Week 4: Rights, Policies, and Fairness in AI
DSAN 5450: Data Ethics and Policy
Spring 2026, Georgetown University
Wednesday, February 4, 2026
Part 3: The “Training Data Bottleneck”


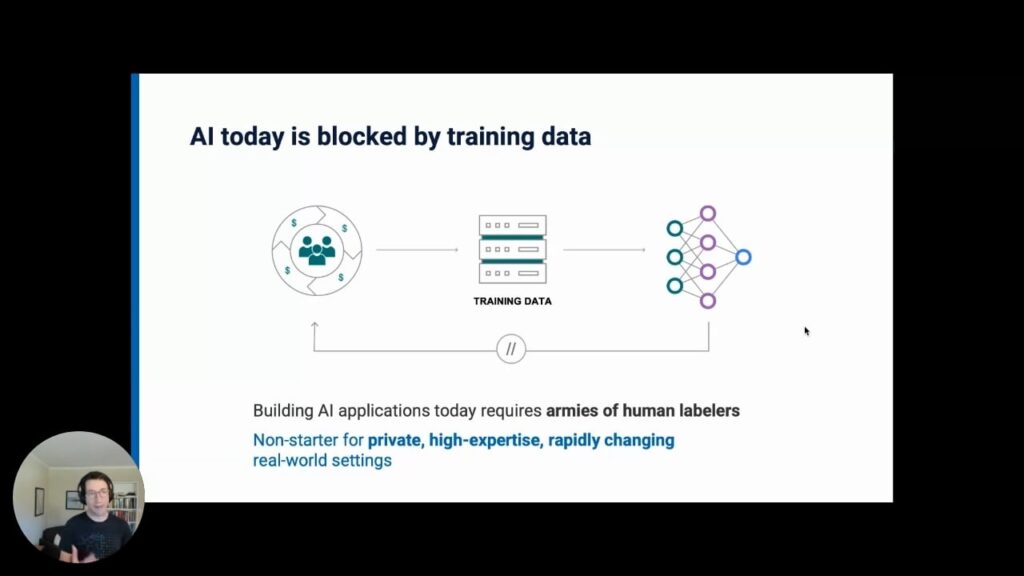
With so much technical progress […] why is there so little real enterprise success? The answer all too often is that many enterprises continue to be bottlenecked by one key ingredient: the large amounts of labeled data [needed] to train these new systems.
Human Labor


Computer Scientists Being Responsible at Georgetown!

- (PS… UMD CS class of 2013 extremely overrepresented here 😜 go Terps
![]() )
)
What Comes With Human Labels? Human Biases!
AI Machine Go Brrr



Biases In Our Brains → Biases in Our Models → Material Effects
- “Reification”: Pretentious word for an important phenomenon, whereby talking about something (e.g., race) as if it was real ends up leading to it becoming real (having real impacts on people’s lives)1
On average, being classified as White as opposed to Coloured would have more than quadrupled a person’s income. (Pellicer and Ranchhod 2023)



Reification in Science

- Goodhart’s Law: “When a measure becomes a target, it ceases to be a good measure”
- Cat-and-mouse game between goals (🚩) and ways of measuring progress towards goals (also 🚩)
Reflective Equilibrium
- Most criticisms of any framework boil down to, “great in theory, but doesn’t work in practice”
- The way to take this seriously: reflective equilibrium
- Introduced by Rawls (1951), but popularized by Rawls (1971)
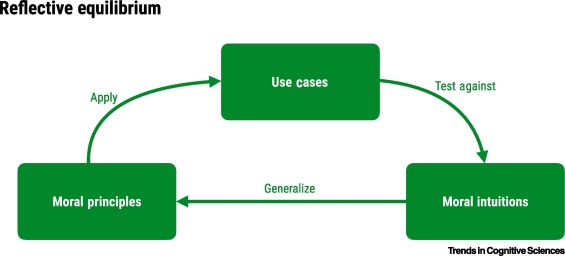
From Awad et al. (2022)
Normative vs. Descriptive Quick Recap
- Languages are arbitrary conventions for communication
- Ethical systems build on this language to non-arbitrarily mark out things that are good/bad
- Society wouldn’t be too different if we “shuffled” words (we’d just vibrate our vocal chords differently), but would be very different if we “shuffled” good/bad labeling

Standard Counterargument to Consequentialism
Millions are kept permanently happy, on the one simple condition that a certain lost soul on the far-off edge of things should lead a life of lonely torture (James 1891)
- Modern example: people “out there” suffer so we can have iPhones, etc.

