Code
library(tidyverse)
library(latex2exp)
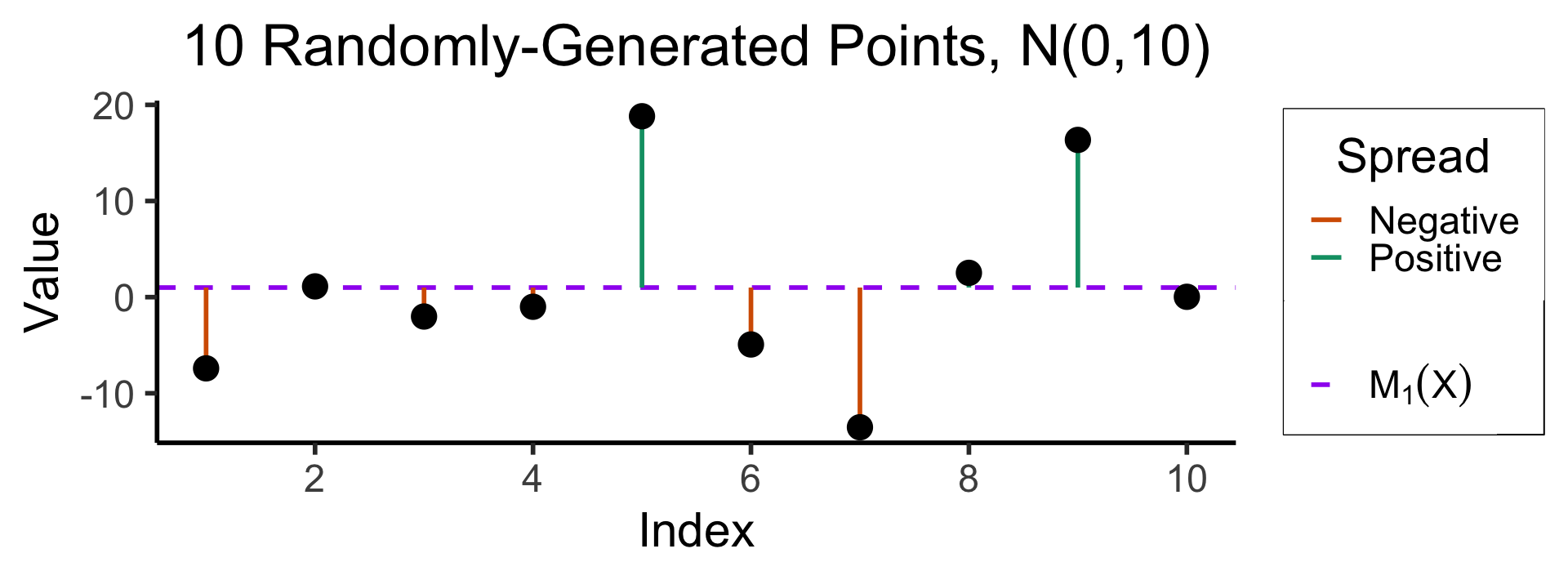
N <- 10
x <- seq(1,N)
y <- rnorm(N, 0, 10)
mean_y <- mean(y)
spread <- y - mean_y
df <- tibble(x=x, y=y, spread=spread)
ggplot(df, aes(x=x, y=y)) +
geom_hline(aes(yintercept=mean_y, linetype="dashed"), color="purple", size=g_linesize) +
geom_segment(aes(xend=x, yend=mean_y, color=ifelse(y>0,"Positive","Negative")), size=g_linesize) +
geom_point(size=g_pointsize) +
scale_linetype_manual(element_blank(), values=c("dashed"="dashed"), labels=c("dashed"=unname(TeX(c("$M_1(X)$"))))) +
dsan_theme("half") +
scale_color_manual("Spread", values=c("Positive"=cbPalette[3],"Negative"=cbPalette[6]), labels=c("Positive"="Positive","Negative"="Negative")) +
scale_x_continuous(breaks=seq(0,10,2)) +
#remove_legend_title() +
theme(legend.spacing.y=unit(0.1,"mm")) +
labs(
title=paste0(N, " Randomly-Generated Points, N(0,10)"),
x="Index",
y="Value"
)