Week 9: Propensity Scores, Regression Discontinuity, and Causal NLP
DSAN 5650: Causal Inference for Computational Social Science
Summer 2026, Georgetown University
Wednesday, July 15, 2026
Option 1: Modeling Social Phenomena with PGMs

- \(D\): Number of movies
- \(E\): Number of characters in a given movie
- \(W\): Tuples pairing words in the movie descriptions with roles (e.g.,
HEROorVILLAIN)
Option 2: Pushing Towards the Asymptote of Causality
Code
library(tidyverse) |> suppressPackageStartupMessages()
rug_df <- read_csv("assets/rugged_data.csv", show_col_types=FALSE)
# Compute Box-Cox params
bc_params <- car::powerTransform(
object = cbind(
rug_df$rgdppc_2000,
rug_df$rugged
)
)
rug_df <- rug_df |> mutate(
continent = ifelse(cont_africa == 1, "African", "Non-African"),
gdpc_transformed = rgdppc_2000_m ^ bc_params$lambda[1],
rugged_transformed = rugged ^ bc_params$lambda[2],
)
rug_df |> ggplot(aes(
x = rugged_transformed,
y = gdpc_transformed
)) +
geom_text(aes(label=isocode), size=3) +
geom_smooth(method="lm", fullrange=TRUE) +
facet_wrap(~ continent) +
theme_classic() +
theme(
panel.background = ggplot2::element_rect(fill='transparent'),
plot.background = ggplot2::element_rect(fill='transparent', color=NA),
plot.title = element_text(hjust=0.5),
) +
labs(
title="Differential Effects of Ruggedness by Continent",
x="Terrain Ruggedness",
y="Log GDP Per Capita, 2000",
)
Figure 2: Results from Nunn and Puga (2012), where the causal impact of terrain ruggedness on present-day GDP per capita reverses direction when considering African vs. non-African countries!
Recap: Propensity Scores

How Exactly Do We Adjust For \(\hat{\mathtt{e}}(\mathbf{X})\)?
- Simulation example: smoking reduction
Code
library(tidyverse)
library(Rlab)
set.seed(5650)
n <- 250
motiv_vals <- runif(n, 0, 1)
enroll_vals <- ifelse(
motiv_vals < 0.25,
0,
# We know motiv > 0.25
ifelse(
motiv_vals > 0.75,
1,
# We know 0.25 < motiv < 0.75
rbern(n, prob=(motiv_vals - 0.125)*1.5)
)
)
ncigs_vals <- rbinom(n, size=30, prob=0.6-0.2*enroll_vals)
smoke_df <- tibble(
motiv=motiv_vals,
enroll=enroll_vals,
ncigs=ncigs_vals
)
(smoke_mean_df <- smoke_df |> group_by(enroll) |> summarize(mean_ncigs=mean(ncigs)))| enroll | mean_ncigs |
|---|---|
| 0 | 17.88060 |
| 1 | 12.26724 |
Code
| term | estimate |
|---|---|
| (Intercept) | 17.880597 |
| enroll | -5.613356 |

Code
smoke_df |> ggplot(aes(x=enroll, y=ncigs)) +
geom_boxplot(
aes(group=enroll),
width=0.5
) +
geom_smooth(
method='lm',
formula='y ~ x',
se=TRUE
) +
geom_point(
data=smoke_mean_df,
aes(x=enroll, y=mean_ncigs),
size=3
) +
theme_dsan(base_size=24) +
transparent_bg() +
labs(
title="Naïve Estimate of Program Effectiveness",
x="Enrolled?",
y="Cigarettes Per Day",
) +
scale_x_continuous(breaks=c(0, 1))
Inverse Probability-of-Treatment Weighting
Code
eprop_model <- glm(enroll ~ motiv, family='binomial', data=smoke_df)
eprop_preds <- predict(eprop_model, type="response")
smoke_df <- smoke_df |> mutate(pred=eprop_preds)
# Use the preds to compute IPW
smoke_df <- smoke_df |> rowwise() |> mutate(
ipw=ifelse(enroll, 1/pred, 1/(1-pred))
) |> arrange(pred)
#smoke_df
smoke_df |> mutate(enroll=factor(enroll)) |>
ggplot(aes(x=motiv, y=ncigs, color=enroll)) +
geom_point() +
theme_dsan(base_size=24) +
labs(title="Before Weighting") +
transparent_bg()

