Recorded votes in legislative settings (roll calls) are often used to recover the underlying preferences of legislators. Political scientists analyze roll call data using the Euclidean spatial voting model: each legislator (\(i = 1, \ldots, n\)) has a preferred policy position (\(x_i\), a point in low-dimensional Euclidean space), and each vote (\(j = 1, \ldots, m\)) amounts to a choice between “Yes” and “No” locations, \(q_j\) and \(Y_j\), respectively. Legislators are assumed to choose on the basis of utility maximization, with one-dimensional utilities.
In these models, the only observed data are votes, and the analyst wants to model those votes as a function of legislator-specific (\(\xi_i\)) and vote-specific (\(\alpha_i\), \(\beta_i\)) parameters.
The vote of legislator \(i\) on roll-call \(j\), \(y_{i,j}\), is a function of the legislator’s ideal point (\(\xi_i\)), the vote’s cutpoint (\(\alpha_j\)), and the vote’s discrimination (\(\beta_j\)):
For each of these: Which types of rotation does it solve?
Fix one element of \(\beta\).
Fix one element of \(\xi\).
Fix one element of \(\alpha\).
Fix two elements of \(\alpha\).
Fix two elements of \(\xi\).
Fix two elements of \(\beta\).
109th Senate
This example models the voting of the 109th U.S. Senate. Votes for the 109th Senate is included in the pscl package:
Code
data("s109", package ="pscl")
The s109 object is not a data frame, so see its documentation for information about its structure.
Code
s109
Description: 109th U.S. Senate
Source: ftp://voteview.com/dtaord/sen109kh.ord
Number of Legislators: 102
Number of Votes: 645
Using the following codes to represent roll call votes:
Yea: 1 2 3
Nay: 4 5 6
Abstentions: 7 8 9
Not In Legislature: 0
Legislator-specific variables:
[1] "state" "icpsrState" "cd" "icpsrLegis" "party"
[6] "partyCode"
Vote-specific variables:
[1] "date" "session" "number" "bill" "question"
[6] "result" "description" "yeatotal" "naytotal"
Detailed information is available via the summary function.
This data includes all roll-call votes, votes in which the responses of the senators are recorded.
For simplicity, the ideal point model uses binary responses, but the s109 data includes multiple codes for responses to roll-calls:
0
not a member
1
Yea
2
Paired Yea
3
Announced Yea
4
Announced Nay
5
Paired Nay
6
Nay
7
Present (some Congresses, also not used some Congresses)
8
Present (some Congresses, also not used some Congresses)
9
Not Voting
In the data processing, we will aggregate the responses into “Yes”, “No”, and missing values.
close: Definition of non-lopsided votes in ; votes with between 35% and 65% yeas in which the parties are likely to whip members.
lopsided: Definition of lopsided votes used in W-NOMINATE and dropped. Votes with less than 2.5% or greater than 97.5% yeas.
`summarise()` has regrouped the output.
ℹ Summaries were computed grouped by .rollcall_id and party.
ℹ Output is grouped by .rollcall_id.
ℹ Use `summarise(.groups = "drop_last")` to silence this message.
ℹ Use `summarise(.by = c(.rollcall_id, party))` for per-operation grouping
(`?dplyr::dplyr_by`) instead.
Identification by Fixing Legislator’s Ideal Points
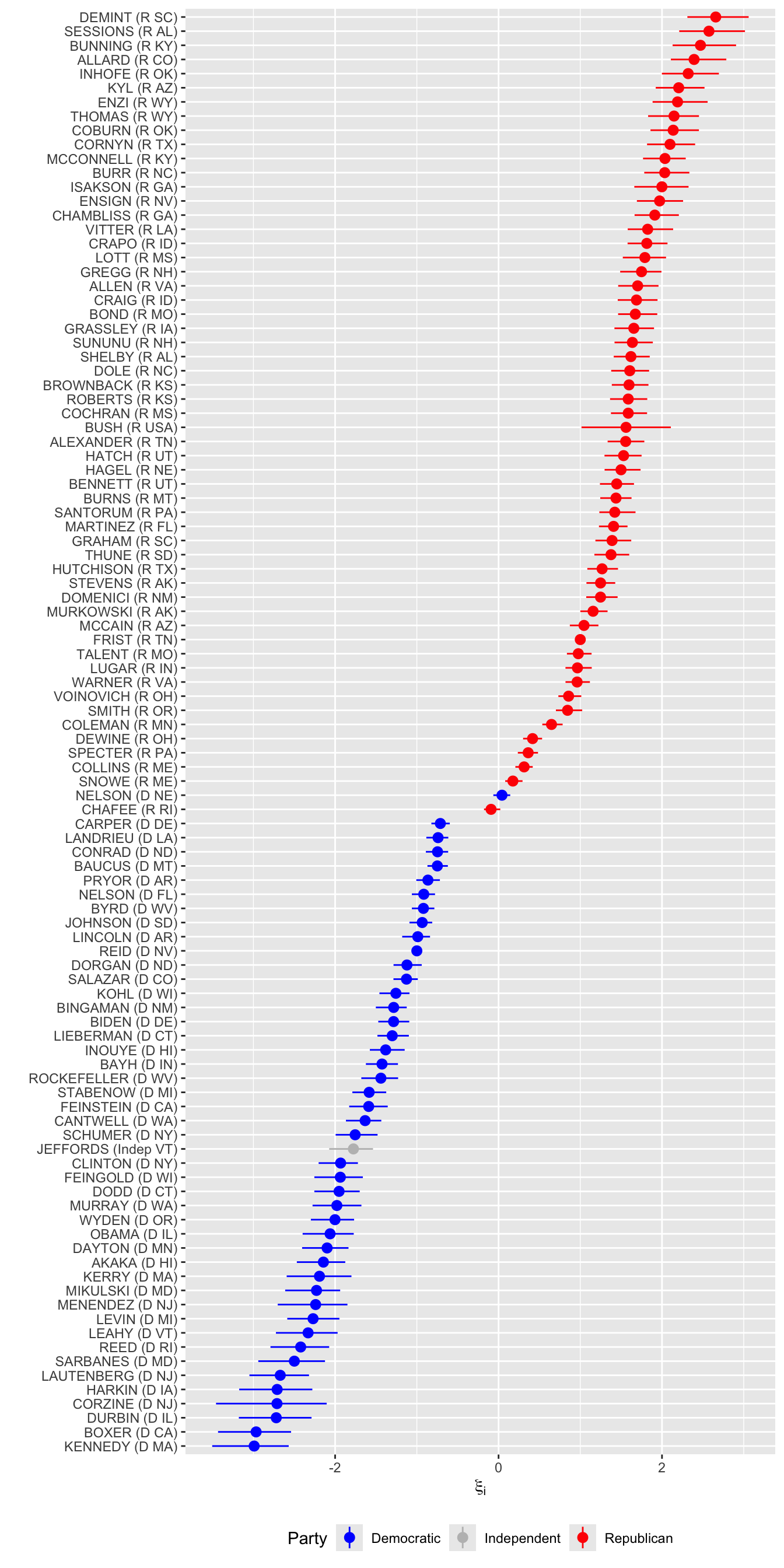
