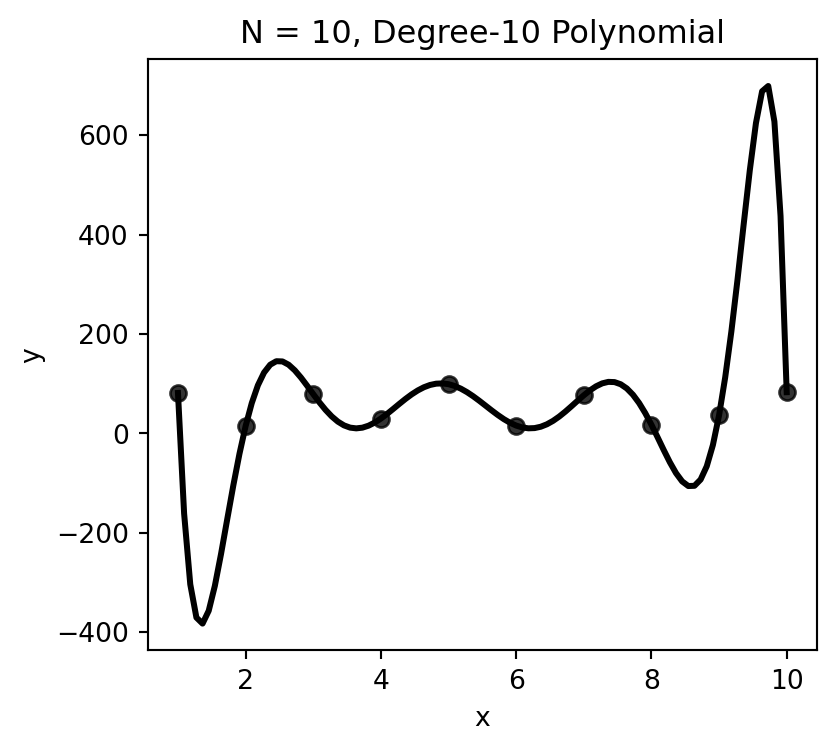
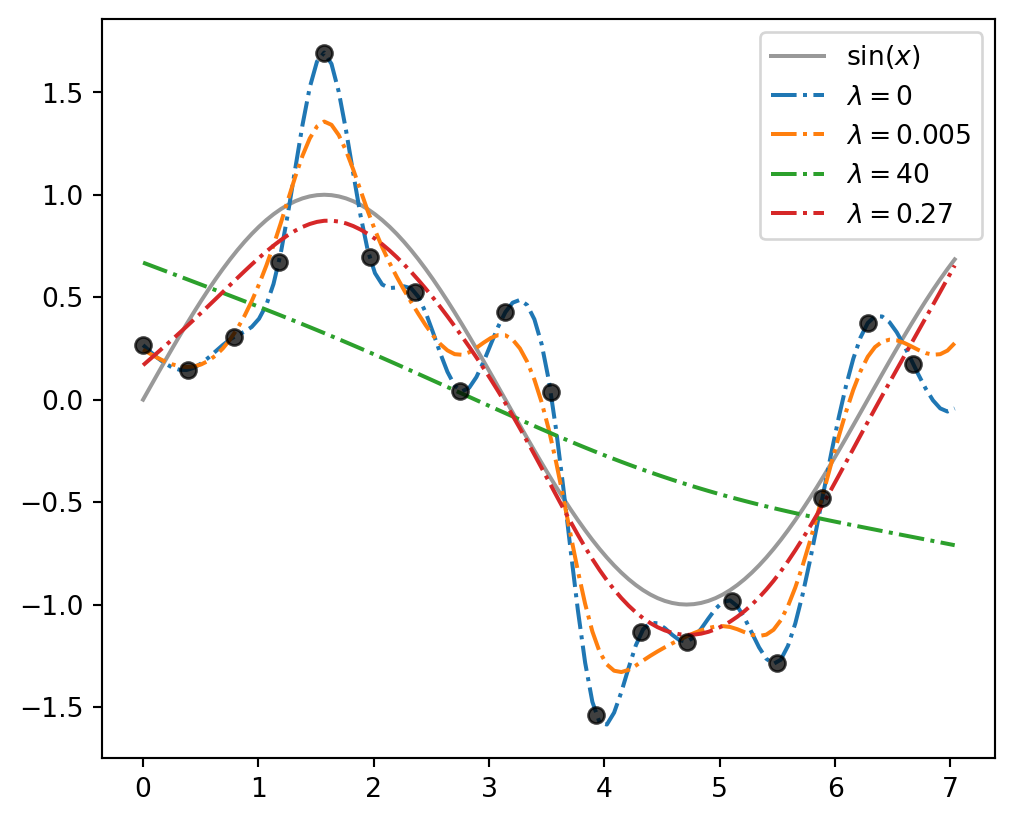
You may have noticed that I usually try not to include proofs in my slides, since they can be scary and 99.9% of the time they don’t add enough to the learning to make that scariness worth it.
