}} \newcommand{\iid}{\overset{\text{\small{iid}}}{\sim}} \newcommand{\lik}{\mathcal{L}} \newcommand{\loglik}{\ell} \DeclareMathOperator*{\maximize}{maximize} \DeclareMathOperator*{\minimize}{minimize} \newcommand{\mle}{\textsf{ML}} \newcommand{\nimplies}{\;\not\!\!\!\!\implies} \newcommand{\orange}[1]{\color{orange}{#1}} \newcommand{\outcome}[1]{\textsf{#1}} \newcommand{\param}[1]{{\color{purple} #1}} \newcommand{\pgsamplespace}{\{\green{1},\green{2},\green{3},\purp{4},\purp{5},\purp{6}\}} \newcommand{\pedge}[2]{\require{enclose}\enclose{circle}{~{#1}~} \rightarrow \; \enclose{circle}{\kern.01em {#2}~\kern.01em}} \newcommand{\pnode}[1]{\require{enclose}\enclose{circle}{\kern.1em {#1} \kern.1em}} \newcommand{\ponode}[1]{\require{enclose}\enclose{box}[background=lightgray]{{#1}}} \newcommand{\pnodesp}[1]{\require{enclose}\enclose{circle}{~{#1}~}} \newcommand{\purp}[1]{\color{purple}{#1}} \newcommand{\sign}{\text{Sign}} \newcommand{\spacecap}{\; \cap \;} \newcommand{\spacewedge}{\; \wedge \;} \newcommand{\tails}{\outcome{tails}} \newcommand{\Var}[1]{\text{Var}[#1]} \newcommand{\bigVar}[1]{\text{Var}\mkern-4mu \left[ #1 \right]} \]
Expectations = Weighted Means
- We already know how to find the (unweighted) mean of a list of numbers:
\[ \begin{align*} \begin{array}{|p{1cm}||p{1cm}|p{1cm}|p{1cm}|}\hline X & \orange{4} & \orange{10} & \orange{8} \\\hline\end{array} \implies \overline{X} &= \frac{\orange{4} + \orange{10} + \orange{8}}{\purp{3}} = \purp{\left(\frac{1}{3}\right)} \cdot \orange{4} + \purp{\left( \frac{1}{3} \right)} \cdot \orange{10} + \purp{\left( \frac{1}{3} \right)} \cdot \orange{8} \\ &= \frac{22}{3} \approx 7.33 \end{align*} \]
- Discrete distributions: just lists of numbers and their probability of occurring!
\[ \begin{align*} \begin{array}{|p{1cm}|p{1cm}|p{1cm}|p{1cm}|}\hline X & \orange{4} & \orange{10} & \orange{8} \\\hline \Pr(X) & \purp{0.01} & \purp{0.01} & \purp{0.98}\\\hline\end{array} \implies \overline{X} &= \purp{\left( \frac{1}{100} \right)} \cdot \orange{4} + \purp{\left( \frac{1}{100} \right)} \cdot \orange{10} + \purp{\left( \frac{98}{100} \right)} \cdot \orange{8} \\ &= \left.\frac{798}{100}\right.^{1} \approx 7.98 \end{align*} \]
- It will be helpful for later/life as a data scientist to notice that this is exactly \(\frac{4 + 10 + \overbrace{8 + \cdots + 8}^{98\text{ times}}}{100}\). That is: weighted mean = normal mean where numbers are repeated proportionally to their probabilities. (See Laplace smoothing!).
Different Types of “Averages”
- (This will seem like overkill now, but will help us later!)
- To avoid confusion, we denote the “regular” (arithmetic) mean function as \(M_1(\cdot)\)
- If \(V = \{v_1, \ldots, v_n\}\), \(M_1(V) \definedas \frac{v_1+\cdots+v_n}{n}\).
- Then \(\overline{V}\) will denote the number which results from applying \(M_1\) to the set \(V\).
- Other common functions which get called “averages” in Machine Learning: median, harmonic mean (\(M_{-1}\)), geometric mean (\(M_0\)), the hadamard product \(\odot\), etc.—pop up surprisingly often in Data Science/Machine Learning!
- The things we’re averaging also take on weird forms: bits, logical predicates, vectors, tensors (Hence Google’s ML platform, TensorFlow), …
For what these subscripts (\(M_{-1}\), \(M_0\), \(M_1\)) mean, and more on the Hadamard product and its importance to Machine Learning, see Section 4.1
Definition
- For a discrete RV \(X\):
\[ \expect{X} = \sum_{x \in \mathcal{R}_X}x P(x) \]
- For a continuous RV \(X\):
\[ \expect{X} = \int_{-\infty}^{\infty}xf(x)dx \]
Remember that \(\mathcal{R}_X\) is the support of the random variable \(X\). If \(X\) is discrete, this is just \(\mathcal{R}_X = \{x \in \mathbb{R} \given P(X = x) > 0\}\). If \(X\) is continuous, we can almost always* use the similar definition \(\mathcal{R}_X = \{x \in \mathbb{R} \given f_X(x) > 0\}\), remembering that \(f_X(x) \neq P(X = x)\)!!! See Section 4.2 for the scarier definition that works for all continuous RVs.
