Week 2: Linear Regression
DSAN 5300: Statistical Learning
Spring 2026, Georgetown University
Monday, January 12, 2026
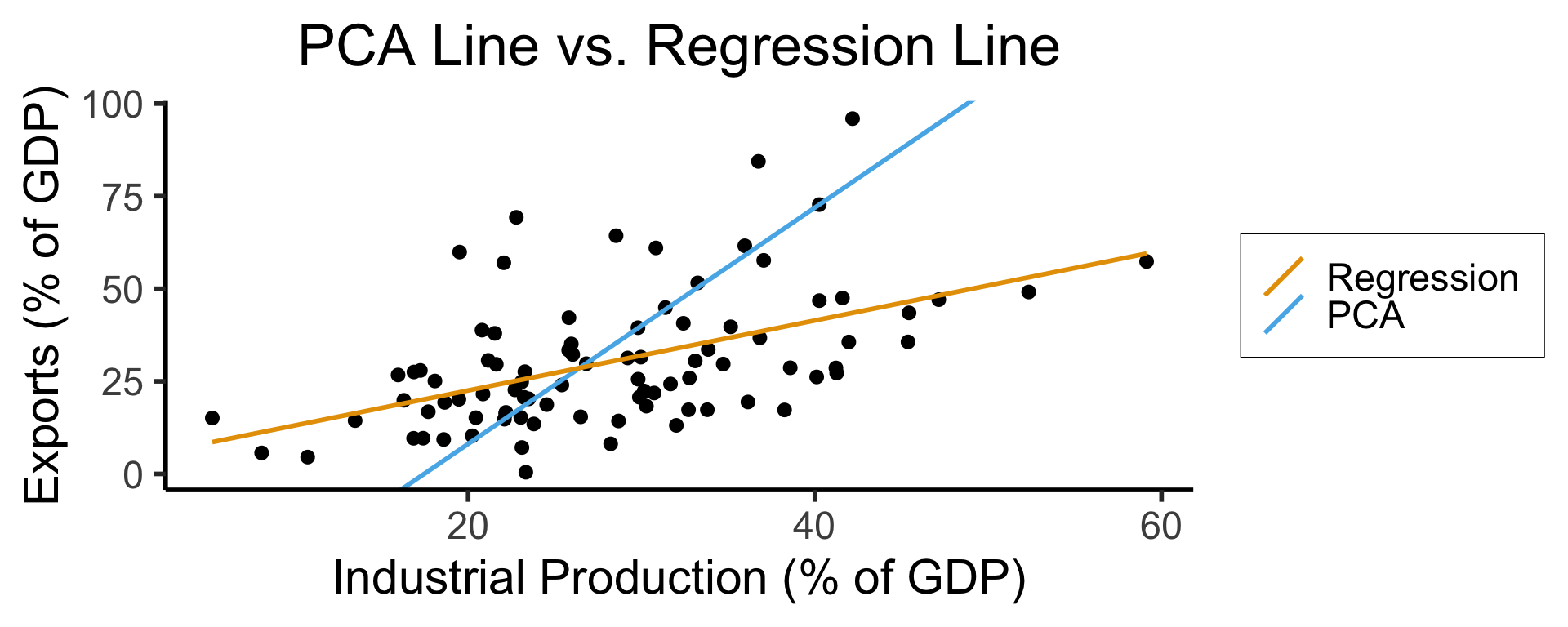
How Do We Define “Best”?
