Week 6: Multivariate Distributions
DSAN 5100: Probabilistic Modeling and Statistical Computing
Section 01
Tuesday, September 30, 2025
Distributions in Continuous World
\[ \DeclareMathOperator*{\argmax}{argmax} \DeclareMathOperator*{\argmin}{argmin} \newcommand{\bigexp}[1]{\exp\mkern-4mu\left[ #1 \right]} \newcommand{\bigexpect}[1]{\mathbb{E}\mkern-4mu \left[ #1 \right]} \newcommand{\convergesAS}{\overset{\text{a.s.}}{\longrightarrow}} \newcommand{\definedas}{\overset{\text{def}}{=}} \newcommand{\definedalign}{\overset{\phantom{\text{def}}}{=}} \newcommand{\eqeventual}{\overset{\mathclap{\text{\small{eventually}}}}{=}} \newcommand{\Err}{\text{Err}} \newcommand{\expect}[1]{\mathbb{E}[#1]} \newcommand{\expectsq}[1]{\mathbb{E}^2[#1]} \newcommand{\fw}[1]{\texttt{#1}} \newcommand{\given}{\mid} \newcommand{\green}[1]{\color{green}{#1}} \newcommand{\heads}{\outcome{heads}} \newcommand{\iid}{\overset{\text{\small{iid}}}{\sim}} \newcommand{\lik}{\mathcal{L}} \newcommand{\loglik}{\ell} \newcommand{\mle}{\textsf{ML}} \newcommand{\nimplies}{\;\not\!