Week 12: Non-Parametric Statistics
DSAN 5100: Probabilistic Modeling and Statistical Computing
Section 01
Tuesday, November 18, 2025
What Makes It “Non-Parametric”?
- We’ve talked about how the Normal distribution is “standard” in multiple senses:
- Empirically: It arises from common processes in nature, like random walks
- Theoretically: It is the maximum-entropy distribution which encodes only1 knowledge of a mean \(\mu\) and a variance \(\sigma^2\)
- Then we talked about estimating these parameters (\(\param{\mu}\) and \(\param{\sigma^2}\)) from data: different ways to amalgamate information from an observed sample \(\mathbf{X} = (X_1, \ldots, X_n)\) to estimate (unobserved) \(\param{\mu}\) and \(\param{\sigma}^2\) with minimal bias and variance

- We therefore “funnel” all of the information contained in \(\mathbf{X}\) down into estimates of \(\param{\mu}\) and \(\param{\sigma^2}\)
- But… what if we’re wrong? What if the DGP is not based on a Normal distribution?
Example: 2022 World Cup
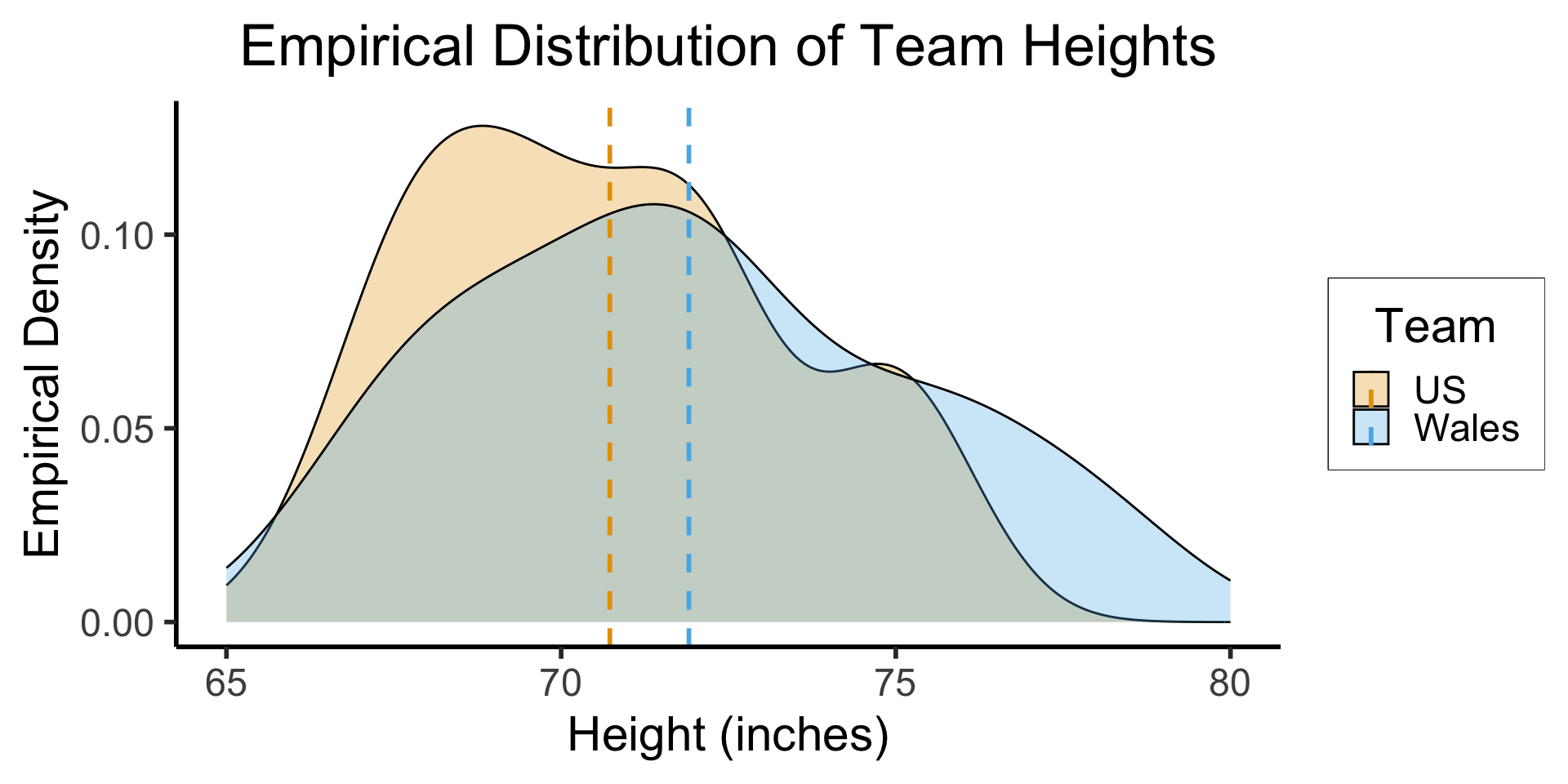
- Heights (inches) of Welsh vs. US national football teams (\(N = 22\) players total):
| Wales | 78 | 71 | 76 | 75 | 72 | 70 | 68 | 72 | 69 | 73 | 67 | \(\overline{X} \approx 71.91\) |
| USA | 75 | 68 | 75 | 69 | 70 | 70 | 72 | 67 | 72 | 72 | 70 | \(\overline{Y} \approx 70.73\) |
Code
library(tidyverse)