- Intuitively, two different ways to measure how well a line fits the data:
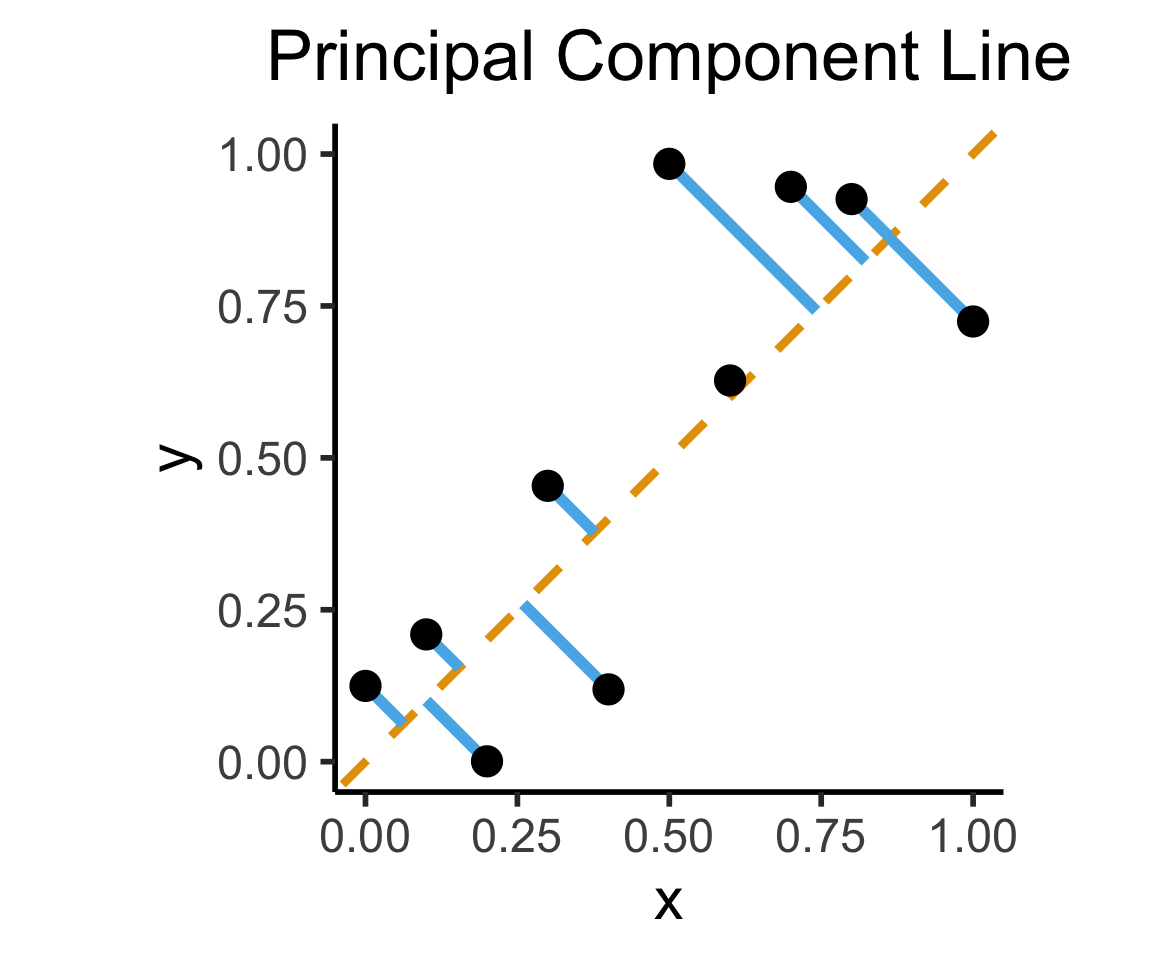
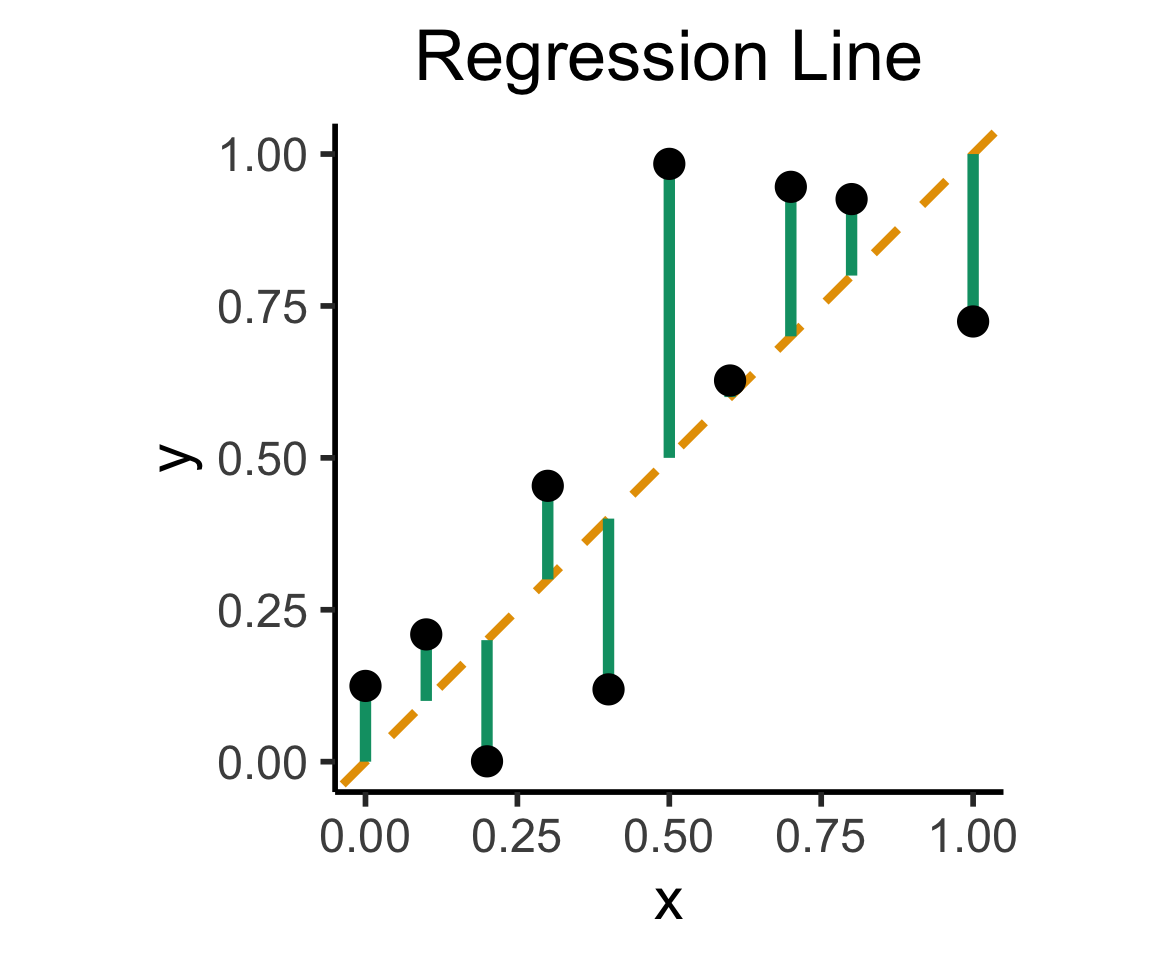
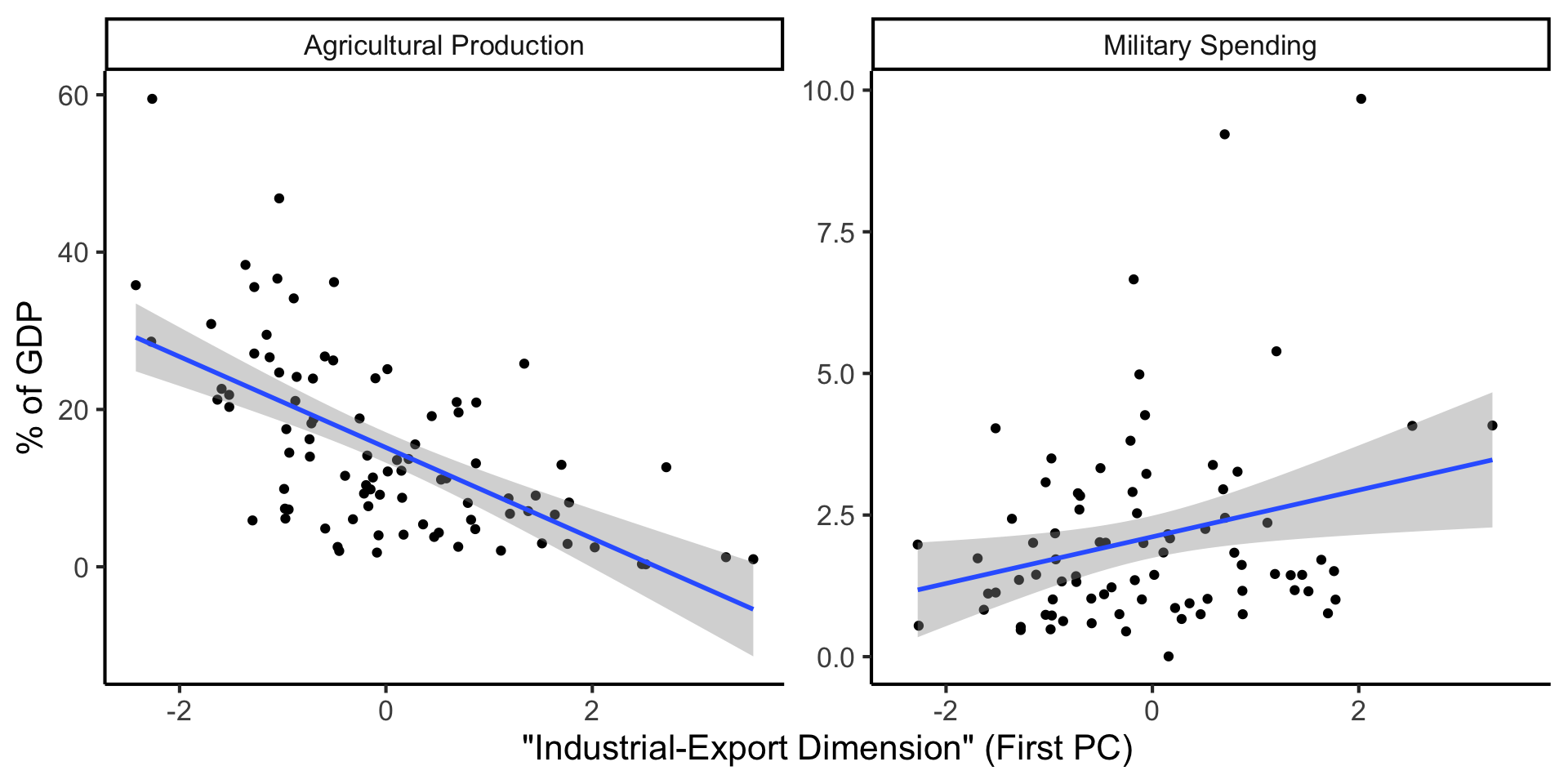