In this case though, if you’re feeling courageous about using the extra time you might have during Spring Break to “deep dive” ISLP content, this may be a perfect first proof for you! It has a structure that is used over and over again in statistics, since it’s how we justify calling something “the” optimal solution to some given problem.
In this case, we’d like to prove that Smoothing Splines are the optimal solution to the minimization problem in Equation 1. To accomplish this, we’ll carry out a proof by contradiction:
- We’ll start by assuming that we are wrong, and that there is some other function \(f(x)\) that achieves an even better loss-wigglyness balance than the Smoothing Spline \(g(x)\),
- But then we will derive a logical contradiction from this assumption,
- Which will thus indicate that our original assumption must have been incorrect, and that there is in fact no other function that achieves a better balance than \(g(x)\).
So, let’s start with the assumption, that there is another function \(f(x)\) that achieves a lower penalized loss value than the Smoothing Spline \(g(x)\). Then, since the MSE term can always be minimized to zero by perfectly fitting the \(N\) datapoints, the assumed “advantage” of \(f(x)\) over \(g(x)\) (in terms of the lower overall loss value) must come from the second “wigglyness” term:
\[
\int_{a}^{b}\left[f''(x)\right]^2dx < \int_{a}^{b}\left[g''(x)\right]^2dx
\tag{2}\]
So, define \(h(x) \equiv f(x) - g(x)\). Analyzing this \(h(x)\) will thus let us “capture” whatever differences between \(f(x)\) and \(g(x)\) are allowing \(g(x)\) to have a lower wigglyness. Note that we can rewrite this to obtain
\[
f(x) = g(x) + h(x) \Rightarrow f'(x) = g'(x) + h(x) \Rightarrow f''(x) = g''(x) + h''(x)
\]
Let’s use this last equality to rewrite the left side of Equation 2:
\[
\begin{aligned}
&\int_{a}^{b} \left[ f''(x) \right]^2 dx = \int_{a}^{b}\left[ g''(x) + h''(x)\right]^2 dx \\
&= \int_{a}^{b}\left[ g''(x) \right]^2 + \int_{a}^{b}\left[ h''(x) \right]^2 + 2\int_{a}^{b}g''(x)h''(x)dx
\end{aligned}
\tag{3}\]
That last term, with the 2 in front of it, is interestingly different from what we’ve seen up to now, since it matches the formula for integration by parts that you may have learned in a calculus class! I remember this method for solving integrals in my head as just \(\int_{a}^{b} udv = \left[ uv \right]_{a}^{b} - \int_{a}^{b} vdu\), but the approach in full detail is:
\[
\int_{a}^{b}u(x)v'(x)dx = u(b)v(b) - u(a)v(a) - \int_{a}^{b}u'(x)v(x)dx
\]
If we “match up” the variables here with the variables in the final in Equation 3, we can see the equivalence in form, with \(u(x) \leftrightarrow g''(x)\) and \(v(x) \leftrightarrow h'(x)\). Thus we get an “integration by parts” rewriting of this term (dropping the 2 in front, since it won’t affect the result, as you’ll see below) as:
\[
\int_{a}^{b}g''(x)h''(x)dx = g''(b)h'(b) - g''(a)h'(a) - \int_{a}^{b}g'''(x)h'(x)dx
\]