Important Properties
- For RVs \(X\), \(Y\), and \(a, b \in \mathbb{R}\):
\[ \expect{aX} = a\expect{X} \]
\[ \expect{X + Y} = \expect{X} + \expect{Y} \]
\[ \expect{aX + b} = a\expect{X} + b \]
- LOTUS:
\[ \expect{g(X)} = g(x)f(x)dx \]
- Not Multiplicative:
\[ \expect{X \cdot Y} = \expect{X} \cdot \expect{Y} \iff X \perp Y \]
Really these should be called affine functions, but this property is usually just known as “linearity”, so for the sake of being able to google it I’m calling it “Linear” here as well, for now
Variance: Motivation
- We’ve now got a “measure of central tendency”, the expectation \(\expect{X}\), with some nice properties. We can use it to produce point estimates.
- Now, how do we describe and communicate the spread of the data in a dataset? Similarly, how can we describe our uncertainty about a point estimate?
- Let’s try to develop a function, \(\text{Spread}\), that takes in a set of values and computes how spread out they are
- (Hint: can use arithmetic mean, applied to differences between points rather than points themselves)
First Attempt
- What properties should \(\text{Spread}(\cdot)\) have?
- Should be \(0\) if every data point is identical, then increase as they spread apart
- How about: average difference between each point and the overall (arithmetic) mean? \[ \text{Spread}(X) = M_1(X - \overline{X}) = \frac{(x_1 - \overline{X}) + (x_2 - \overline{X}) + \cdots + (x_n - \overline{X})}{n} \]
Code
library(tidyverse)
library(latex2exp)
N <- 10
x <- seq(1,N)
y <- rnorm(N, 0, 10)
mean_y <- mean(y)
spread <- y - mean_y
df <- tibble(x=x, y=y, spread=spread)
ggplot(df, aes(x=x, y=y)) +
geom_hline(aes(yintercept=mean_y, linetype="dashed"), color="purple", size=g_linesize) +
geom_segment(aes(xend=x, yend=mean_y, color=ifelse(y>0,"Positive","Negative")), size=g_linesize) +
geom_point(size=g_pointsize) +
scale_linetype_manual(element_blank(), values=c("dashed"="dashed"), labels=c("dashed"=unname(TeX(c("$M_1(X)$"))))) +
dsan_theme("half") +
scale_color_manual("Spread", values=c("Positive"=cbPalette[3],"Negative"=cbPalette[6]), labels=c("Positive"="Positive","Negative"="Negative")) +
scale_x_continuous(breaks=seq(0,10,2)) +
#remove_legend_title() +
theme(legend.spacing.y=unit(0.1,"mm")) +
labs(
title=paste0(N, " Randomly-Generated Points, N(0,10)"),
x="Index",
y="Value"
)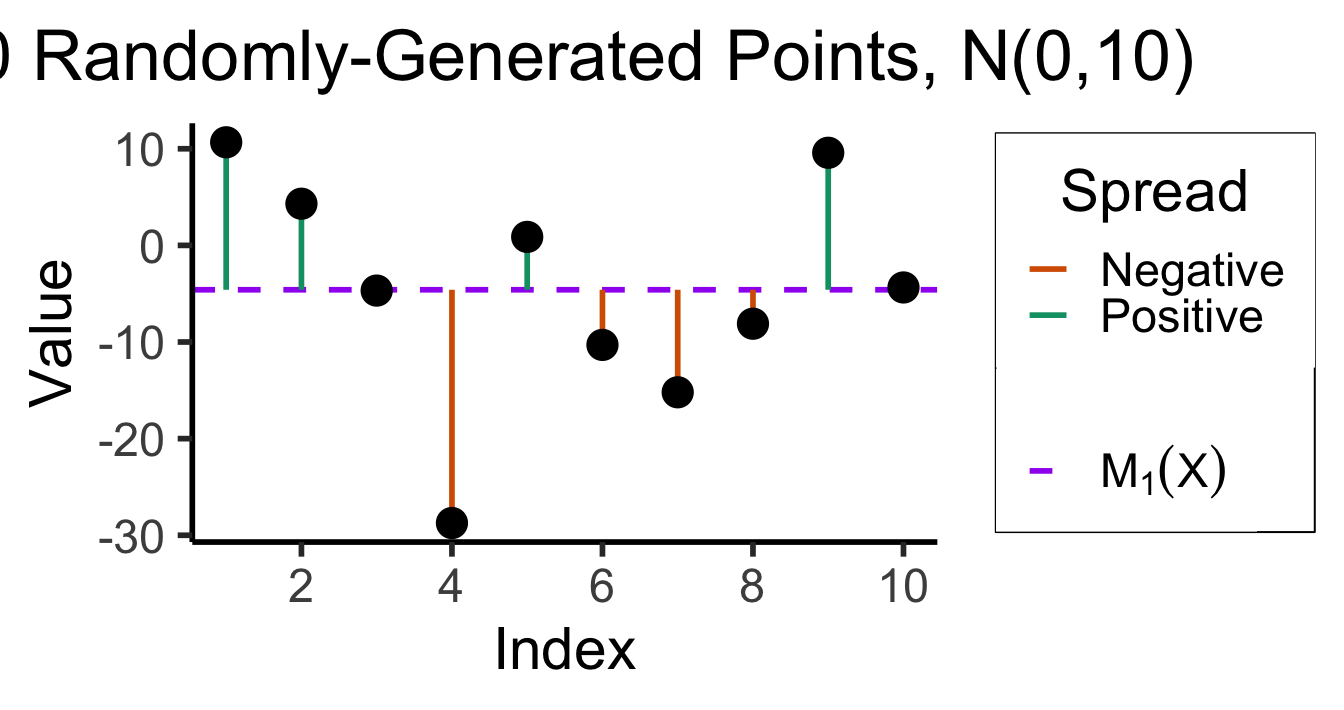
The result? To ten decimal places:
Code
spread_fmt <- sprintf("%0.10f", mean(df$spread))
writeLines(spread_fmt)-0.0000000000😞 What happened?