One Solution: Individual Rights
- Rights are vetoes which individuals can use to cancel out collective/institutional decisions which affect them (key example for us: right to privacy)
- Rawls/liberalism: individual rights are lexically prior to “efficiency” and/or distributional concerns
- Why the buzzword “lexically”? Enter (non-scary) math!
- We can put lowercase letters of English alphabet in an order: \(\texttt{a} \prec \texttt{b} \prec \cdots \texttt{z}\)
- We can put capital letters of English alphabet in an order: \(\texttt{A} \prec \texttt{B} \prec \cdots \prec \texttt{Z}\)
- What if we need to sort stuff with both types? We can decide that capital letters are lexically prior to lowercase letters, giving us a combined ordering:

\[ \boxed{\texttt{A} \prec \texttt{B} \prec \cdots \prec \texttt{Z} \prec \texttt{a} \prec \texttt{b} \prec \cdots \prec \texttt{z}} \]
Lexical Ordering (I Tricked You 😈)
- You thought I was just talking about letters, but they’re actually variables: capital letters are rights, lowercase letters are distributive principles
\[ \underbrace{\texttt{A} \prec \texttt{B} \prec \cdots \prec \texttt{Z}}_{\mathclap{\substack{\text{Individual Rights} \\ \text{Basic Goods}}}} \phantom{\prec} \prec \phantom{\prec} \underbrace{\texttt{a} \prec \texttt{b} \prec \cdots \prec \texttt{z}}_{\mathclap{\substack{\text{Distributive Principles} \\ \text{Money and whatnot}}}} \]

Better Metaphor Than Letters
- Letters are where Rawls gets “lexically prior” from, but letters are total orderings (we know where every letter “stands” in relation to every other letter)
- Better metaphor: UDC (2yr school) rule for allocating basketball tickets:
\[ \text{Seniors} \prec \text{Juniors} \]
- \(\Rightarrow\) If you’re a Senior, whether at “top” or “bottom” of a ranking of Seniors, you still (by Constitution) have priority over all Juniors…
- Why is this more helpful? Because we don’t need to define the rankings within classes to know the rankings between classes in this case

Psychological Synthesis: Two-Level Utilitarianism
- It would be exhausting to compute Nash equilibrium strategies for every scenario
- Instead, we can develop heuristics that work for most cases, then reevaluate and update when we encounter tough cases
- (Brings us back to reflective equilibrium!)

Individual vs. Social Morality
- That was all already hard enough, to reason about individual morality
- Now add in the fact that we live in a society 😰
- Things that happen depend not only on our choices but also the choices of others

Enter Game Theory
- A tool for analyzing how individual choices + choices of others \(\rightarrow\) outcomes!
- Example: You (\(A\)) and a friend (\(B\)) committed a robbery, and you’re brought into the police station for questioning.
- You’re placed in separate rooms, and each of you is offered a plea deal: if you testify while your partner stays silent, you go free and they go to jail for 3 years.
- Otherwise, if you both stay silent, they have very little evidence and can only jail you for 1 year
- However, there’s a catch: if you both confess, you both get two years in jail, since they now have maximal evidence

