source("../dsan-globals/_globals.r")Week 5: Data Cleaning
DSAN 5000: Data Science and Analytics
Class Sessions
Week 04 Recap
- Dataset Types / Formats
- Web Scraping
- APIs
Data Formats: Network Data
- Network data form two tabular datasets: one for nodes and one for edges
- Ex: Network on left could be represented via pair of tabular datasets on right
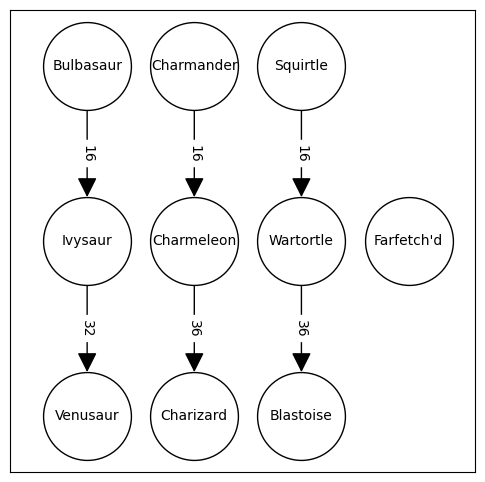
| node_id | label |
|---|---|
| 1 | Bulbasaur |
| 2 | Ivysaur |
| \(\vdots\) | \(\vdots\) |
| 9 | Blastoise |
| edge_id | source | target | weight |
|---|---|---|---|
| 0 | 1 | 2 | 16 |
| 1 | 2 | 3 | 32 |
| 2 | 4 | 5 | 16 |
| 3 | 5 | 6 | 36 |
| 4 | 7 | 8 | 16 |
| 5 | 8 | 9 | 36 |
Web Scraping with requests and BeautifulSoup
| What I Want To Do | Python Code I Can Use |
|---|---|
| Send an HTTP GET request | response = requests.get(url) |
| Send an HTTP POST request | response = requests.post(url, post_data) |
| Get just the plain HTML code (excluding headers, JS) returned by the request | html_str = response.text |
| Parse a string containing HTML code | soup = BeautifulSoup(html_str, 'html.parser') |
Get contents of all <xyz> tags in the parsed HTML |
xyz_elts = soup.find_all('xyz') |
Get contents of the first <xyz> tag in the parsed HTML |
xyz_elt = soup.find('xyz') |
| Get just the text (without formatting or tag info) contained in a given element | xyz_elt.text |
APIs Recap
- Keep in mind the distinction between your entire application and the API endpoints you want to make available to other developers!
| Application | Should Be Endpoints | Shouldn’t Be Endpoints |
|---|---|---|
| Voting Machine | cast_vote() (End User), get_vote_totals() (Admin) |
get_vote(name), get_previous_vote() |
| Gaming Platform | get_points() (Anyone), add_points(), remove_points() (Game Companies) |
set_points() |
| Thermometer | view_temperature() |
release_mercury() |
| Canvas App for Georgetown | view_grades() (different for Students and Teachers) |
SQL Statement for Storing and Retrieving Grades in Georgetown DB |
APIs Part 2
REST vs. SOAP vs. GraphQL
- SOAP: Standard Object Access Protocol: Operates using a stricter schema (data must have this form, must include these keys, etc.), XML only
- REST (REpresentational State Transfer): Uses standard HTTP, wide range of formats
- GraphQL (Graph Query Language): Rather than exposing several endpoints, each performing a single function, GraphQL exposes a single endpoint for queries (so that the server then goes and figures out how to satisfy these queries)
get_users and get_friends) to derive answer to “Is User 5 friends with Pitbull?”
What Should I Include in My API?
Key Principle: CRUD
- Create: Place a new record in some table(s)
- Read: Get data for all (or subset of) records
- Update*: Locate record, change its value(s)
- “Upsert”: Update if already exists, otherwise create
- Delete: Remove record from some table(s)
Cleaning Tabular Data
The Unexpected Pitfalls
- You find the perfect dataset for your project, only to open it and find…
Data Cleaning
- The most undervalued skill in data science!
- Regardless of industry, absurd variety of data formats1