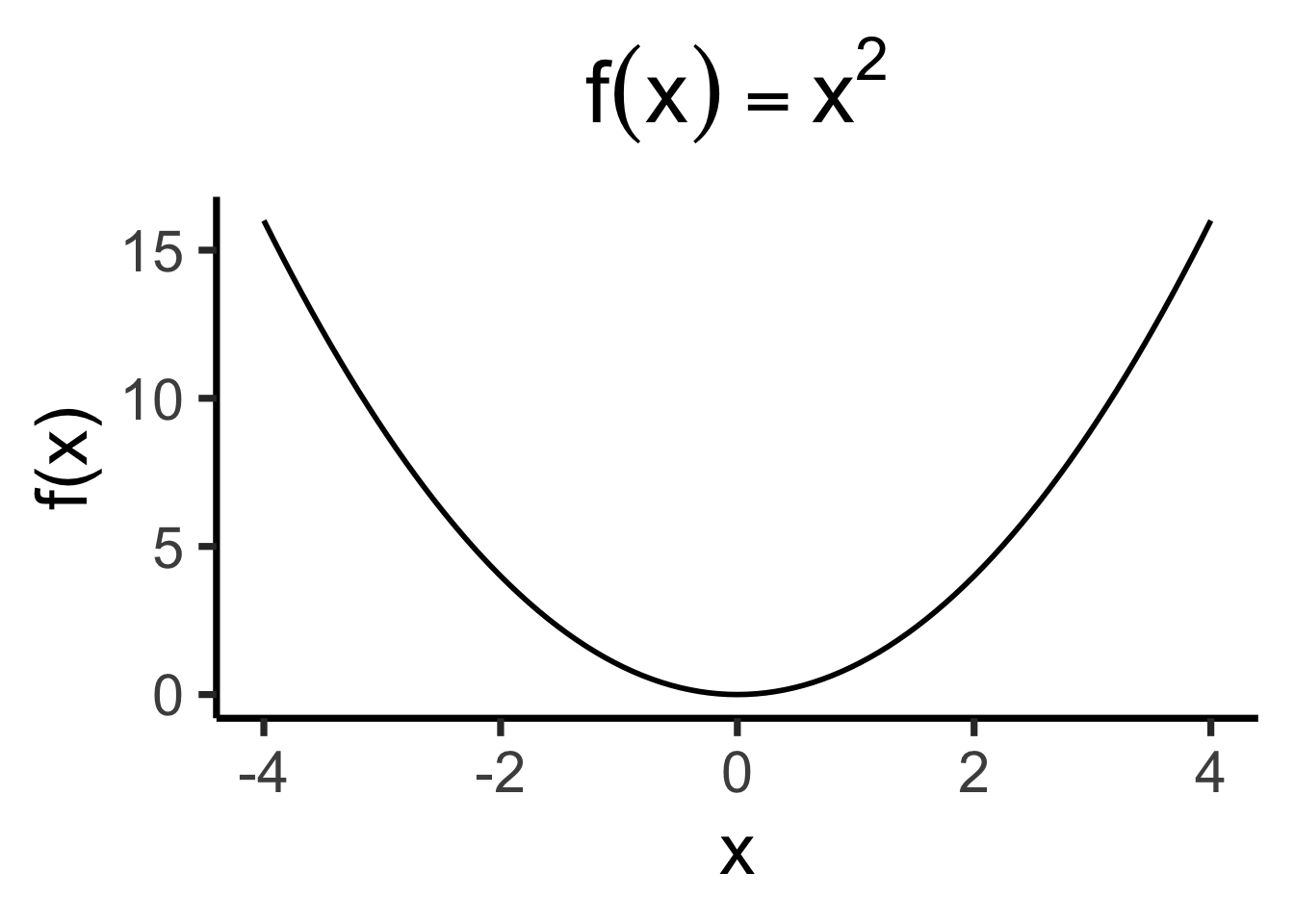
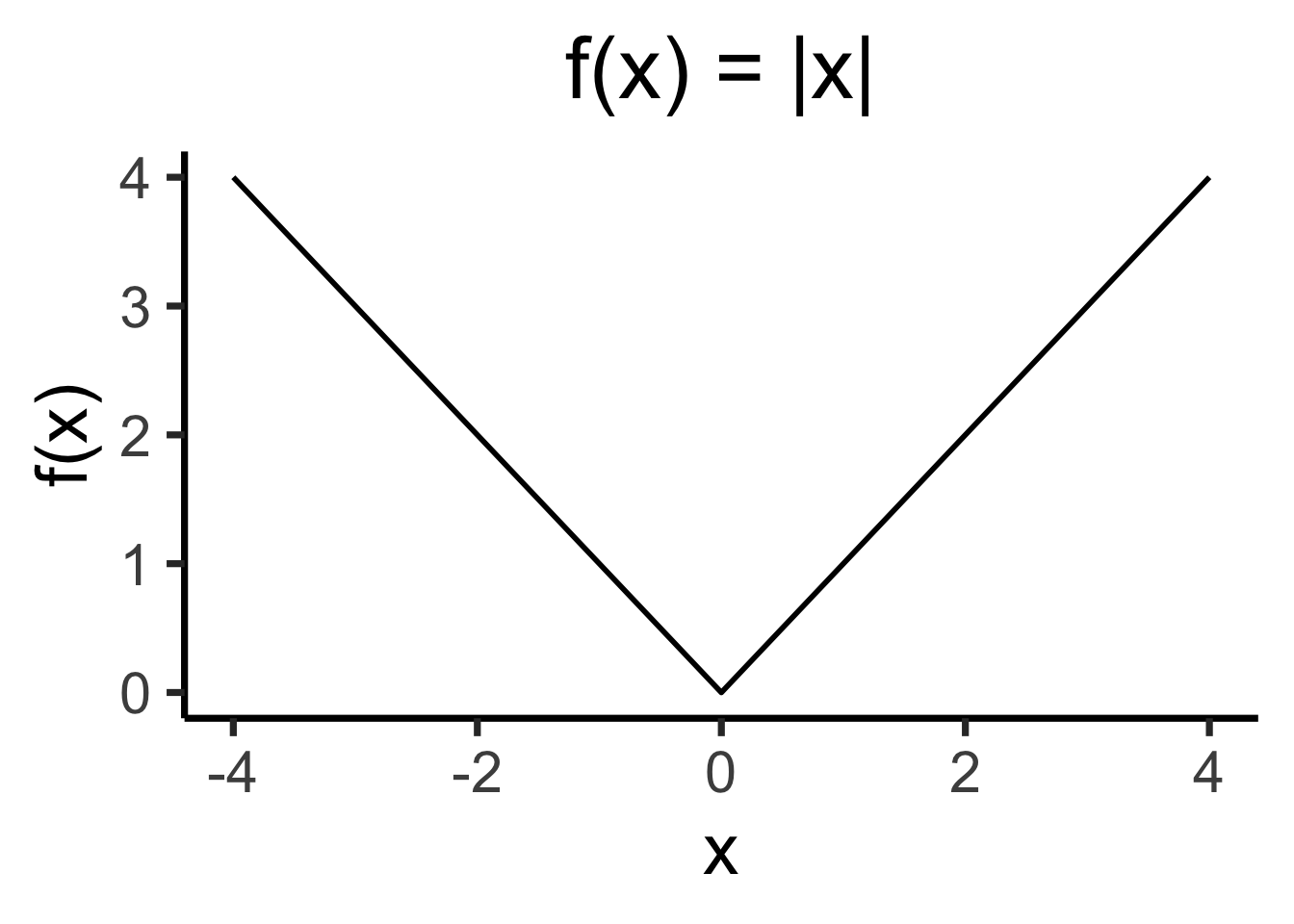
Avoiding Cancellation
- How to avoid positive and negative deviations cancelling out? Two ideas:
- Absolute value \(\left|X - \overline{X}\right|\)
- Squared error \(\left( X - \overline{X} \right)^2\)…
- Ghost of calculus past: which is differentiable everywhere?2
# Could use facet_grid() here, but it doesn't work too nicely with stat_function() :(
library(latex2exp)
x2_exp <- TeX("$f(x) = x^2$")
ggplot(data.frame(x=c(-4,4)), aes(x=x)) +
stat_function(fun=~ .x^2, linewidth = g_linewidth) +
dsan_theme("quarter") +
labs(
title=x2_exp,
y="f(x)"
)
# Could use facet_grid() here, but it doesn't work too nicely with stat_function() :(
ggplot(data.frame(x=c(-4,4)), aes(x=x)) +
stat_function(fun=~ abs(.x), linewidth=g_linewidth) +
dsan_theme("quarter") +
labs(
title="f(x) = |x|",
y="f(x)"
)
We’ve Arrived at Variance!
\[ \Var{X} = \bigexpect{ \left(X - \expect{X}\right)^2 } \]
- And, we can apply what we know about \(\expect{X}\) to derive:
\[ \begin{align*} \Var{X} &= \bigexpect{ \left(X - \expect{X}\right)^2 } = \bigexpect{ X^2 - 2X\expect{X} + \left( \expect{X} \right)^2 } \\ &= \expect{X^2} - \expect{2 X\expect{X}} + \left( \expect{X} \right)^2 \\ &= \expect{X^2} - 2\expect{X}\expect{X} + \left(\expect{X}\right)^2 \\ &= \expect{X^2} - \left( \expect{X} \right)^2 \; \; \green{\small{\text{ (we'll need this in a minute)}}} \end{align*} \]
Why does \(\expect{2X\expect{X}} = 2\expect{X}\expect{X}\)? Remember: \(X\) is an RV, but \(\expect{X}\) is a number!