\!\!\!\implies} \newcommand{\orange}[1]{\color{orange}{#1}} \newcommand{\outcome}[1]{\textsf{#1}} \newcommand{\param}[1]{{\color{purple} #1}} \newcommand{\pgsamplespace}{\{\green{1},\green{2},\green{3},\purp{4},\purp{5},\purp{6}\}} \newcommand{\prob}[1]{P\left( #1 \right)} \newcommand{\purp}[1]{\color{purple}{#1}} \newcommand{\sign}{\text{Sign}} \newcommand{\spacecap}{\; \cap \;} \newcommand{\spacewedge}{\; \wedge \;} \newcommand{\tails}{\outcome{tails}} \newcommand{\Var}[1]{\text{Var}[#1]} \newcommand{\bigVar}[1]{\text{Var}\mkern-4mu \left[ #1 \right]} \]
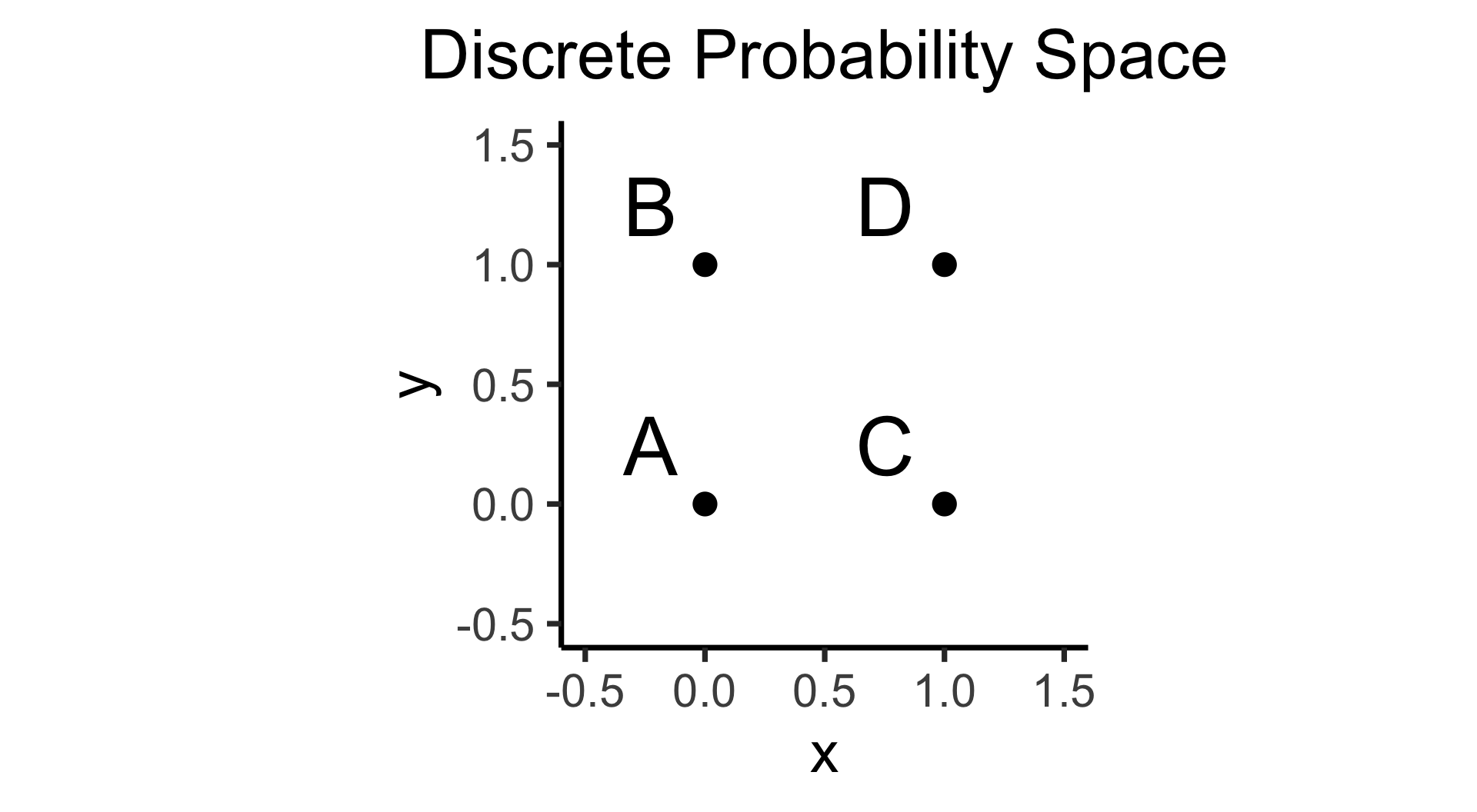
- Discrete = “Easy mode”: Based (intuitively) on sets
- \(\Pr(A)\): Four equally-likely marbles \(\{A, B, C, D\}\) in box, what is probability I pull out \(A\)?
\[ \Pr(A) = \underset{\mathclap{\small \text{Probability }\textbf{mass}}}{\boxed{\frac{|\{A\}|}{|\Omega|}}} = \frac{1}{|\{A,B,C,D\}|} = \frac{1}{4} \]
- Continuous = “Hard mode”: Based (intuitively) on areas