Code
smoke_df |>
ggplot(aes(x=motiv)) +
# Predictions
geom_point(
aes(y=enroll, color=factor(enroll))
) +
# Values
geom_point(
aes(y=pred, color=factor(enroll))
) +
labs(color="enroll") +
theme_dsan(base_size=24) +
transparent_bg() +
labs(title="Propensity to Enroll")
ipw_min <- min(smoke_df$ipw)
ipw_max <- max(smoke_df$ipw)
smoke_df <- smoke_df |> mutate(
ipw_scaled = (ipw - ipw_min) / (ipw_max - ipw_min)
)
smoke_df |>
ggplot(aes(x=motiv)) +
# Predictions
geom_point(
aes(y=enroll, color=factor(enroll))
) +
# Values
geom_point(
aes(y=ipw_scaled, color=factor(enroll))
) +
theme_dsan(base_size=24) +
transparent_bg() +
labs(
title="Inverse Probability-of-Treatment Weights (IPTW)",
color="enroll"
)↓

→
↑

Sudden “Jumps” in Wealth at Election Threshold!
Code
library(modelr)
library(tidyr)
library(broom)
## load the data
## Subset the data
labour_winners <- filter(MPs, party == "labour", margin > 0)
labour_losers <- filter(MPs, party == "labour", margin < 0)
tory_winners <- filter(MPs, party == "tory", margin > 0)
tory_losers <- filter(MPs, party == "tory", margin < 0)
### the regressions
labour_fit_win <- lm(ln.net ~ margin, data = labour_winners)
labour_fit_lose <- lm(ln.net ~ margin, data = labour_losers)
tory_fit_win <- lm(ln.net ~ margin, data = tory_winners)
tory_fit_lose <- lm(ln.net ~ margin, data = tory_losers)
y1_labour_win <- labour_winners %>%
data_grid(margin) %>%
add_predictions(labour_fit_win)
y2_labour_lose <- labour_losers %>%
data_grid(margin) %>%
add_predictions(labour_fit_lose)
y1_tory_win <- tory_winners %>%
data_grid(margin) %>%