# Manual (via tibble)
# us_heights <- tibble(height=c(75, 68, 74, 68, 68, 70, 72, 67, 72, 72, 70))
# corrected
us_heights <- tibble(height=c(75, 68, 75, 69, 70, 70, 72, 67, 72, 72, 68))
mean_us <- mean(us_heights$height)
us_heights <- us_heights |> mutate(Team = "US")
wales_heights <- tibble(height=c(78, 71, 76, 75, 72, 70, 68, 72, 69, 73, 67))
mean_wales <- mean(wales_heights$height)
# From csv
# https://www.fifa.com/en/match-centre/match/17/255711/285063/400235455
team_df <- read_csv("assets/wc_usa_wales.csv")
# team_df |> group_by(team) |> summarize(height_mean = mean(height_in))
mean_df <- tibble(mean_height = c(mean_us, mean_wales), Team = c("US", "Wales"))
wales_heights <- wales_heights |> mutate(Team = "Wales")
players = bind_rows(us_heights, wales_heights)
ggplot(players, aes(x=height, fill=Team)) +
geom_density(
alpha=0.3, adjust=4/5
) +
geom_vline(
data=mean_df,
aes(xintercept=mean_height, color=Team),
linetype = "dashed",
linewidth = g_linewidth
) +
xlim(c(65,80)) +
dsan_theme("half") +
scale_fill_manual(values=c(cbPalette[1], cbPalette[2])) +
labs(
title = "Empirical Distribution of Team Heights",
x = "Height (inches)",
y = "Empirical Density"
)
Simulating Many Null-Hypothesis Worlds
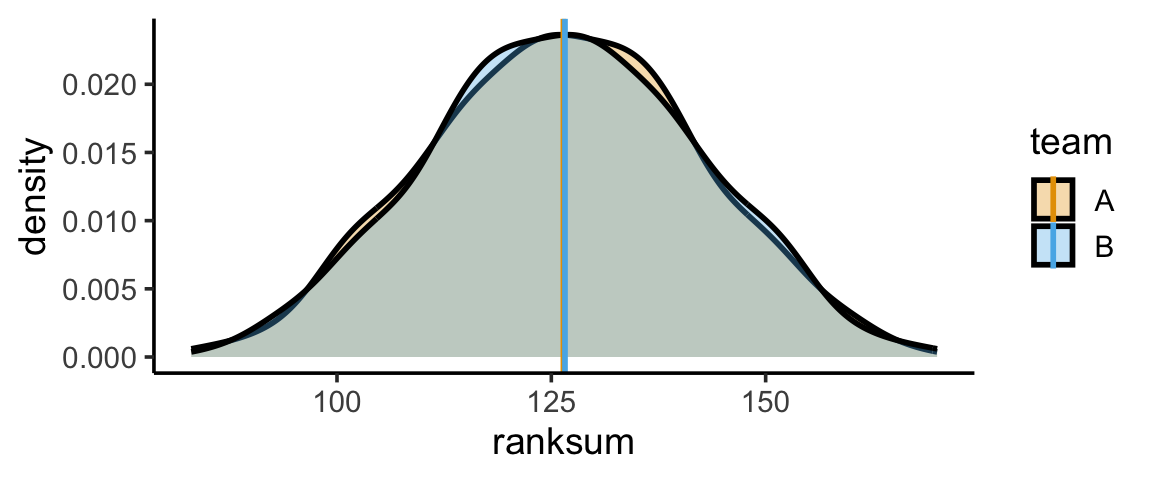
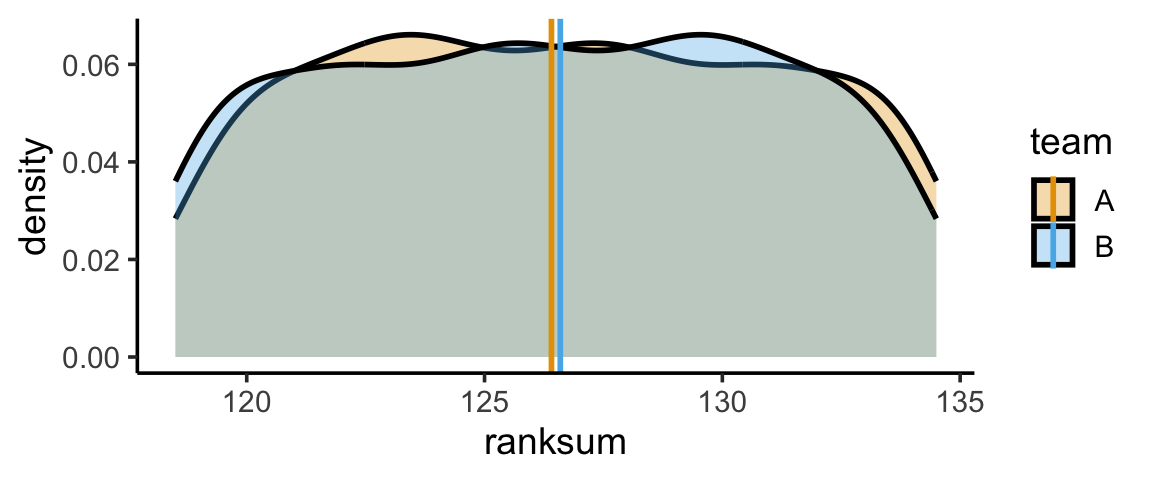
And we can repeat this process (say) 10K times:
Code
simulate_ranksums <- function(N1, N2) {
N <- N1 + N2
totalRankSum <- (N * (N+1)) / 2
s_1 <- runif(N1)