Standard Deviation
- When we squared the deviations, we lost the units of our datapoints!
- To see spread, but in the same units as the original data, let’s just undo the squaring!
\[ \text{SD}[X] = \sqrt{\Var{X}} \]
- But, computers don’t care about the unit of this measure (just minimizing it). No reason to do this additional step if humans aren’t looking at the results!
Properties of Variance
- Recall that Expectation was an affine function:
\[ \mathbb{E}[aX + b] = a\mathbb{E}[X] + b \]
- Variance has a similar property, but is called homogeneous of degree 2, which means
\[ \Var{aX + b} = a^2\Var{X} \; \underbrace{\phantom{+ b}}_{\mathclap{\text{(Something missing?)}}} \]
Note that since the expected value function is linear, it is also homogeneous, of degree 1, even though the \(b\) term doesn’t “disappear” like it does in the variance equation!
What Happened to the \(b\) Term?
Mathematically:
\[ \begin{align*} \Var{aX + b} \definedas \; &\mathbb{E}[(aX + b - \mathbb{E}[aX + b])^2] \\ \definedalign \; &\expect{(aX \color{orange}{+ b} - a\expect{X} \color{orange}{- b})^2} \\ \definedalign \; &\expect{a^2X^2 - 2a^2\expectsq{X} + a^2\expectsq{X}} \\ \definedalign \; &a^2 \expect{X^2 - \expectsq{X}} = a^2(\expect{X^2} - \expectsq{X})b \\ \definedas \; & a^2\Var{X} \end{align*} \]
What Happened to the \(b\) Term?
- Visually (Assuming \(X \sim \mathcal{N}(0,1)\))
pdf_alpha <- 0.333
const_variance <- 0.25
dnorm_center <- function(x) dnorm(x, 0, const_variance)
dnorm_p1 <- function(x) dnorm(x, 1, const_variance)
dnorm_m3 <- function(x) dnorm(x, -3, const_variance)
ggplot(data.frame(x = c(-4, 2)), aes(x = x)) +
# X - 3
stat_function(aes(color=cbPalette[1]), fun = dnorm_m3, size=g_linesize) +
geom_area(stat = "function", fun = dnorm_m3, fill = cbPalette[3], xlim = c(-4, 2), alpha=pdf_alpha) +
# X + 1
stat_function(aes(color=cbPalette[2]), fun = dnorm_p1, size=g_linesize) +
geom_area(stat = "function", fun = dnorm_p1, fill = cbPalette[2], xlim = c(-4, 2), alpha=pdf_alpha) +
# X
stat_function(aes(color=cbPalette[3]), fun = dnorm_center, size = g_linesize) +
geom_area(stat = "function", fun = dnorm_center, fill = cbPalette[1], xlim = c(-4, 2), alpha=pdf_alpha) +
# Scales
scale_color_manual("RV", values=c(cbPalette[1], cbPalette[2], cbPalette[3]), labels=c("X", "X + 1", "X - 3")) +