The Data Cleaning Toolbox
- Text Editors
- Regular Expressions
- Conversion Tools
- HTML Parsers
Text Editors
- “Broken” data can often be fixed by manually examining it in a text editor!
my_data.csv
id,var_A,var_B,var_C\n
1,val_1A,val_1B,val_1C\r\n
2,val_2A,val_2B,val_2C\n
3,val_3A,val_3B,val_3C\nlibrary(readr)
data <- read_csv("assets/my_data.csv")Rows: 3 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (4): index, var_1, var_2, var_3
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.data| index | var_1 | var_2 | var_3 |
|---|---|---|---|
| A | val_A1 | val_A2 | val_A3 |
| B | val_B1 | val_B2 | val_B3 |
| C | val_C1 | val_C2 | val_C3 |
Regular Expressions
- Language for turning unstructured data into structured data
- In Computer Science, a whole course, if not two…
- tldr: a regular expression, or a RegEx string, represents a machine that either accepts or rejects input strings
| RegEx | [A-Za-z0-9]+ | @ | [A-Za-z0-9.-]+ | \. | (com|org|edu) | Result: |
| String A | jj1088 | @ | georgetown | . | edu | Accept ✅ |
| String B | spammer | @ | fakesite!! | . | coolio | Reject ❌ |
Regular Expressions: Intuition
- The guiding principle: think of the types of strings you want to match:
- What kinds of characters do they contain? (and, what kinds of characters should they not contain?)
- What is the pattern in which these characters appear: is there a character limit? Which characters/patterns are optional, which are required?
- You can then use the RegEx syntax to encode the answers to these questions!
RegEx Syntax: Single Characters
z: Match lowercasez, a single timezz: Match two lowercasezs in a rowz{n}: Matchnlowercasezs in a row[abc]: Matcha,b, orc, a single time[A-Z]: Match one uppercase letter[0-9]: Match one numeric digit[A-Za-z0-9]: Match a single alphanumeric character[A-Za-z0-9]{n}: Matchnalphanumeric characters
RegEx Syntax: Repeating Patterns
z*: Match lowercasezzero or more timesz+: Match lowercasezone or more timesz?: Match zero or one lowercasezs
z* |
z+ |
z? |
z{3} |
|
|---|---|---|---|---|
"" |
✅ | ✅ | ||
"z" |
✅ | ✅ | ✅ | |
"zzz" |
✅ | ✅ | ✅ |
Example: US Phone Numbers
- Area code sometimes surrounded by parentheses:
- 202-687-1587 and (202) 687-1587 both valid!
- Which repeating pattern syntax (from the previous slide) helps us here?
| RegEx | [(]? | [0-9]{3} | [)]? | [ -] | [0-9]{3}-[0-9]{4} | Result |
"202-687-1587" |
\(\varepsilon\) | 202 | \(\varepsilon\) | - | 687-1587 | Accept ✅ |
"(202) 687-1587" |
( | 202 | ) | 687-1587 | Accept ✅ | |
"2020687-1587" |
\(\varepsilon\) | 202 | \(\varepsilon\) | 0 | 687-1587 | Reject ❌ |
Building and Testing RegEx Strings
Recall: Tidy Data
| Var1 | Var 2 | |
|---|---|---|
| Obs 1 | Val 1 | Val 2 |
| Obs 2 | Val 3 | Val 4 |
Code
library(tidyverse)Code
table1── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ stringr 1.5.1
✔ forcats 1.0.0 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors| country | year | cases | population |
|---|---|---|---|
| Afghanistan | 1999 | 745 | 19987071 |
| Afghanistan | 2000 | 2666 | 20595360 |
| Brazil | 1999 | 37737 | 172006362 |
| Brazil | 2000 | 80488 | 174504898 |
| China | 1999 | 212258 | 1272915272 |
| China | 2000 | 213766 | 1280428583 |
Code
table2 |> head(6)| country | year | type | count |
|---|---|---|---|
| Afghanistan | 1999 | cases | 745 |
| Afghanistan | 1999 | population | 19987071 |
| Afghanistan | 2000 | cases | 2666 |
| Afghanistan | 2000 | population | 20595360 |
| Brazil | 1999 | cases | 37737 |
| Brazil | 1999 | population | 172006362 |
How Do We Get Our Data Into Tidy Form?
- R: The Tidyverse
- Python: Pandas + Regular Expressions (lab demo!)
Cleaning Text Data
One of the Scariest Papers of All Time
Text Preprocessing For Unsupervised Learning: Why It Matters, When It Misleads, And What To Do About It (Denny and Spirling 2018) (PDF Link)


The Secret Behind All Text Analysis



| doc_id | text |
texts |
Kékkek |
voice |
|
|---|---|---|---|---|---|
| 0 | 0 | 6 | 0 | 1 | |
| 1 | 0 | 0 | 3 | 1 | |
| 2 | 6 | 0 | 0 | 0 |
| doc_id | text |
kekkek |
voice |
||
|---|---|---|---|---|---|
| 0 | 6 | 0 | 1 | ||
| 1 | 0 | 3 | 1 | ||
| 2 | 6 | 0 | 0 |
Lab Demonstrations
Lab Demo: Data Cleaning in Python
Alternative Lab Demo: Regular Expressions for Data Cleaning
Lab Assignment Overview
References
Denny, Matthew J., and Arthur Spirling. 2018. “Text Preprocessing For Unsupervised Learning: Why It Matters, When It Misleads, And What To Do About It.” Political Analysis 26 (2): 168–89. https://doi.org/10.1017/pan.2017.44.
Immerwahr, Daniel. 2019. How to Hide an Empire: A History of the Greater United States. Farrar, Straus and Giroux.