But, because \(g(x)\) is a natural spline, it is linear at the endpoints of the domain \(a\) and \(b\), meaning that its second derivative \(g''(x)\) at these two points is zero (the second derivative of any line \(mx + b\) is zero), so this simplifies to
\[
\int_{a}^{b}g''(x)h''(x)dx = -\int_{a}^{b}g'''(x)h'(x)dx
\]
Now let’s look at the integral on the right side (without the minus sign, since it won’t affect the result, as you’ll see below), and consider chopping it into pieces based exactly on our knot points:
\[
\begin{aligned}
&\int_{a}^{b}g'''(x)h'(x)dx \\
&= \int_{a}^{\xi_1}g'''(x)h'(x)dx + \sum_{i=1}^{n-1}\int_{\xi_i}^{\xi_{i+1}}g'''(x)h'(x)dx + \int_{\xi_n}^{b}g'''(x)h'(x)dx
\end{aligned}
\]
Once again, because \(g(x)\) is a natural spline, it is linear at the two end pieces, so that the first and last terms here are both zero (since the third derivative of any line \(mx + b\) is zero):
\[
\int_{a}^{b}g'''(x)h'(x)dx = \sum_{i=1}^{n-1}\int_{\xi_i}^{\xi_{i+1}}g'''(x)h'(x)dx
\]
Then, since we defined \(g(x)\) as a natural cubic spline, within each piece of the domain \([\xi_i, \xi_{i+1}]\) the \(g'''(x)\) term in the integral is some constant, which we’ll label using \(c_i\): \(c_1\) will be the constant third derivative of \(g\) between \(\xi_1\) and \(\xi_2\), \(c_2\) will be the constant third derivative of \(g\) between \(\xi_2\) and \(\xi_3\), and so on:
\[
\int_{a}^{b}g'''(x)h'(x)dx = \sum_{i=1}^{n-1}c_i\int_{\xi_i}^{\xi_{i+1}}h'(x)dx
\]
Rewriting it like this means that we’ve simplified the integral down to just the definite integral of a derivative \(h'(x)\), which we know from calculus is defined to be just the difference between the values of the antiderivative, \(h(x)\), at the two endpoints of the integral:
\[
\int_{a}^{b}g'''(x)h'(x)dx = \sum_{i=1}^{n-1}c_i\left[h(\xi_{i+1}) - h(\xi_i))\right]
\]
But now we’ve hit a “finish line”, finally, since both \(h(\xi_{i+1})\) and \(h(\xi_i)\) are zero! Since \(g(x)\) and \(f(x)\) both perfectly interpolate the points \((x_1,y_1)\) through \((x_n,y_n)\), the difference \(h(x)\) between \(f(x)\) and \(g(x)\) at these points will be exactly zero: \(\int_{a}^{b}g'''(x)h'(x)dx = 0\)
Since we’ve now shown that the term with the 2 in front of it in Equation 3 is exactly 0, this equation simplifies to just
\[
\int_{a}^{b}\left[ f''(x) \right]^2dx = \int_{a}^{b}\left[ g''(x) \right]^2dx + \int_{a}^{b}\left[ h''(x) \right]^2dx
\]
But, if we plug the right hand side of this expression back in for \(\int_{a}^{b}\left[ f''(x) \right]^2dx\) in the inequality Equation 2 that “encoded” our original assumption, we get
\[
\int_{a}^{b}\left[ g''(x) \right]^2dx + \int_{a}^{b}\left[ h''(x) \right]^2dx < \int_{a}^{b}\left[ g''(x) \right]^2dx,
\]
which can be true only if the term \(\int_{a}^{b}\left[ h''(x) \right]^2dx\) is negative… but this term can’t be negative, since it’s just the sum of a bunch of squared values! Hence,
- We have arrived at a contradiction, which means that
- Our original assumption that there is some \(f(x)\) less “wiggly” than the Smoothing Spline \(g(x)\), and thus
- It must be the case that no such \(f(x)\) exists, as we wanted to show.