```{python}from pyspark.sql.functions import udffrom pyspark.sql.types import LongType# define the function that can be tested locallydef squared(s):return s * s# wrap the function in udf for spark and define the output typesquared_udf = udf(squared, LongType())# execute the udfdf = spark.table("test")display(df.select("id", squared_udf("id").alias("id_squared")))```
Using Spark SQL functions before jumping into UDFs
Save to serialized data formats like Parquet
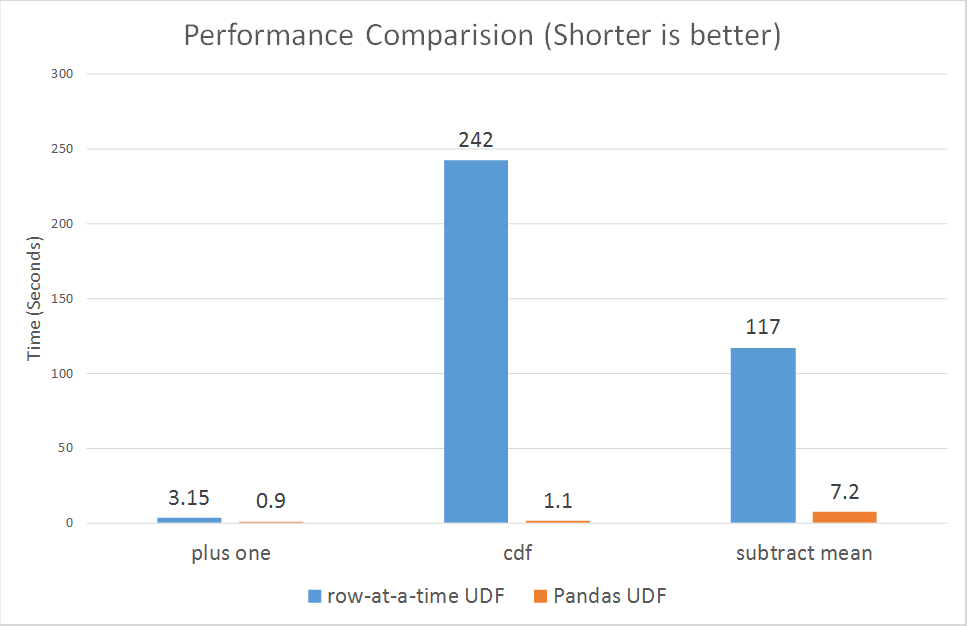
Pandas UDF
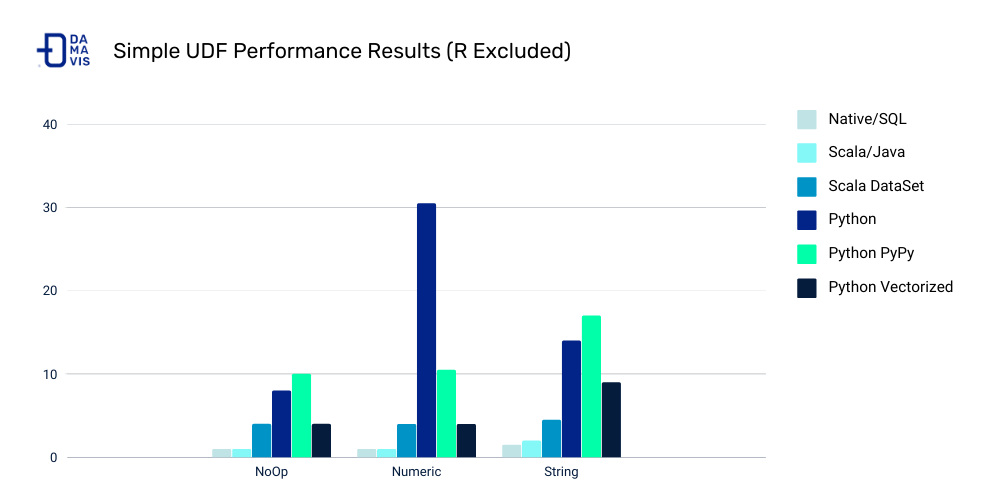
From PySpark docs - Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and Pandas to work with the data, which allows vectorized operations. A Pandas UDF is defined using the pandas_udf as a decorator or to wrap the function, and no additional configuration is required. A Pandas UDF behaves as a regular PySpark function API in general.
Pandas UDF needs to have same size input and output series
UDF Form
```{python}from pyspark.sql.functions import udf# Use udf to define a row-at-a-time udf@udf('double')# Input/output are both a single double valuedef plus_one(v):return v +1df.withColumn('v2', plus_one(df.v))```
Pandas UDF Form - faster vectorized form
```{python}from pyspark.sql.functions import pandas_udf, PandasUDFType# Use pandas_udf to define a Pandas UDF@pandas_udf('double', PandasUDFType.SCALAR)# Input/output are both a pandas.Series of doublesdef pandas_plus_one(v):return v +1df.withColumn('v2', pandas_plus_one(df.v))```
```{python}@pandas_udf(df.schema, PandasUDFType.GROUPED_MAP)# Input/output are both a pandas.DataFramedef subtract_mean(pdf):return pdf.assign(v=pdf.v - pdf.v.mean())df.groupby('id').apply(subtract_mean)```