add_predictions(tory_fit_win)
y2_tory_lose <- tory_losers %>%
data_grid(margin) %>%
add_predictions(tory_fit_lose)
## setting the ggplot theme
theme_set(theme_classic(base_size = 22))
## Labour
ggplot() +
geom_point(data = labour_winners,
mapping = aes(x = margin, y = ln.net), shape = 1, alpha=0.6) +
geom_point(data = labour_losers,
mapping = aes(x = margin, y = ln.net), shape = 1, alpha=0.6) +
geom_line(data = y1_labour_win,
mapping = aes(x = margin, y = pred),
color = "blue", size = 1, linewidth=2) +
geom_line(data = y2_labour_lose,
mapping = aes(x = margin, y = pred),
color = "blue", size = 1, linewidth=2) +
geom_vline(xintercept = 0,
linetype = "dashed") +
labs(x = "Margin of victory",
y = "log net wealth at death",
title = "Labour") +
xlim(-0.5, 0.5) +
ylim(6, 18) +
transparent_bg()
Code
## Tory
ggplot() +
geom_point(data = tory_winners,
mapping = aes(x = margin, y = ln.net), shape = 1, alpha=0.6) +
geom_point(data = tory_losers,
mapping = aes(x = margin, y = ln.net), shape = 1, alpha=0.6) +
geom_line(data = y1_tory_win,
mapping = aes(x = margin, y = pred),
color = "blue", size = 1, linewidth=2) +
geom_line(data = y2_tory_lose,
mapping = aes(x = margin, y = pred),
color = "blue", size = 1, linewidth=1) +
geom_vline(xintercept = 0,
linetype = "dashed") +
labs(x = "Margin of victory",
y = "log net wealth at death",
title = "Tory") +
xlim(-0.5, 0.5) +
ylim(6, 18) +
transparent_bg()
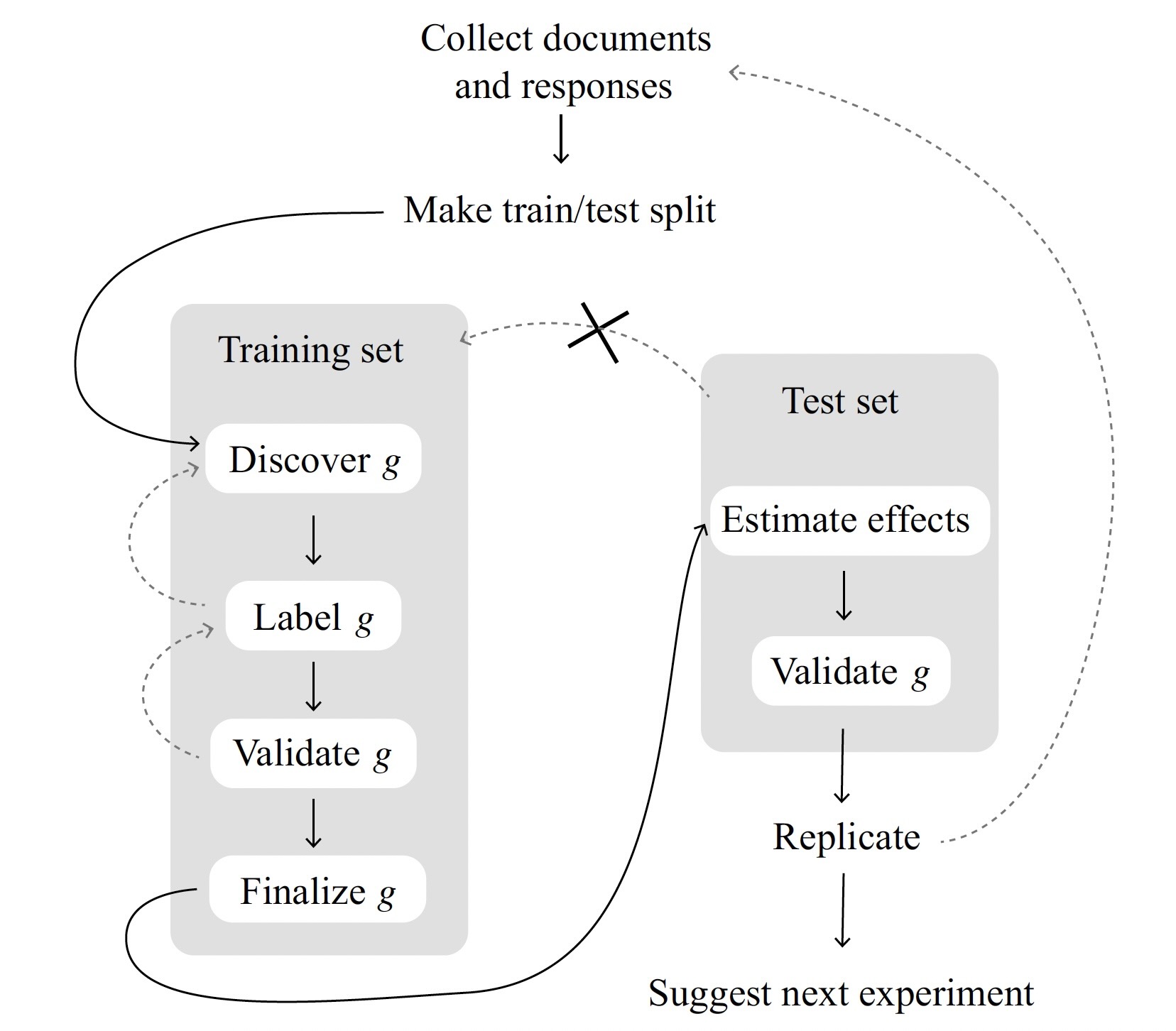
The Solution? Sample Splitting!
- Machine learning noticed this long ago: the goal is a model that generalizes, not memorizes!