Identification of latent state models can be challenging. The first method for identifying ideal point models is to fix the values of two legislators. These can be arbitrary, but if they are chosen along the ideological dimension of interest it can help the substantive interpretation.
Since we know a priori, or expect, that the primary ideological dimension is Liberal-Conservative (Poole and Rosenthal 2001), I’ll fix the ideal points of the two party leaders in that congress.
In the 109th Congress, the Republican party was the majority party and Bill Frist (Tennessee) was the majority (Republican) leader, and Harry Reid (Nevada) wad the minority (Democratic) leader:
// ideal point model// identification:// - xi ~ hierarchical// - except fixed senatorsdata { // number of individuals int N; // number of items int K; // observed votes int<lower = 0, upper = N * K> Y_obs; int y_idx_leg[Y_obs]; int y_idx_vote[Y_obs]; int y[Y_obs]; // priors // on items real alpha_loc; real<lower = 0.> alpha_scale; real beta_loc; real<lower = 0.> beta_scale; // on legislators int N_xi_obs; int idx_xi_obs[N_xi_obs]; vector[N_xi_obs] xi_obs; int N_xi_param; int idx_xi_param[N_xi_param]; // prior on ideal points real zeta_loc; real<lower = 0.> zeta_scale; real tau_scale;}parameters { // item difficulties vector[K] alpha; // item discrimination vector[K] beta; // unknown ideal points vector[N_xi_param] xi_param; // hyperpriors real<lower = 0.> tau; real<lower = 0.> zeta;}transformed parameters { // create xi from observed and parameter ideal points vector[Y_obs] mu; vector[N] xi; xi[idx_xi_param] = xi_param; xi[idx_xi_obs] = xi_obs; for (i in 1:Y_obs) { mu[i] = alpha[y_idx_vote[i]] + beta[y_idx_vote[i]] * xi[y_idx_leg[i]]; }}model { alpha ~ normal(alpha_loc, alpha_scale); beta ~ normal(beta_loc, beta_scale); xi_param ~ normal(zeta, tau); xi_obs ~ normal(zeta, tau); zeta ~ normal(zeta_loc, zeta_scale); tau ~ cauchy(0., tau_scale); y ~ bernoulli_logit(mu);}generated quantities { vector[Y_obs] log_lik; for (i in 1:Y_obs) { log_lik[i] = bernoulli_logit_lpmf(y[i] | mu[i]); }}
Create a data frame with the fixed values for identification. Additionally, set initial values of ideal points: Republicans at xi = 1, Democrats at xi = -1, and independents at xi = 0. This may help speed up convergence.
Warning: The largest R-hat is NA, indicating chains have not mixed.
Running the chains for more iterations may help. See
https://mc-stan.org/misc/warnings.html#r-hat
Warning: Bulk Effective Samples Size (ESS) is too low, indicating posterior means and medians may be unreliable.
Running the chains for more iterations may help. See
https://mc-stan.org/misc/warnings.html#bulk-ess
Warning: Tail Effective Samples Size (ESS) is too low, indicating posterior variances and tail quantiles may be unreliable.
Running the chains for more iterations may help. See
https://mc-stan.org/misc/warnings.html#tail-ess
Extract the ideal point data:
Code
legislator_summary_1 <-bind_cols( s109_legis_data,as_tibble(summary(legislators_fit_1, par ="xi")$summary )) |>mutate(legislator =fct_reorder(legislator, mean) )
Poole, Keith T., and Howard Rosenthal. 2001. “D-Nominate After 10 Years: A Comparative Update to Congress: A Political-Economic History of Roll-Call Voting.”Legislative Studies Quarterly 26 (1): 5–29. https://doi.org/10.2307/440401.