Individual Decision-Making
- Let’s think through \(A\)’s best responses to the possible choices \(B\) could make:
- If \(B\) stays silent, what is \(A\)’s best option?
- Staying silent results in 1 year of jail
- Testifying results in 0 years of jail
- So it is better to testify
- If \(B\) testifies, what is \(A\)’s best option?
- Staying silent results in 3 years of jail
- Testifying results in 2 years of jail
- So it is better to testify
- The result: regardless of what \(B\) does, \(A\) is better off testifying!
The Social Outcome
Context-Free Fairness
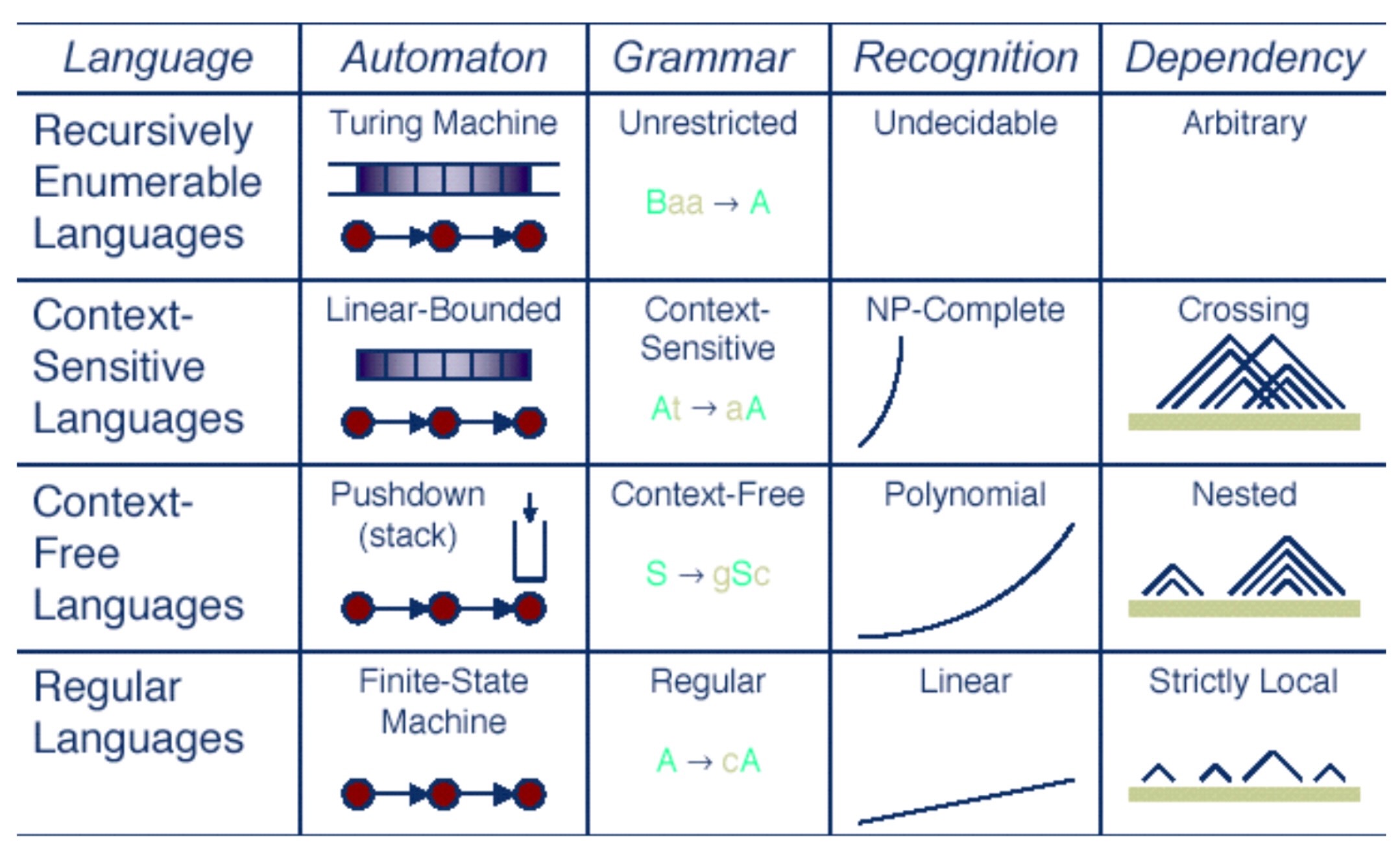
From Introduction to Formal Languages and Automata, Simon Fraser University (2006). This figure summarizes the Chomsky Hierarchy of Languages, developed by Noam Chomsky, who also has a lot to say about Ethics and Policy!
The Brogrammer’s Criterion
- Racism solved, folks! 🥳🎊🎉 End of the course, have a great rest of your data science career ✌️