Create Your Own Dimension!
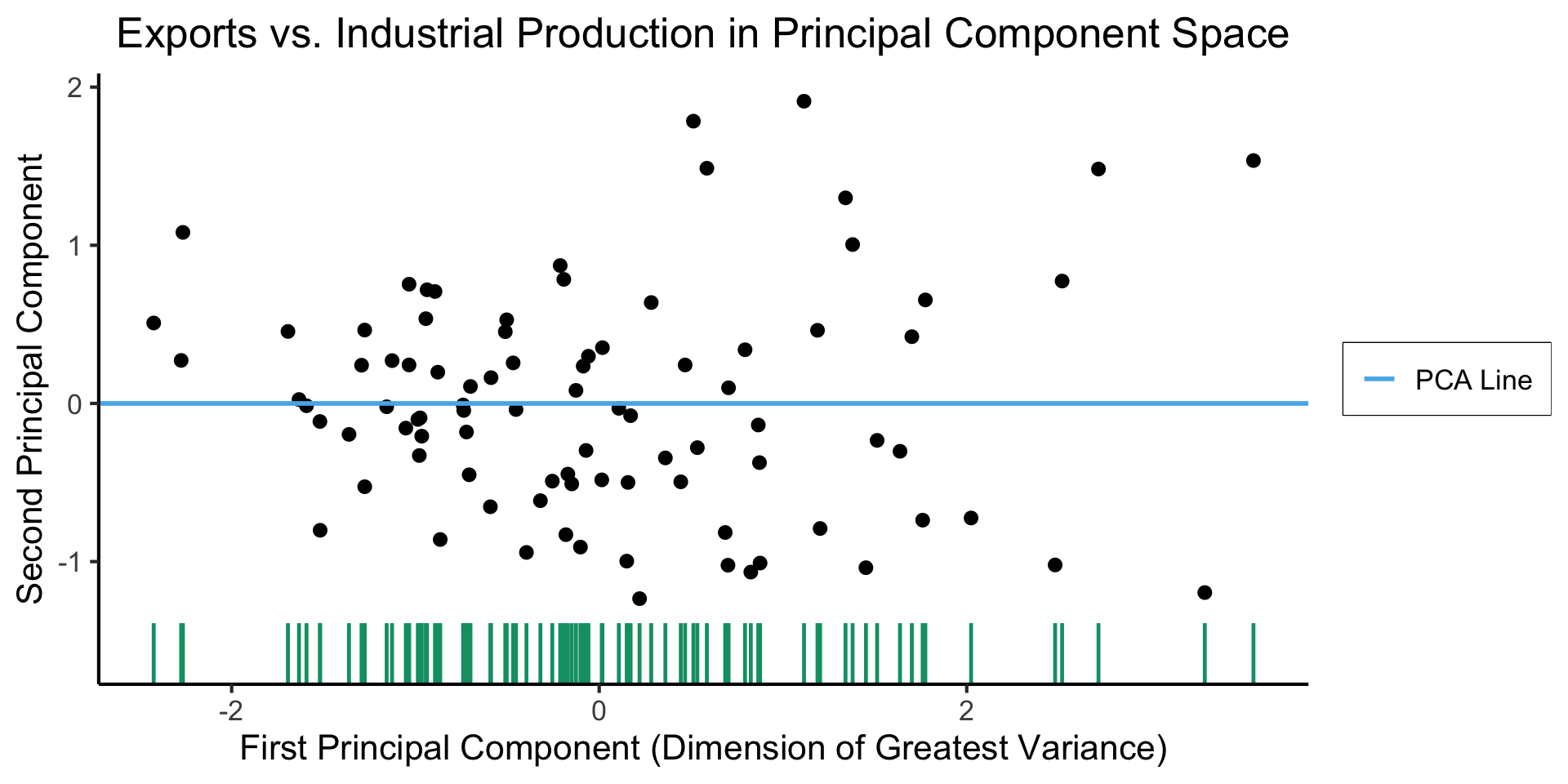
…And Use It for EDA
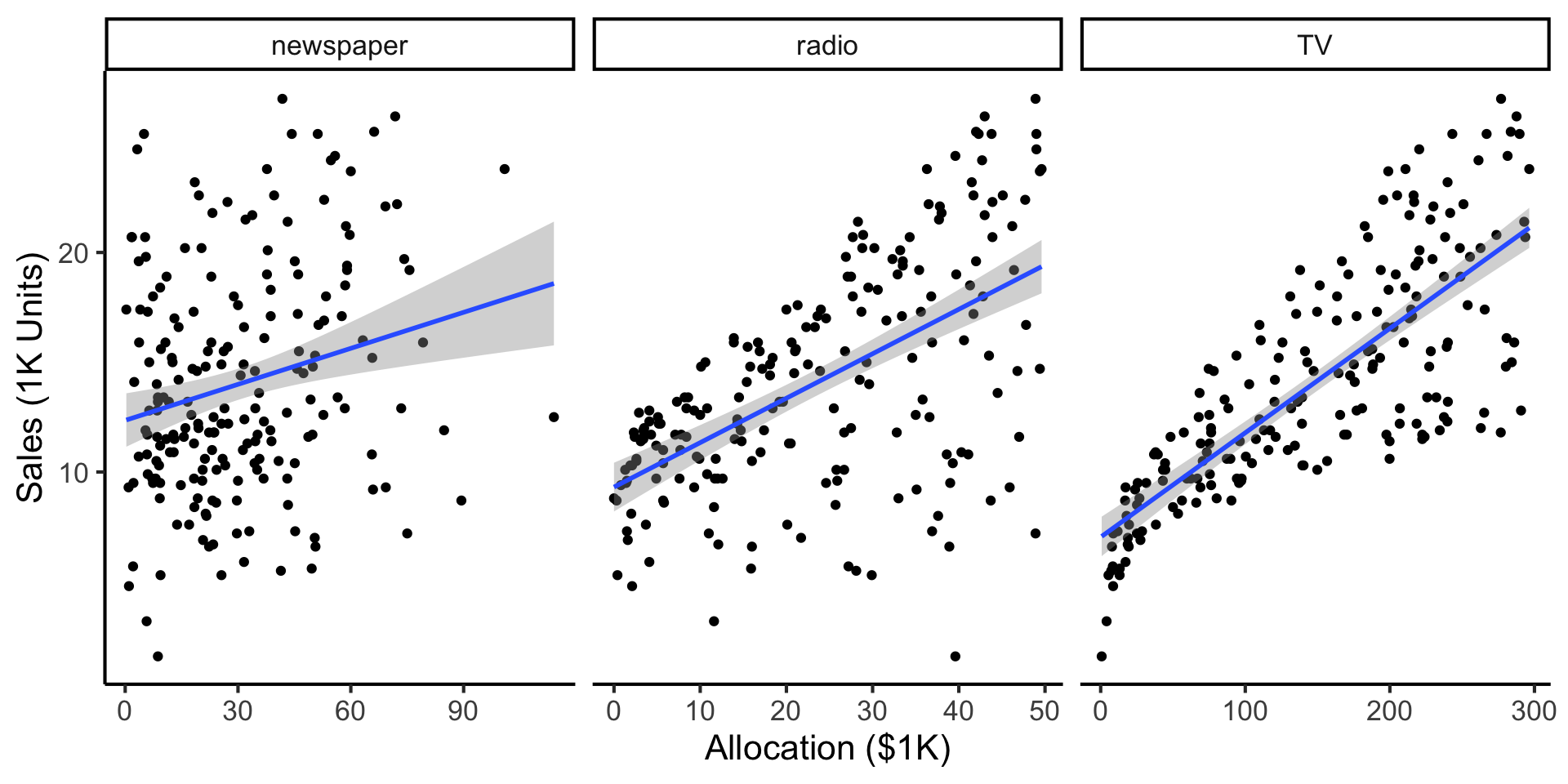
Example: Advertising Effects
- Independent variable: $ put into advertisements; Dependent variable: Sales
- Goal 1: Predict sales for a given allocation
- Goal 2: Infer best allocation for a given advertising budget (more simply: a new $1K appears! Where should we invest it?)