df_1 <- tibble(x = s_1, team = "A")
s_2 <- runif(N2)
df_2 <- tibble(x = s_2, team = "B")
df_combined <- bind_rows(df_1, df_2)
df_combined['rank'] <- rank(df_combined$x)
ranksum_df <- df_combined |> group_by(team) |> summarize(ranksum = sum(rank))
return(ranksum_df$ranksum)
}
num_sims <- 1000
results <- replicate(num_sims, simulate_ranksums(11,11))
t(results[,0:10]) [,1] [,2]
[1,] 133 120
[2,] 98 155
[3,] 115 138
[4,] 166 87
[5,] 137 116
[6,] 140 113
[7,] 146 107
[8,] 157 96
[9,] 119 134
[10,] 106 147[1] 126.407 126.593Code
# Separate ranksums
ranksum_A <- tibble(ranksum=results[1,], team="A")
ranksum_A_mean <- mean(ranksum_A$ranksum)
ranksum_B <- tibble(ranksum=results[2,], team="B")
ranksum_B_mean <- mean(ranksum_B$ranksum)
sim_df <- bind_rows(ranksum_A, ranksum_B)
# Means
mean_df <- tibble(mean_value = c(ranksum_A_mean, ranksum_B_mean), team=c("A","B"))
mean_center <- (ranksum_A_mean + ranksum_B_mean) / 2
gen_ranksum_plot <- function(radius=Inf) {
ranksum_plot <- ggplot(sim_df, aes(x=ranksum, fill=team)) +
geom_density(linewidth = g_linewidth, alpha=0.333) +
geom_vline(
data=mean_df,
aes(xintercept = mean_value, color=team),
linewidth = g_linewidth
) +
theme_classic(base_size=14) +
scale_fill_manual(values=c(cbPalette[1], cbPalette[2]))
if (radius != Inf) {
ranksum_plot <- ranksum_plot +
xlim(mean_center - radius, mean_center + radius)
}
return(ranksum_plot)
}
gen_ranksum_plot()