(No) Fairness Through Unawareness
- HW1: Using tiny sample (\(N < 10K\)) of Florida voter registrations… RandomForestClassifier (default settings, no hyperparameter tuning, no cross-validation, no ensembling with other methods) will predict self-reported race with \(>90\%\) accuracy (in balanced sample) from just surname and county of residence
- Can reach \(70\text{-}75\%\) with just surname or just county of residence
- Also in HW1: Facebook ad matching service provides over 1,000 different user attributes for (micro)targeting

From Datta et al. (2017)
To Make It Even More Concrete…
- Bloomberg analysis of neighborhoods with same-day delivery from Amazon:
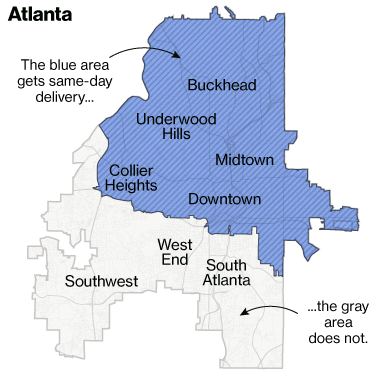

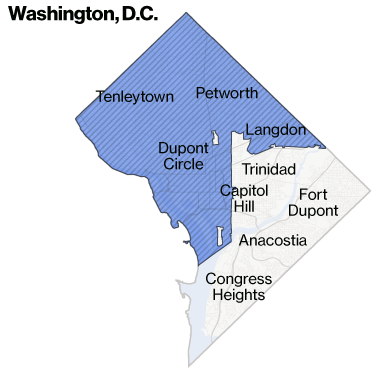
What the Fairness Measures Will Feel Like For Now

- (They will get more robust and will incorporate context soon, I promise!)
Who Remembers… 🎉Confusion Matrices!!!🎉
- Terrifyingly higher stakes than in DSAN 5000, however!
- Now \(D = 1\) could literally mean “shoot this person” or “throw this person in jail for life”

