[1, 4, 4]Week 6: Introduction to Spark
DSAN 6000: Big Data and Cloud Computing
Fall 2025
Monday, September 29, 2025
The “Killer Application”: Matrix Multiplication
- (I learned from Jeff Ullman, who did the obnoxious Stanford thing of mentioning in passing how “two previous students in the class did this for a cool final project on web crawling and, well, it escalated quickly”, aka became Google)

From Leskovec et al. (2014), which is (legally) free online!
If Everything Doesn’t Fit on CPU…
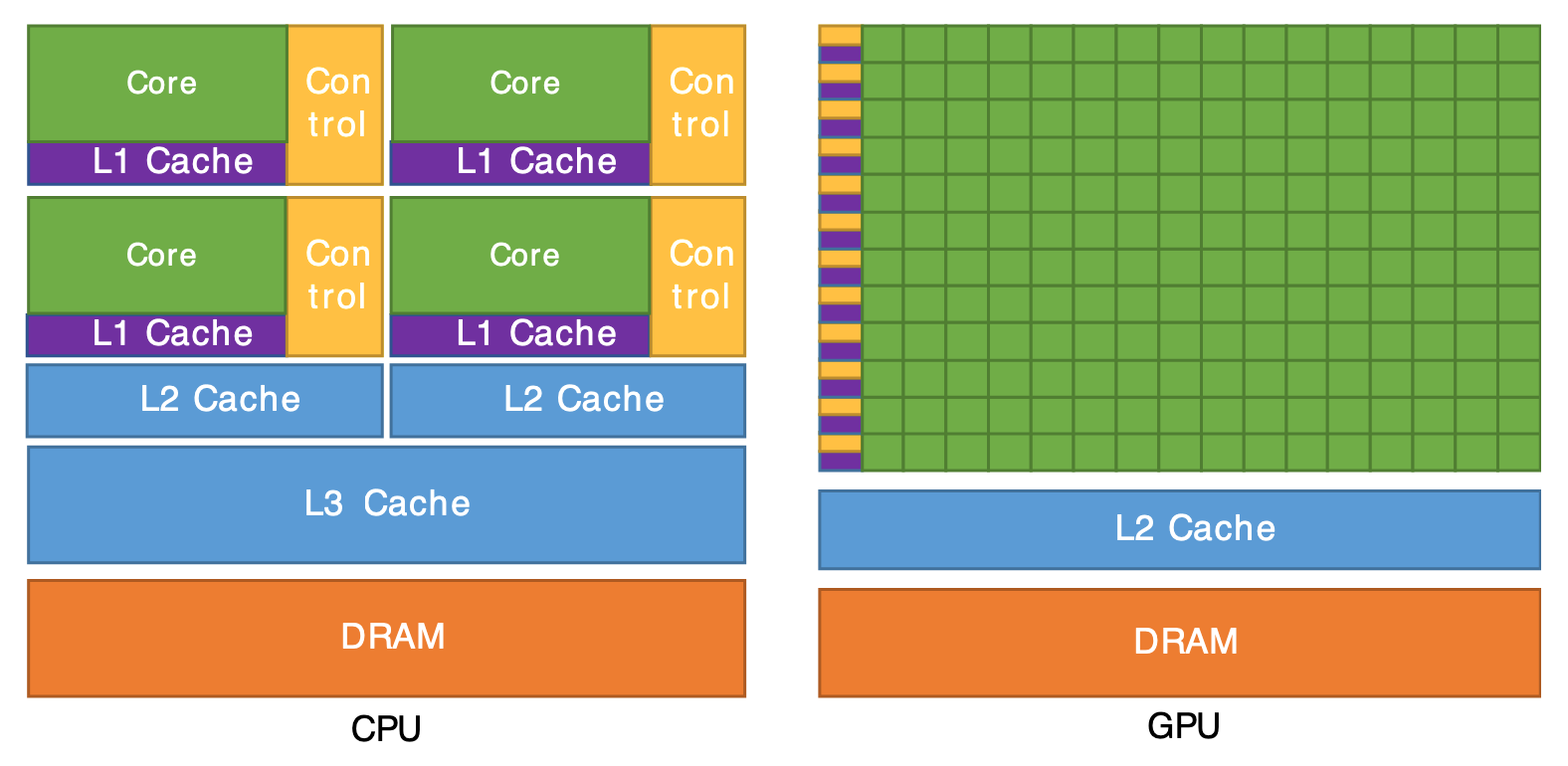
From Cornell Virtual Workshop, “Understanding GPU Architecture”
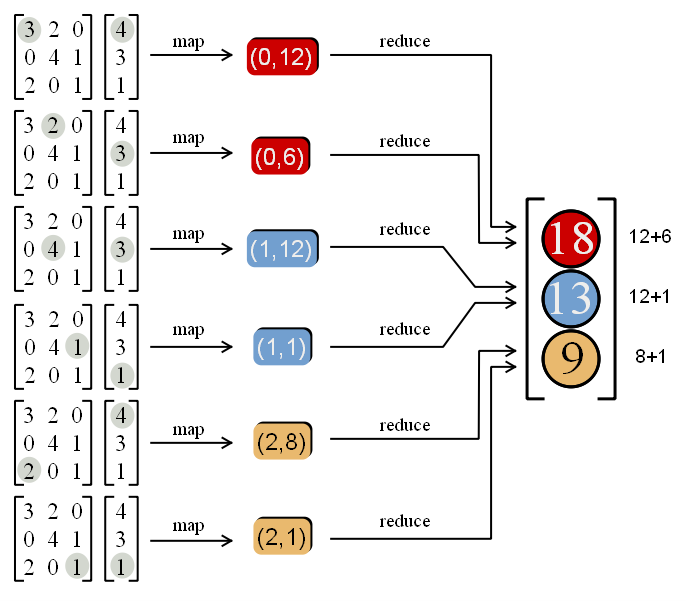
In-Class Demo 1
In-Class Demo 2
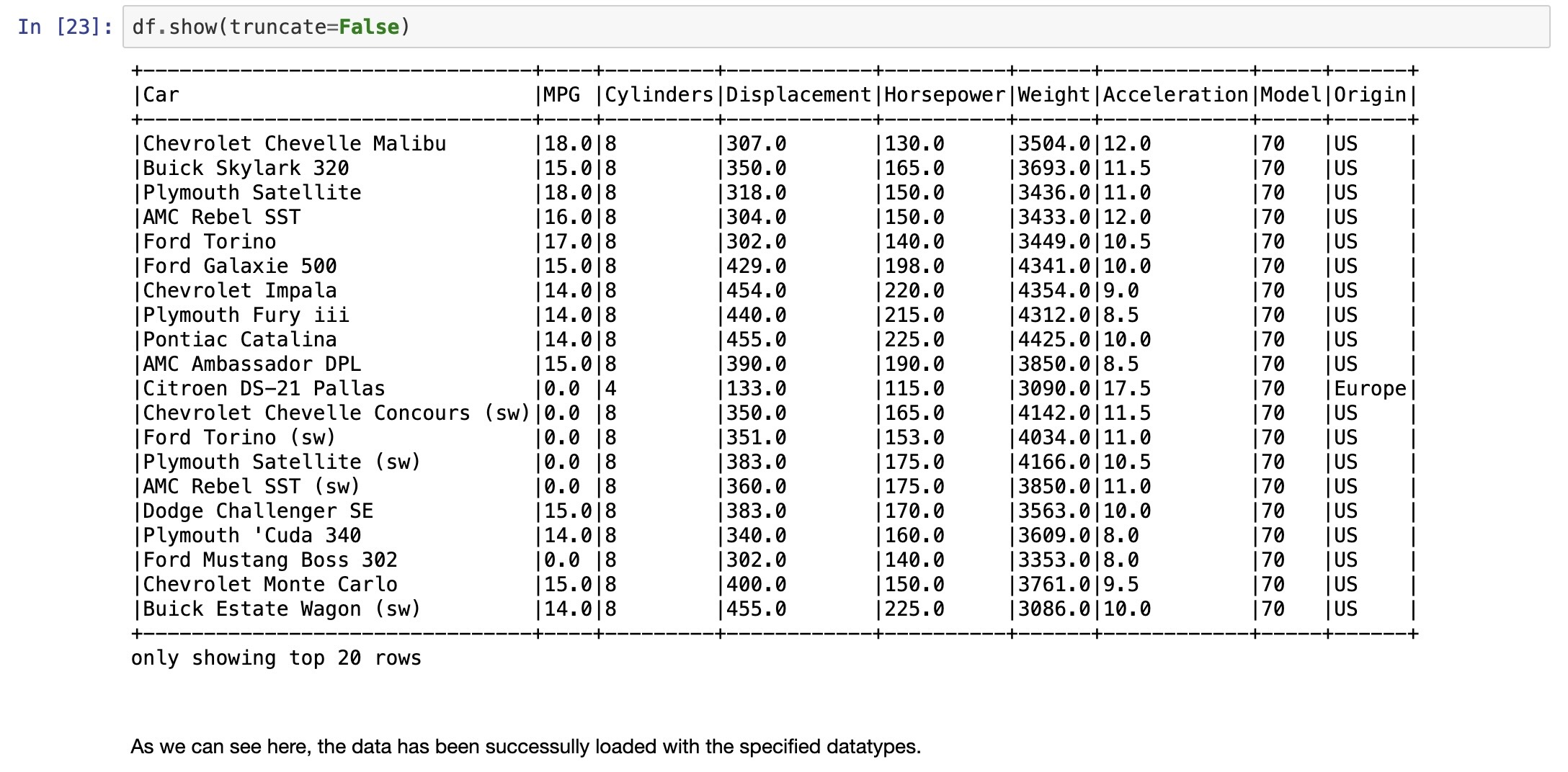
In-Class Demo 3