geom_segment(x=0, y=0, xend=0, yend=dnorm_center(0), size = g_linesize, color=cbPalette[1]) +
geom_segment(x=1, y=0, xend=1, yend=dnorm_p1(1), size = g_linesize, color=cbPalette[2]) +
geom_segment(x=-3, y=0, xend=-3, yend=dnorm_m3(-3), size = g_linesize, color=cbPalette[3]) +
dsan_theme("quarter") +
theme(
title = element_text(size=20)
) +
labs(
title = "Normal Distributions with Shifted Means",
y = "f(x)"
)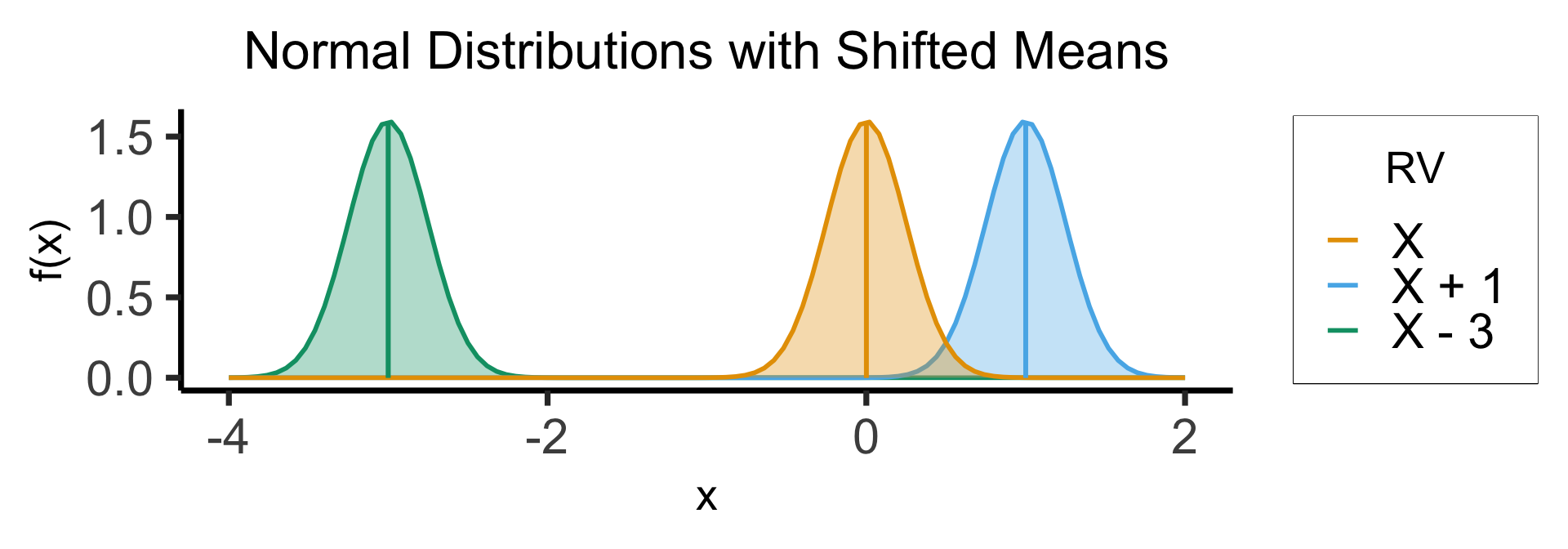
\[ \begin{align*} \expect{{\color{lightblue}X + 1}} = \expect{{\color{orange}X}} + 1, \; \; \Var{{\color{lightblue}X + 1}} = \Var{{\color{orange}X}} \\ \expect{{\color{green}X - 3}} = \expect{{\color{orange}X}} - 3, \; \; \Var{{\color{green}X - 3}} = \Var{{\color{orange}X}} \end{align*} \]
Generalizing Expectation/Variance: The Moment-Generating Function (MGF)
Generalizing Expectation and Variance
- It turns out that, expectation and variance are just two “levels” of a hierarchy of information about a distribution!
- In calculus: knowing \(f(x)\) is sufficient information for us to subsequently figure out \(f'(x)\), \(f''(x)\), …
- In probability/statistics: knowing \(M_X(t)\) is sufficient information for us to figure out \(\expect{X}\), \(\Var{X}\), …
Not a Metaphor!
- This calculus \(\leftrightarrow\) statistics connection is not a metaphor: differentiating \(M_X(t)\) literally gives us \(\expect{X}\), \(\Var{X}\), …
- Let’s look at MGF for \(X \sim \text{Bern}(\param{p})\), and try to derive \(\expect{X}\)3.
\[ \begin{align*} M_X(t) &= (1 - p) + pe^t \\ M'_X(t) &= pe^t,\text{ and }\expect{X} = M'_X(0) = \green{p} \; ✅ \end{align*} \]
- \(\Var{X}\)?
\[ \begin{align*} M''_{X}(t) &= pe^t,\text{ and }\expect{X^2} = M''_X(0) = p \\ \Var{X} &\definedas{} \expect{X^2} - (\expect{X})^2 = p - p^2 = \green{p(1-p)} \; ✅ \end{align*} \]
MGF in Econometrics
In case it doesn’t load: (Hansen 1982) has 17,253 citations as of 2023-05-21
BEWARE ☠️
As we saw last week (the Dreaded Cauchy Distribution):
- Not all random variables have moment-generating functions.
- Worse yet, not all random variables have well-defined variances
- Worse yet, not all random variables have well-defined means
- (This happens in non-contrived cases!)