- \(\Pr(A)\): Throw dart at random point in square, what is probability I hit \(\require{enclose}\enclose{circle}{\textsf{A}}\)?
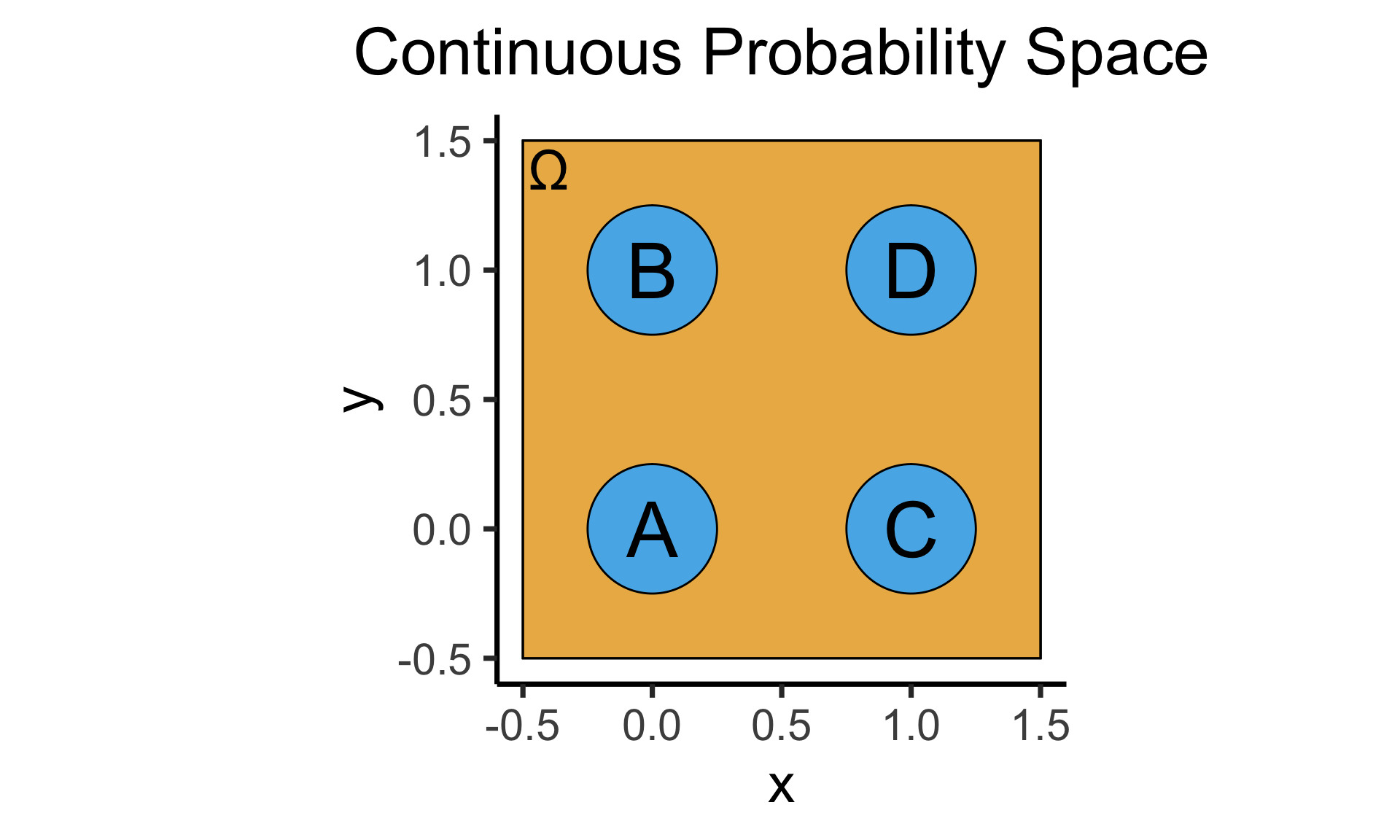
\[ \Pr(A) = \underset{\mathclap{\small \text{Probability }\textbf{density}}}{\boxed{\frac{\text{Area}(\{A\})}{\text{Area}(\Omega)}}} = \frac{\pi r^2}{s^2} = \frac{\pi \left(\frac{1}{4}\right)^2}{4} = \frac{\pi}{64} \]
Moving to Continuous World
- Intuitions from discrete world do translate into good intuitions for continuous world, in this case!
- Can “move” discrete table into continuous space like Riemann sums “move” discrete sums into integrals:

Continuous Joint pdfs
- The volume of this Hershey Kiss is exactly \(1\)
- Integrating over a region \(C\) gives us
\[ \frac{\text{Volume}(\{(X,Y) \mid (X,Y) \in C\})}{\text{Volume}(\text{Hershey Kiss})} = \Pr((X,Y) \in C) \]

Figure 3.11 from DeGroot and Schervish (2013)
Conditional pdfs
- Now, if we learn that \(Y = y_0\), can take “slice” at \(y = y_0\)