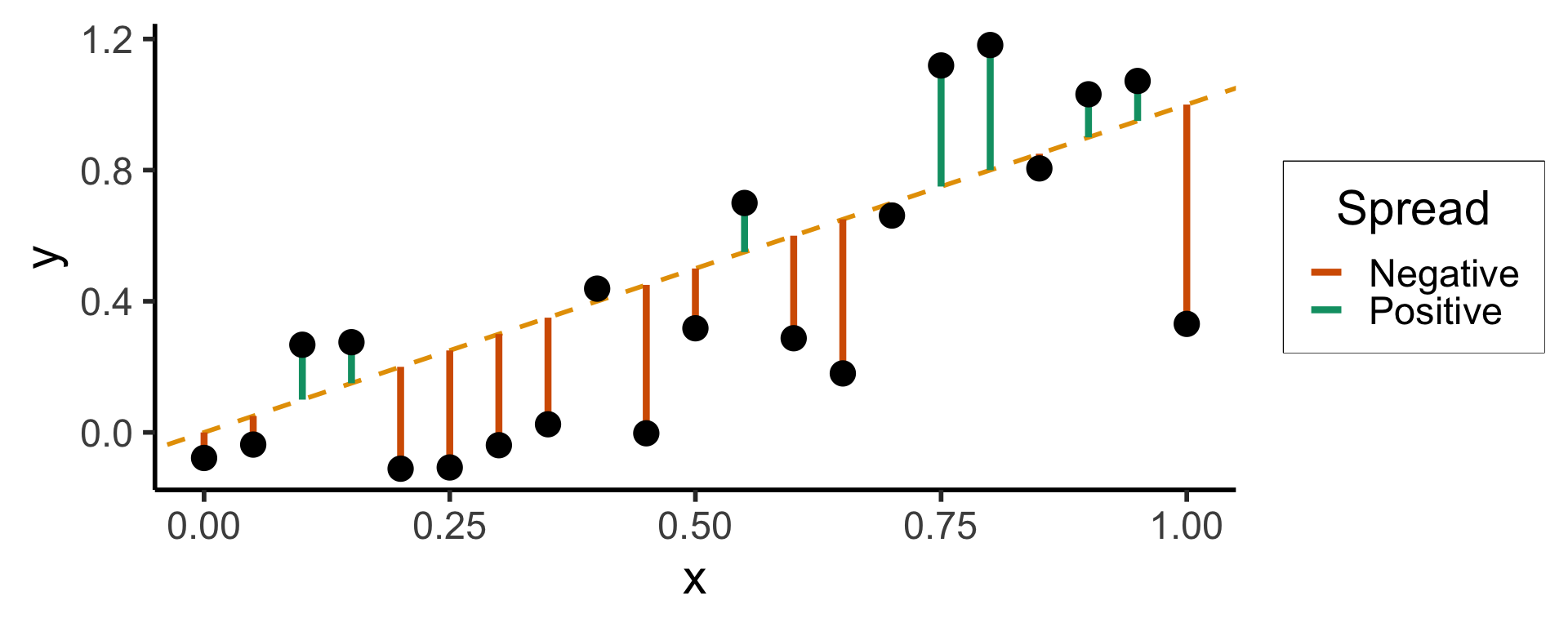
Least Squares: Minimizing Residuals
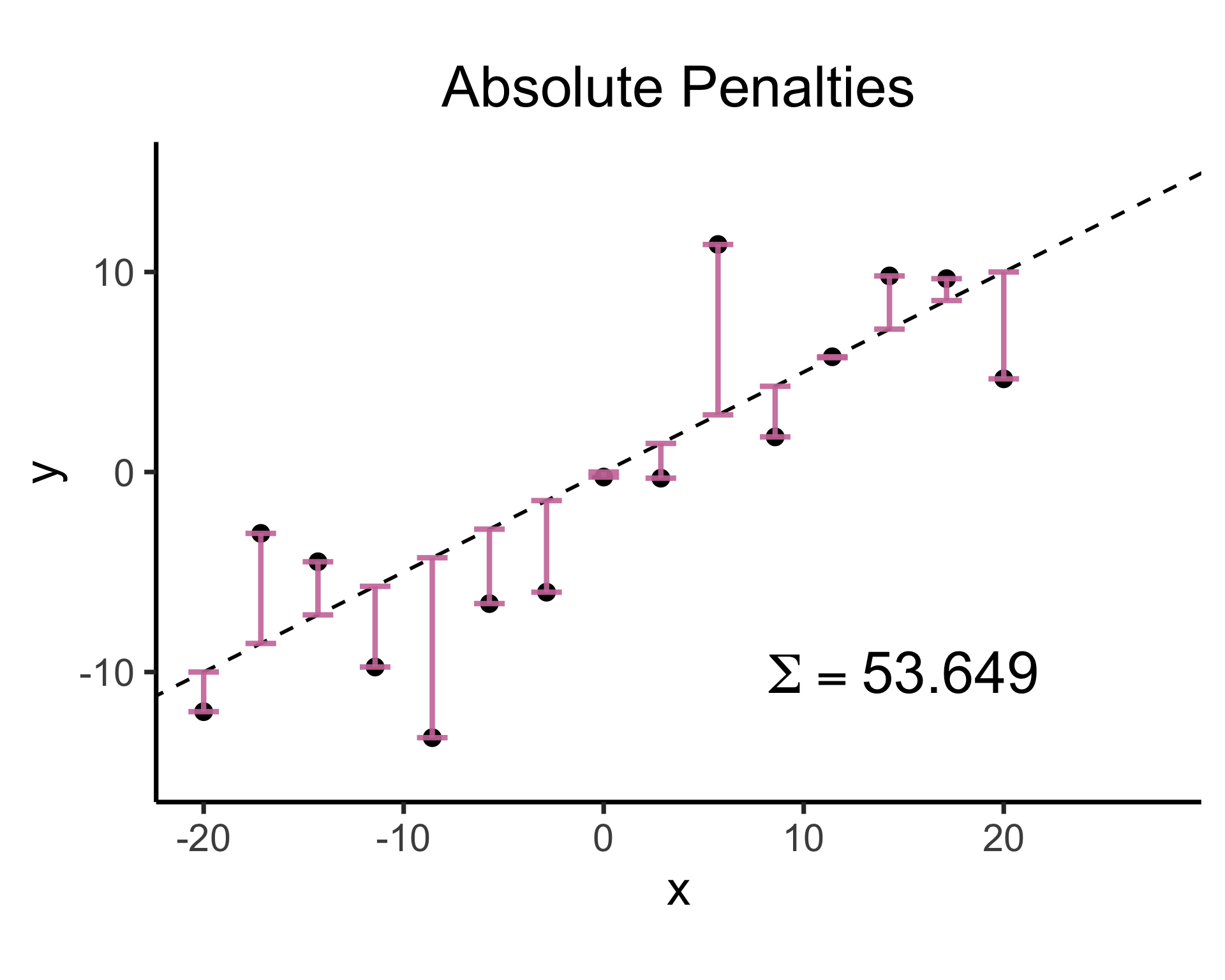
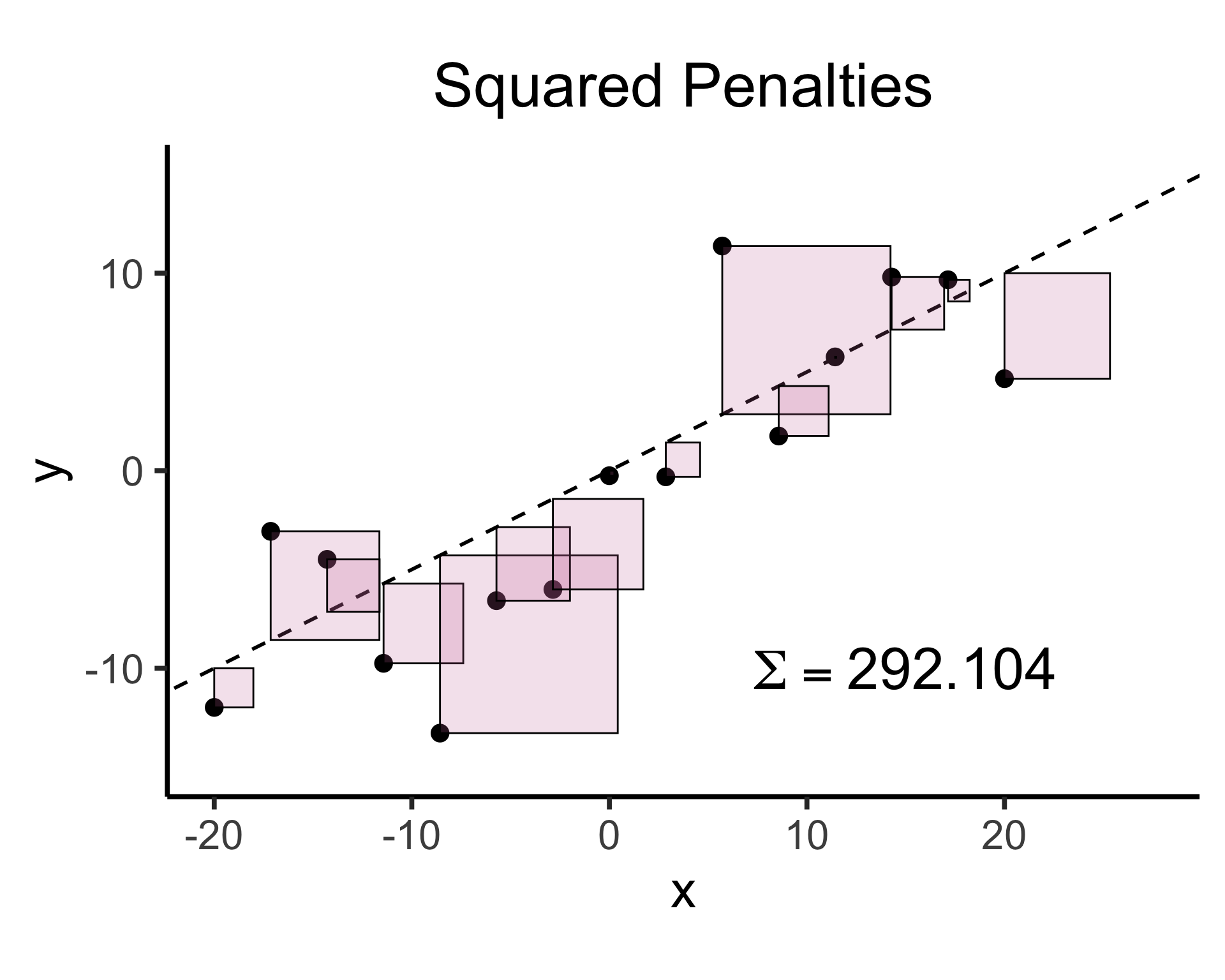
What can we optimize to ensure these residuals are as small as possible?
Sum?
0.0000000000Sum of Squares?
3.8405017200Sum of absolute vals?