From Mitchell et al. (2021)
Context-Free Fairness
From Introduction to Formal Languages and Automata, Simon Fraser University (2006). This figure summarizes the Chomsky Hierarchy of Languages, developed by Noam Chomsky, who also has a lot to say about Ethics and Policy!
The Brogrammer’s Criterion
- Racism solved, folks! 🥳🎊🎉 End of the course, have a great rest of your data science career ✌️
(No) Fairness Through Unawareness
- HW1: Using tiny sample (\(N < 10K\)) of Florida voter registrations… RandomForestClassifier (default settings, no hyperparameter tuning, no cross-validation, no ensembling with other methods) will predict self-reported race with \(>90\%\) accuracy (in balanced sample) from just surname and county of residence
- Can reach \(70\text{-}75\%\) with just surname or just county of residence
- End-of-HW1 discussion: Facebook ad matching service provides over 1,000 different user attributes for (micro)targeting
From Datta et al. (2017)
What the Fairness Measures Will Feel Like For Now
- (They will get more robust and will incorporate context soon, I promise!)
Who Remembers… 🎉Confusion Matrices!!!🎉
- Terrifyingly higher stakes than in DSAN 5000, however!
- Now \(D = 1\) could literally mean “shoot this person” or “throw this person in jail for life”
From Mitchell et al. (2021)
(No) Fairness Through Unawareness