- Total area of this slice is not \(1\), so \(f_{X,Y}(x, y_0)\) is not a valid pdf
- Dividing by total area of slice would generate valid pdf. What is this area? \(f_X(y_0)\)
- \(\implies\) \(f_{X \mid Y = y_0}(x \mid y_0) = \frac{f_{X,Y}(x, y_0)}{f_X(y_0)}\) is valid (conditional) pdf

Figure 3.20 from DeGroot and Schervish (2013)
The Truncated Normal Distribution
- \(\ddot{\mathcal{N}}\) may look scary, but \(X \sim \ddot{\mathcal{N}}(\mu, \sigma, a, b)\) just means \(X\) can be constructed as:
\[ X \sim \mathcal{N}(\mu, \sigma) \leadsto [X \mid a < X < b] \sim \ddot{\mathcal{N}}(\mu, \sigma, a, b) \]
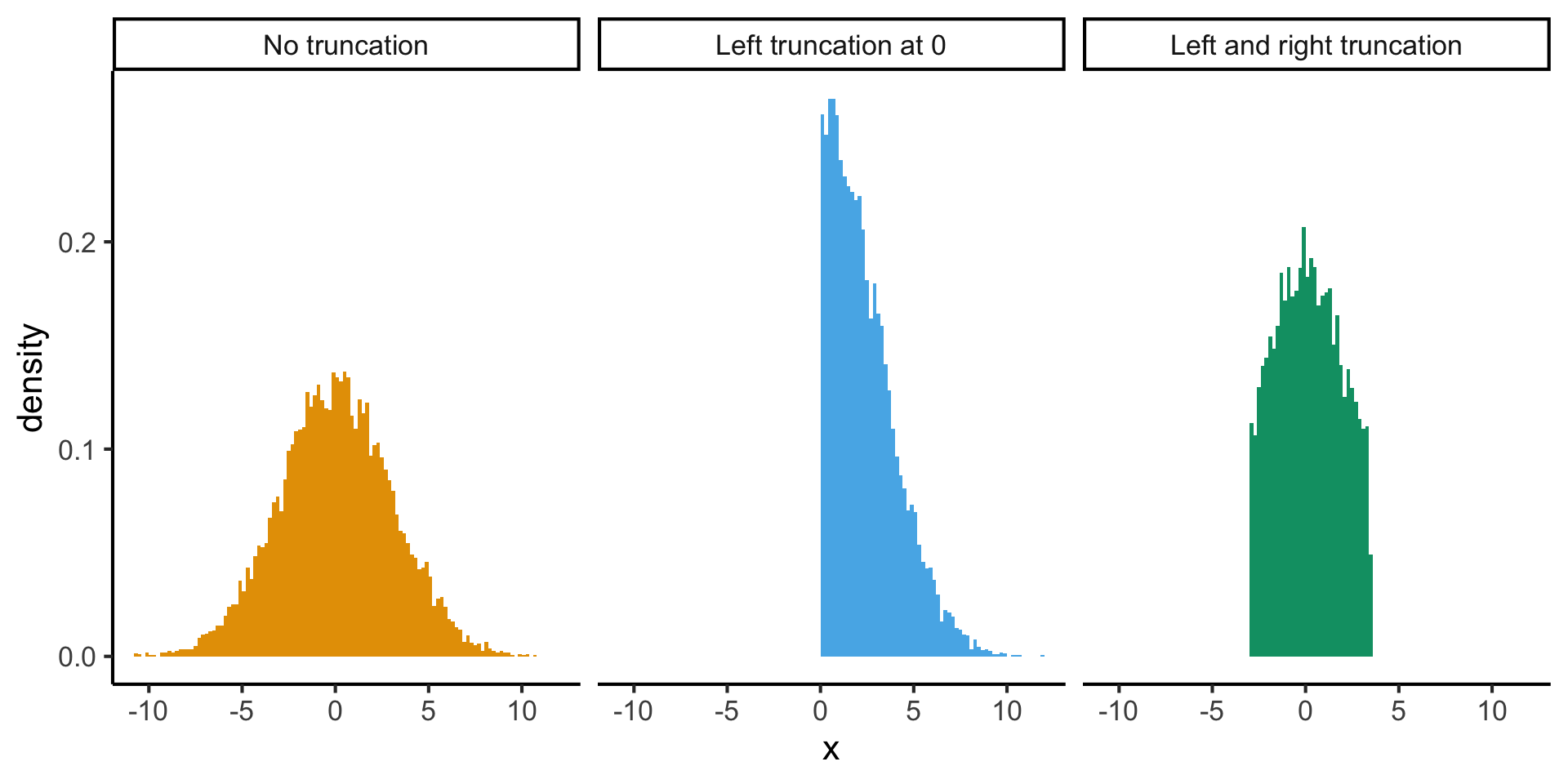
Adapted from simstudy package documentation
A Concrete Strategy
- Start by discretizing (“binning”) the possible values of a continuous RV to obtain a discrete RV:
- Split \([10,12]\) into three equal-length bins, \([0,1]\) into two equal-length bins
- Simulate \((G, H)\) pairs, sort into bins, plot joint / marginal / conditional distributions of binned data
- As you make bins thinner and thinner… 🤔