Moving Beyond One RV
Multivariate Distributions (W02)
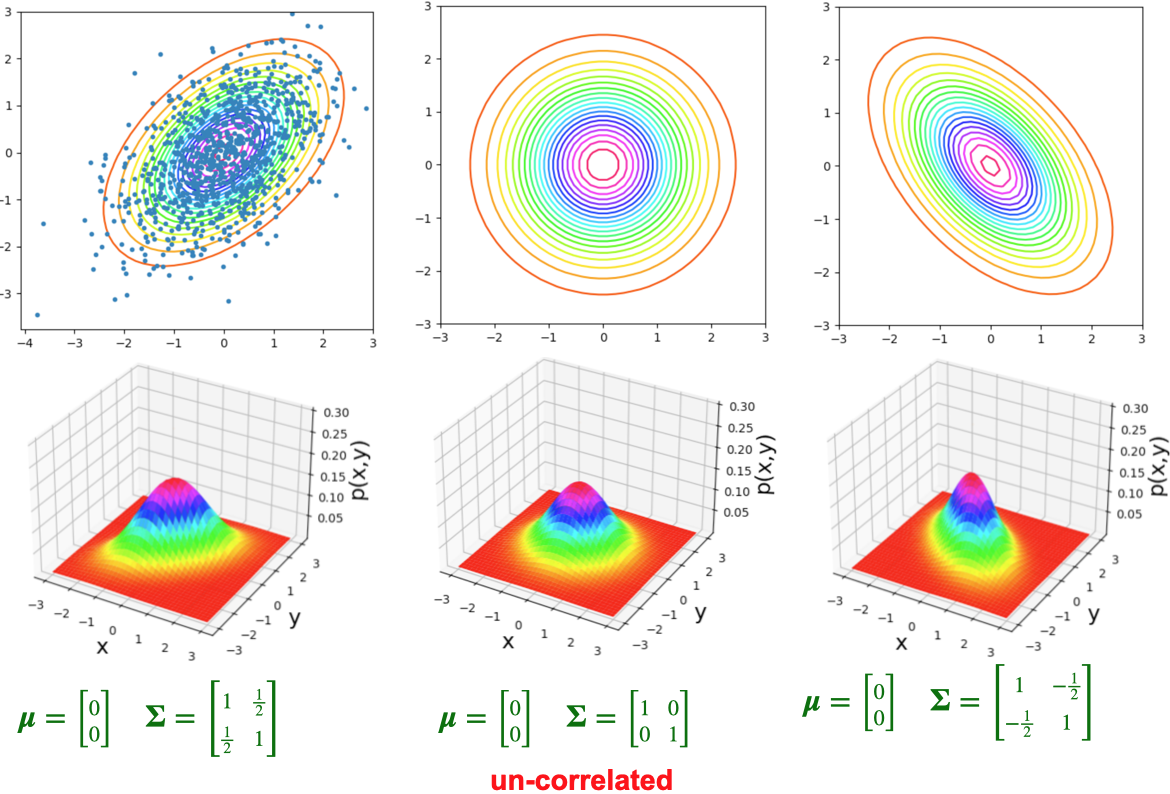
- The bivariate normal distribution represents the distribution of two normally-distributed RVs \(\mathbf{X} = [\begin{smallmatrix} X_1 & X_2\end{smallmatrix}]\), which may or may not be correlated:
\[ \mathbf{X} = \begin{bmatrix}X_1 \\ X_2\end{bmatrix}, \; \boldsymbol{\mu} = %\begin{bmatrix}\mu_1 \\ \mu_2\end{bmatrix} \begin{bmatrix}\smash{\overbrace{\mu_1}^{\mathbb{E}[X_1]}} \\ \smash{\underbrace{\mu_2}_{\mathbb{E}[X_2]}}\end{bmatrix} , \; \mathbf{\Sigma} = \begin{bmatrix}\smash{\overbrace{\sigma_1^2}^{\text{Var}[X_1]}} & \smash{\overbrace{\rho\sigma_1\sigma_2}^{\text{Cov}[X_1,X_2]}} \\ \smash{\underbrace{\rho\sigma_2\sigma_1}_{\text{Cov}[X_2,X_1]}} & \smash{\underbrace{\sigma_2^2}_{\text{Var}[X_2]}}\end{bmatrix} % \begin{bmatrix}\sigma_1^2 & \rho\sigma_1\sigma_2 \\ \rho\sigma_2\sigma_1 & \sigma_2^2 \end{bmatrix} % = \begin{bmatrix}\text{Var}[X_1] & \text{Cov}[X_1,X_2] \\ \text{Cov}[X_2,X_1] & \text{Var}[X_2] \end{bmatrix} \]
- By squishing all this information intro matrices, we can specify the parameters of multivariate-normally-distributed vectors of RVs similarly to how we specify single-dimensional normally-distributed RVs:
\[ \begin{align*} \overbrace{X}^{\mathclap{\text{scalar}}} &\sim \mathcal{N}\phantom{_k}(\overbrace{\mu}^{\text{scalar}}, \overbrace{\sigma}^{\text{scalar}}) \tag{Univariate} \\ \underbrace{\mathbf{X}}_{\text{vector}} &\sim \boldsymbol{\mathcal{N}}_k(\smash{\underbrace{\boldsymbol{\mu}}_{\text{vector}}}, \underbrace{\mathbf{\Sigma}}_{\text{matrix}}) \tag{Multivariate} \end{align*} \]
Visualizing 3D Distributions: Projection
- Since most of our intuitions about plots come from 2D plots, it is extremely useful to be able to take a 3D plot like this and imagine “projecting” it down into different 2D plots:

Visualizing 3D Distributions: Contours
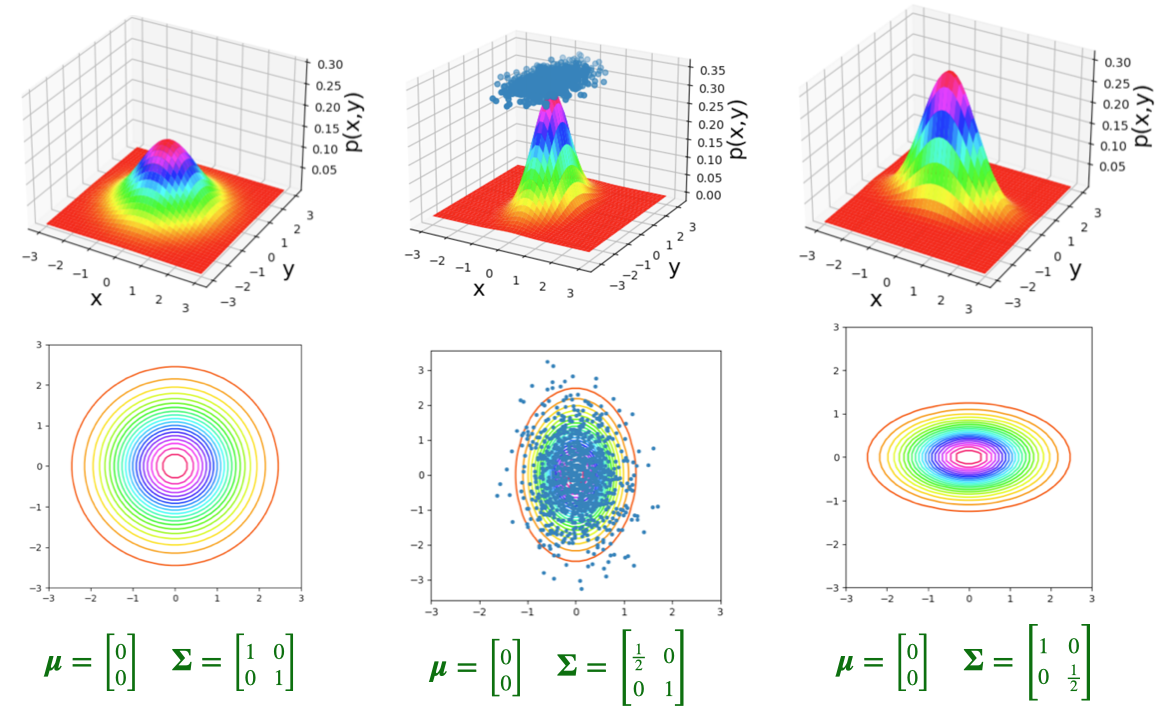
Visualizing 3D Distributions: Contours
Bivariate Distributions
DeGroot and Schervish (2013, 118) | DSPS Sec. 3.4
- We generalize the concept of the distribution of a random variable to the joint distribution of two random variables.
- In doing so, we introduce the joint pmf for two discrete random variables, the joint pdf for two continuous variables, and the joint CDF for any two random variables.