7.6806094387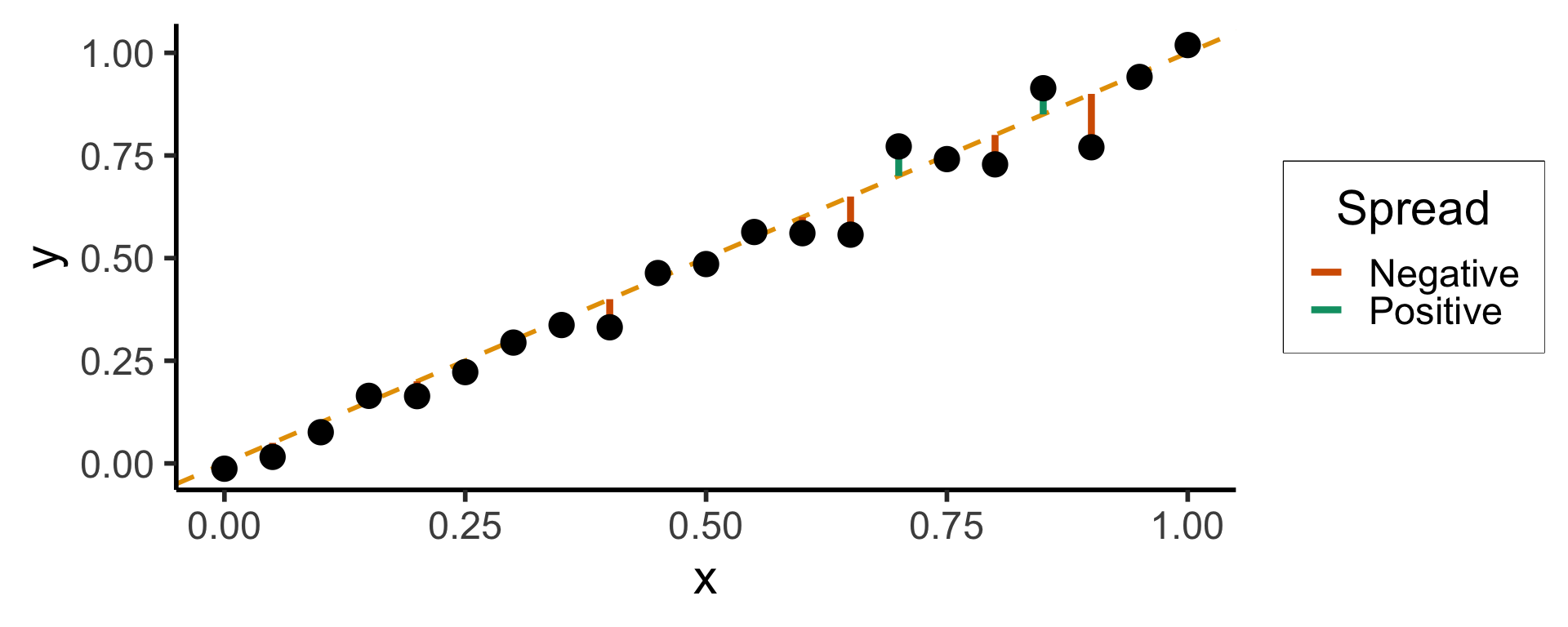
Sum?
0.0000000000Sum of Squares?
1.9748635217Sum of absolute vals?
5.5149697440Why Not Absolute Value?
- Two feasible ways to prevent positive and negative residuals cancelling out:
- Absolute error \(\left|y - \widehat{y}\right|\) or squared error \(\left( y - \widehat{y} \right)^2\)
- But remember: we’re aiming to minimize 👀 these residuals; ghost of calculus past 😱
- We minimize by taking derivatives… which one is differentiable everywhere?
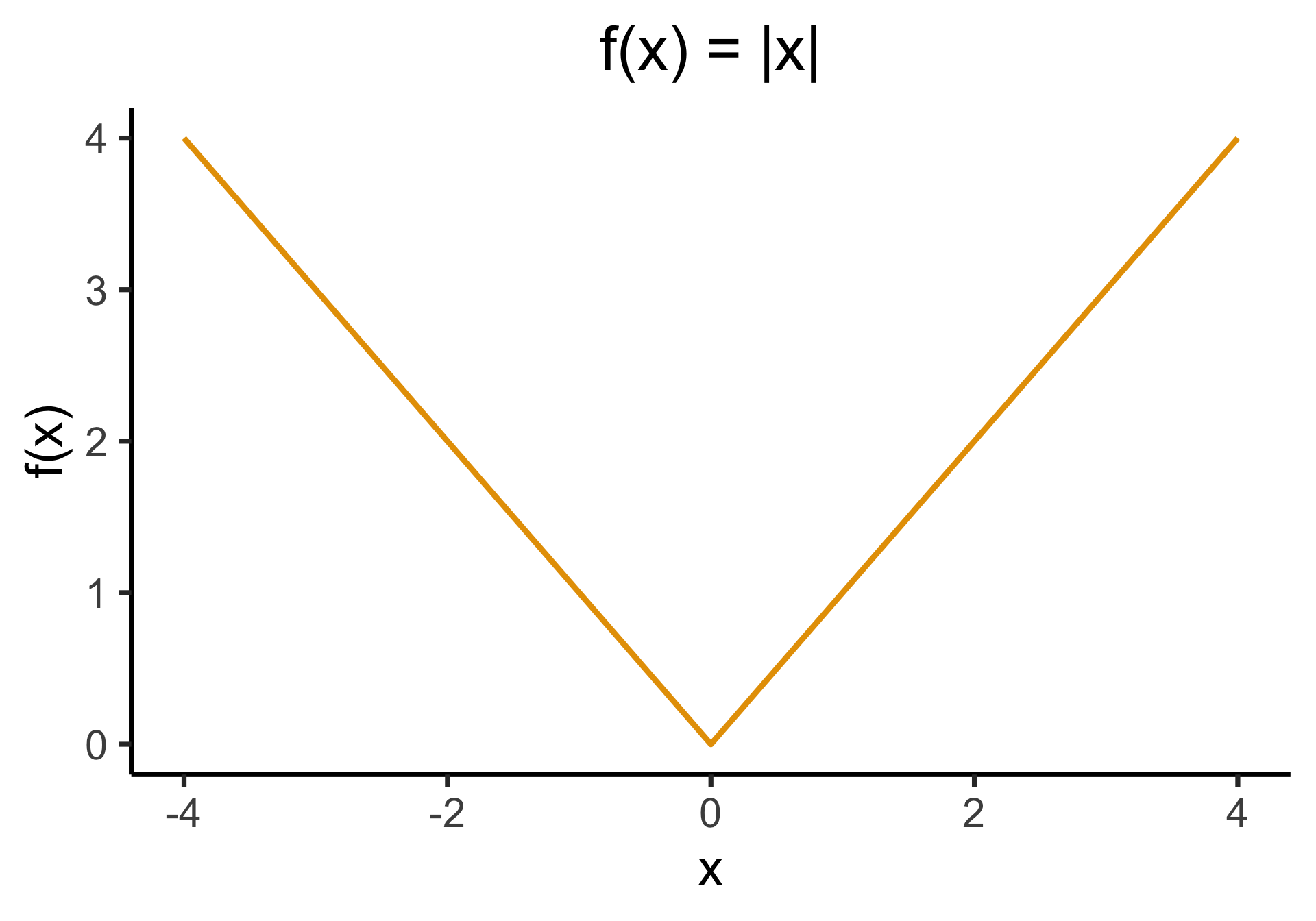
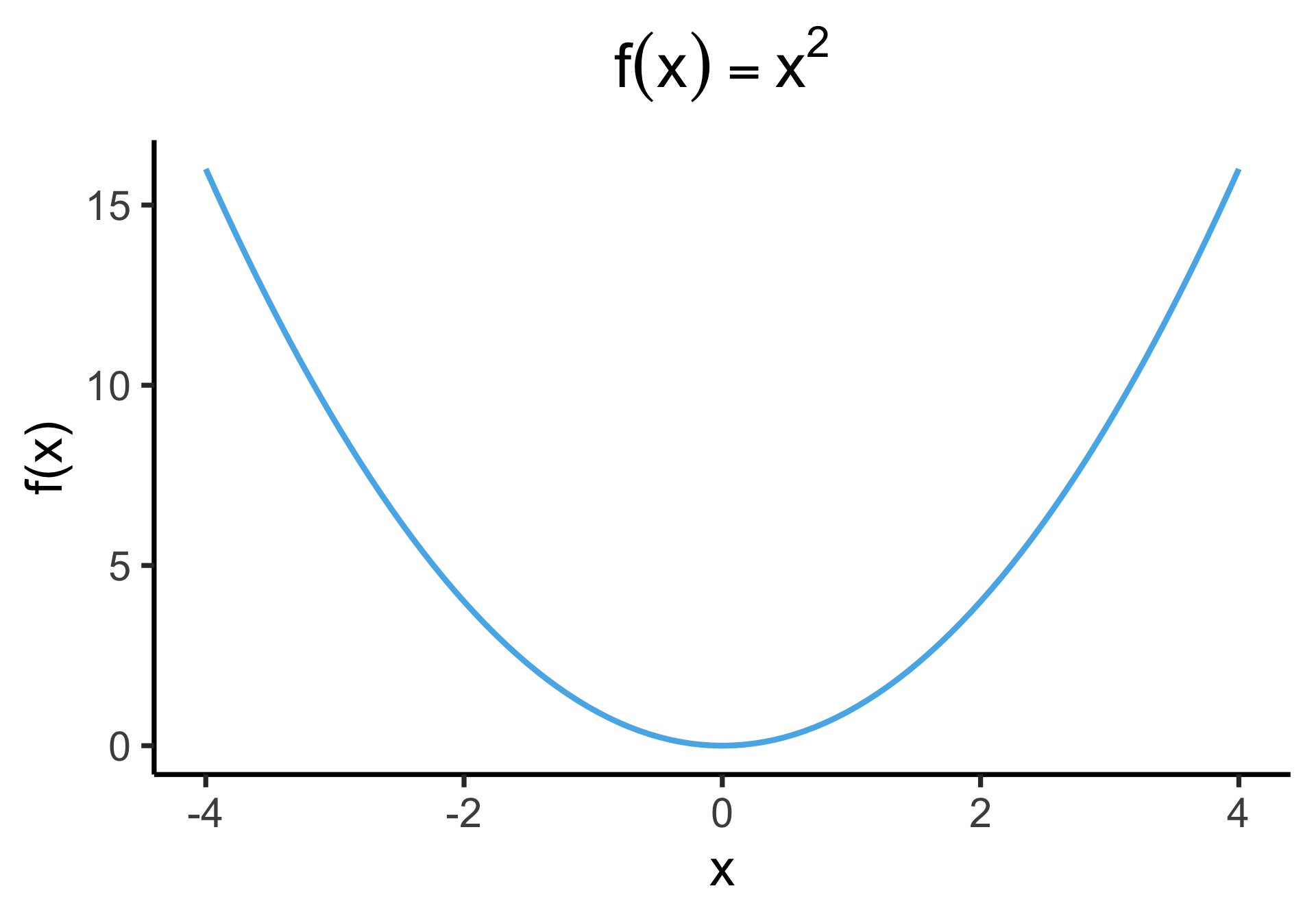
Outliers Penalized Quadratically
- May feel arbitrary at first (we’re “forced” to use squared error because of calculus?)