- HW1: Using tiny sample (\(N < 10K\)) of Florida voter registrations… RandomForestClassifier (default settings, no hyperparameter tuning, no cross-validation, no ensembling with other methods) will predict self-reported race with \(>90\%\) accuracy (in balanced sample) from just surname and county of residence
- Can reach \(70\text{-}75\%\) with just surname or just county of residence
- Also in HW1: Facebook ad matching service provides over 1,000 different user attributes for (micro)targeting
From Datta et al. (2017)
Last One I Promise
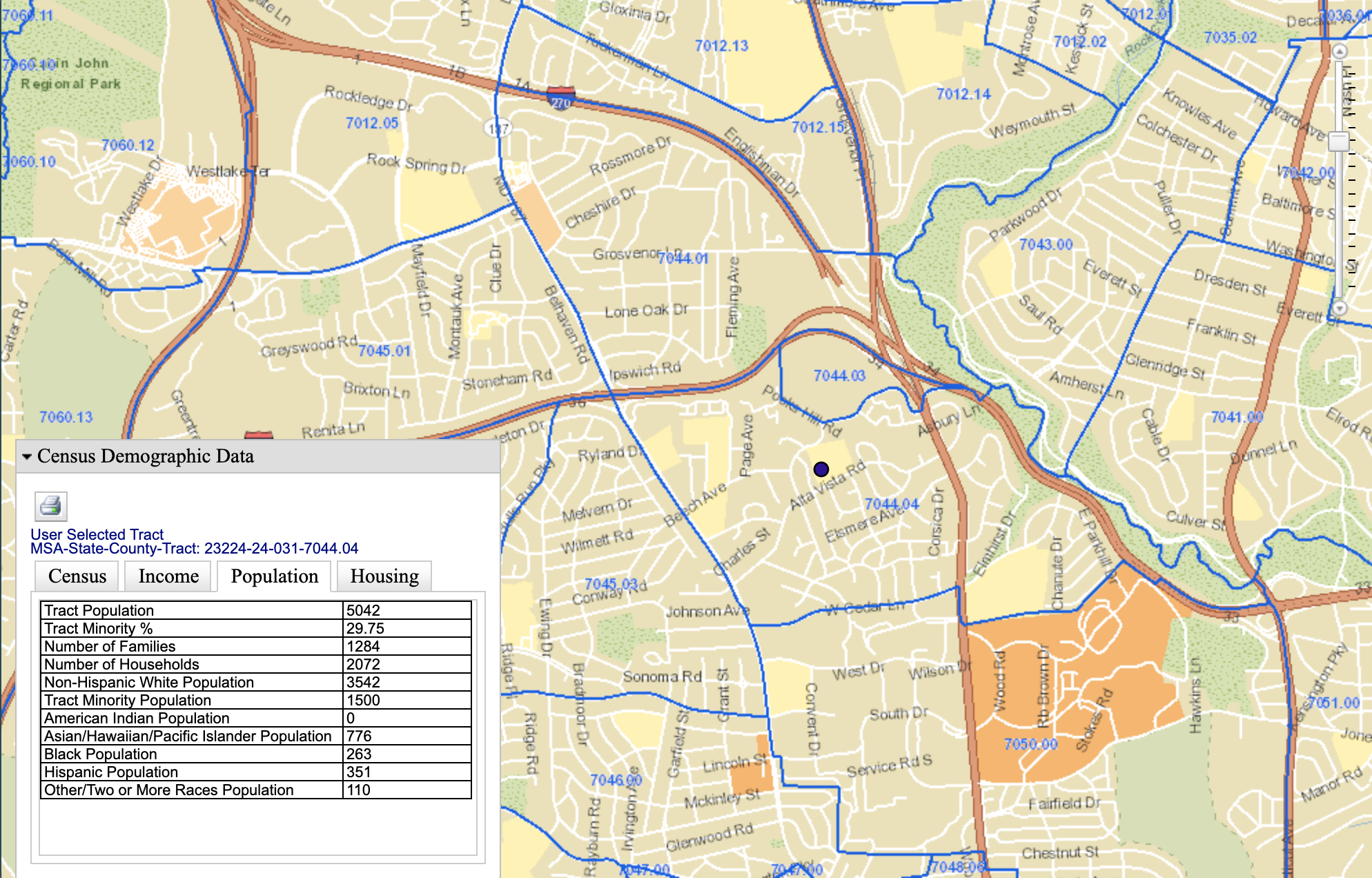
Predicting self-reported whiteness with 70% accuracy
Last One I Promise
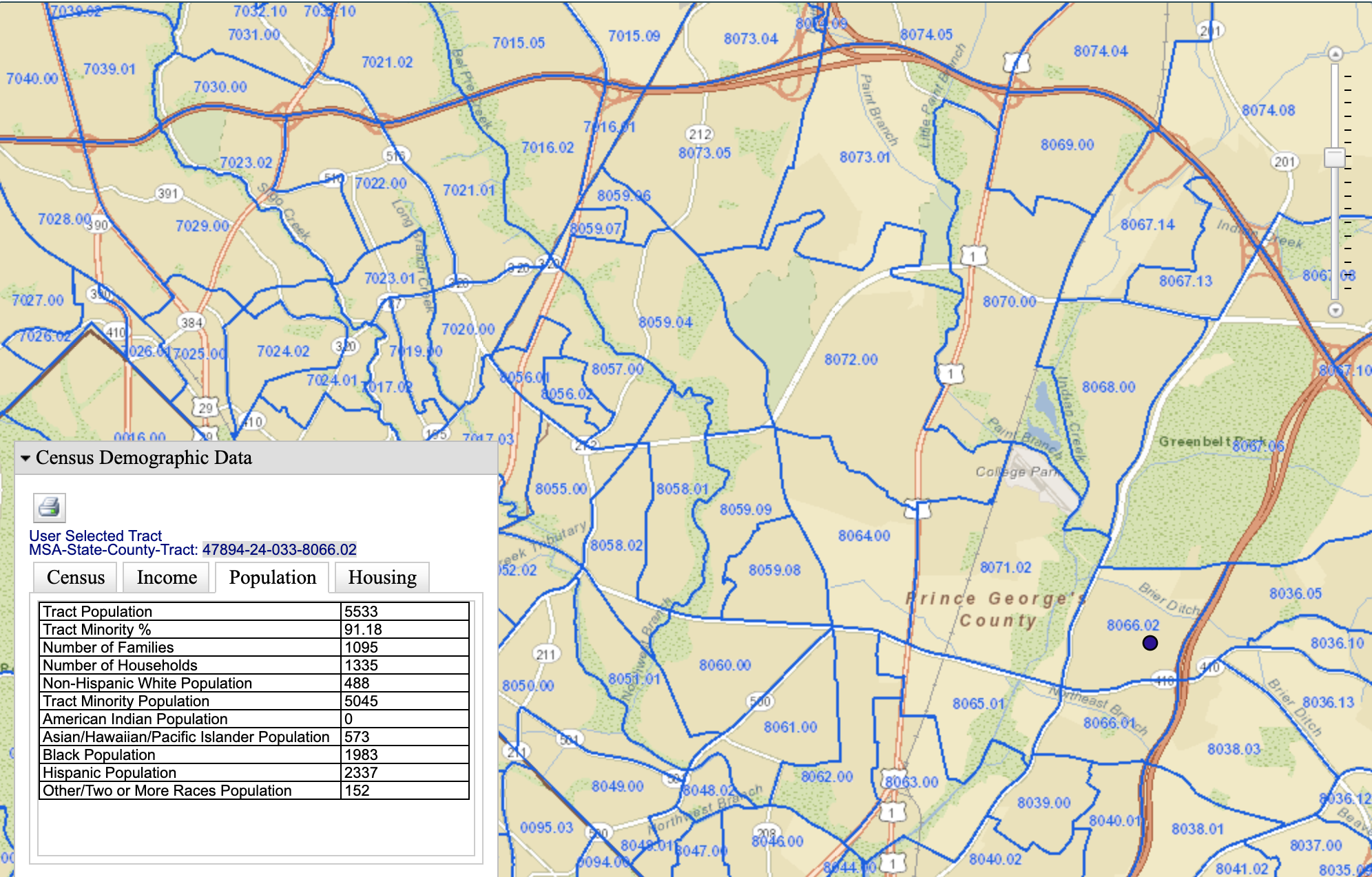
Predicting self-reported non-whiteness with 90% accuracy
⚠️ LESS EQUATIONS PLEASE! 😤
- Depending on your background and/or learning style (say, visual vs. auditory), you may be able to look at equations on previous two slides and “see” what they’re “saying”
- If your brain works similarly to mine, however, your eyes glazed over, you began dissociating, planning an escape route, etc., the moment \(> 2\) variables appeared
- If you’re in the latter group, welcome to the cult of Probabilistic Graphical Models 😈

Your first PGM, illustrating hypothesized causal relationships between three random variables \(Y\) (outcome), \(D\) (decision), and \(A\) (protected attribute). The \(Y\) node is shaded to indicate that it is an observed value in our model, rendering the unobserved values \(D\) and \(A\) independent conditional on it. If I was elected Emperor of Math, equations would be abolished in favor of PGMs.