References
DeGroot, Morris H., and Mark J. Schervish. 2013. Probability and Statistics. Pearson Education.
Hansen, Lars Peter. 1982. “Large Sample Properties of Generalized Method of Moments Estimators.” Econometrica: Journal of the Econometric Society, 1029–54.
Appendix Slides
Appendix I: The Hadamard Product
- Used in nearly all neural NLP algorithms, as basis of LSTM (see LSTM equations on right)
- Subscripts on harmonic mean \(M_{-1}\), geometric mean \(M_0\), and arithmetic mean \(M_1\) come from the definition of the generalized mean:
\[ M_p(V) = \left( \frac{1}{n} \sum_{i=1}^n v_i^p \right)^{1/p} \]
\[ \begin{align*} f_t &= \sigma(W_f [h_{t - 1}, x_t] + b_f) \\ i_t &= \sigma(W_i [h_{t - 1}, x_t] + b_i) \\ \tilde{C}_t &= \tanh(W_C [h_{t - 1}, x_t] + b_C) \\ C_t &= f_t \odot C_{t - 1} + i_t \odot \tilde{C}_t \\ o_t &= \sigma(W_o [h_{t - 1}, x_t] + b_o) \\ h_t &= o_t \odot \tanh(C_t) \\ \hat{y} &= \text{softmax}(W_y h_t + b_y) \end{align*} \]
- If you’re a dork like me, you can read about generalized means, Fréchet means, or Stata’s
trimmeanfunction, all of which bring together seemingly-unrelated functions used throughout Machine Learning!
Appendix II: Continuous RV Support
In most cases, for continuous RVs, the definition
\[ \mathcal{R}_X = \{x \in \mathsf{Domain}(f_X) \given f_X(x) > 0\} \]
works fine. But, to fully capture all possible continuous RVs, the following formal definition is necessary:
\[ \mathcal{R}_X = \left\{x \in \mathbb{R} \given \forall r > 0 \left[ f_X(B(x,r)) > 0 \right] \right\}, \]
where \(B(x,r)\) is a “band”4 around \(x\) with radius \(r\).
For a full explanation, see this StackExchange discussion.
Footnotes
Mathematically, it’s important to call \(aX + b\) an “affine transformation”, not a linear transformation. In practice, everyone calls this “linear”, so I try to use both (for easy Googling!). The reason it matters will come up when we discuss Variance!↩︎
For why differentiability matters a lot for modern Machine Learning, see the Backpropagation algorithm.↩︎
Recall that, for a Bernoulli-distributed random variable \(X\), \(\expect{X} = p\)↩︎
In one dimension, this would be an interval; in two dimensions, a circle; in three dimensions, a sphere; etc.↩︎