- It also has important consequences for “learnability” via gradient descent!
Where Did That \(\mathbb{E}[Y \mid X = x_i]\) Come From?
- From our assumption that the irreducible errors \(\varepsilon_i\) are normally distributed \(\mathcal{N}(0, \sigma^2)\)
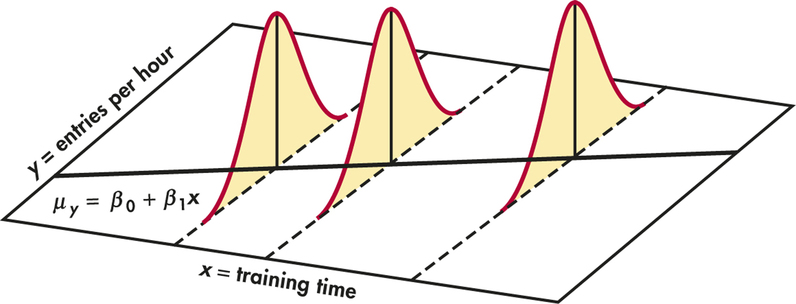
- Kind of an immensely important point, since it gives us a hint for checking whether model assumptions hold: spread around the regression line should be \(\mathcal{N}(0, \sigma^2)\)
Heteroskedasticity
- If spread increases or decreases for larger \(x\), for example, then \(\varepsilon \nsim \mathcal{N}(0, \sigma^2)\)

Figure 3.11 from James et al. (2023)