Week 3: Parallelization Concepts
DSAN 6000: Big Data and Cloud Computing
Fall 2025
Monday, September 8, 2025
Looking back
- Continued great use of Slack!
- Nice interactions
- Due date reminders:
- Assignment 2: September 17, 2025
- Lab 3: September 17, 2025
- Assignment 3: September 24, 2025
Glossary
| Term | Definition |
|---|---|
| Local | Your current workstation (laptop, desktop, etc.), wherever you start the terminal/console application. |
| Remote | Any machine you connect to via ssh or other means. |
| EC2 | Single virtual machine in the cloud where you can run computation |
| SageMaker | Integrated Developer Environment where you can conduct data science on single machines or distributed training |
| GPU | Graphics Processing Unit - specialized hardware for parallel computation, essential for AI/ML |
| TPU | Tensor Processing Unit - Google’s custom AI accelerator chips |
| Ephemeral | Lasting for a short time - any machine that will get turned off or place you will lose data |
| Persistent | Lasting for a long time - any environment where your work is NOT lost when the timer goes off |
Parallelization in General
Quick Survey Question, for Intuition-Building
- Are humans capable of “true” multi-tasking?
- As in, doing two things at the exact same time?
- (Or, do we instead rapidly switch back and forth between tasks?)
The Answer
- (From what we understand, at the moment, by way of studies in neuroscience/cognitive science/etc…)
- Humans are not capable of true multitasking! In CS terms, this would be called multiprocessing (more on this later)
- We are capable, however, of various modes of concurrency!
| Multithreading | Asynchronous Execution | |
|---|---|---|
| Unconsciously (you do it already, “naturally”) |
Focus on one speaker within a loud room, with tons of other conversations entering your ears | Put something in oven, set alarm, go do something else, take out of oven once alarm goes off |
| Consciously (you can do it with effort/practice) |
Pat head (up and down) and rub stomach (circular motion) “simultaneously” | Throw a ball in the air, clap 3 times, catch ball |
Helpful Specifically for Programming
- Course notes from MIT’s class on parallel computing phrases it like: if implemented thoughtfully, concurrency is a power multiplier for your code (do 10 things in 1 second instead of 10 seconds…)

Helpful In General as a Way of Thinking!
- Say you get hired as a Project Manager…
- Part of your job will fundamentally involve pipelines!
- Need to know when Task \(B\) does/does not require Task \(A\) as a prerequisite
- Need to know whether Task \(A\) and Task \(B\) can share one resource or need their own individual resources
- Once Task \(A\) and \(B\) both complete, how do we merge their results together?
Avoiding the Rabbithole
- Parallel computing is a rabbithole, but one you can safely avoid via simple heuristics (“rules of thumb”)!
- Check for optimizations to serial code first,
- Check for embarrassingly parallel code blocks
- Use map-reduce approach for more complicated cases
Typical Real-World Scenarios
- You need to prepare training data for LLMs by cleaning and deduplicating 100TB of web-scraped text
- You are building a RAG system that requires embedding and indexing millions of documents in parallel
- You need to extract structured data from millions of PDFs using vision models for document AI
- You are preprocessing multimodal datasets with billions of image-text pairs for foundation model training
- You need to run quality filtering on petabytes of Common Crawl data for training dataset
- You are generating synthetic training data using LLMs to augment limited real-world datasets
- You need to transform and tokenize text across 100+ languages for multilingual AI
- You are building real-time data pipelines that process streaming data for online learning
“Embarrassingly Parallel” Pipelines
- Technical definition: tasks within pipeline can easily be parallelized bc no dependence and no need for communication (triple spatula!)
Parallelizing Non-Embarrassingly-Parallel Pipelines

Buzzkill: Complications to Come 😰
- If it’s such a magical powerup, shouldn’t we just parallelize everything? Answer: No 😞 bc overhead.
- Overhead source 1: Sending tasks to workers (processors), collecting results
- Overhead source 2: Even after setting up new stacks and heaps, threads may need to communicate with each other (e.g. if they need to synchronize at some point(s))
- In fact, probably the earliest super-popular parallelization library was created to handle Source 2, not Source 1: Message Passing Interface (C, C++, and Fortran)
Rules of Thumb for Parallelization
Yes - Parallelize These
Data Preparation:
- Text extraction from documents
- Tokenization of text corpora
- Image preprocessing
- Embedding generation for documents
- Data quality filtering and validation
- Format conversions (audio features)
- Web scraping and data collection
- Synthetic data generation
Data Processing:
- Batch inference on datasets
- Feature extraction at scale
- Data deduplication (local)
No - Keep Sequential
Order-Dependent:
- Conversation threading
- Time-series preprocessing
- Sequential data validation
- Cumulative statistics
Global Operations:
- Global deduplication
- Cross-dataset joins
- Computing exact quantiles
For data operations in the “No” column, they often require global coordination or maintain strict ordering. However, many can be approximated with parallel algorithms (like approximate deduplication with locality-sensitive hashing)
In Action
Beyond Embarrassingly Parallel Tasks…
What Happens When Not Embarrassingly Parallel?
- Think of the difference between linear and quadratic equations in algebra:
- \(3x - 1 = 0\) is “embarrassingly” solvable, on its own: you can solve it directly, by adding 3 to both sides \(\implies x = \frac{1}{3}\). Same for \(2x + 3 = 0 \implies x = -\frac{3}{2}\)
- Now consider \(6x^2 + 7x - 3 = 0\): Harder to solve “directly”, so your instinct might be to turn to the laborious quadratic equation:
\[ \begin{align*} x = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a} = \frac{-7 \pm \sqrt{49 - 4(6)(-3)}}{2(6)} = \frac{-7 \pm 11}{12} = \left\{\frac{1}{3},-\frac{3}{2}\right\} \end{align*} \]
- And yet, \(6x^2 + 7x - 3 = (3x - 1)(2x + 3)\), meaning that we could have split the problem into two “embarrassingly” solvable pieces, then multiplied to get result!
The Analogy to Map-Reduce
| \(\leadsto\) If code is not embarrassingly parallel (instinctually requiring laborious serial execution), | \(\underbrace{6x^2 + 7x - 3 = 0}_{\text{Solve using Quadratic Eqn}}\) |
| But can be split into… | \((3x - 1)(2x + 3) = 0\) |
| Embarrassingly parallel pieces which combine to same result, | \(\underbrace{3x - 1 = 0}_{\text{Solve directly}}, \underbrace{2x + 3 = 0}_{\text{Solve directly}}\) |
| We can use map-reduce to achieve ultra speedup (running “pieces” on GPU!) | \(\underbrace{(3x-1)(2x+3) = 0}_{\text{Solutions satisfy this product}}\) |
The Direct Analogy: Map-Reduce!
Problem from DSAN 5000/5100: Computing SSR (Sum of Squared Residuals)
\(y = (1,3,2), \widehat{y} = (2, 5, 0) \implies \text{SSR} = (1-2)^2 + (3-5)^2 + (2-0)^2 = 9\)
Computing pieces separately:
Combining solved pieces
Quick Aside: Functional Programming (FP)
Functions vs. Functionals
You may have noticed: map() and reduce() are “meta-functions”: functions that take other functions as inputs
In Python, functions can be used as vars (Hence lambda):
This relates to a whole paradigm, “functional programming”: mostly outside scope of course, but lots of important+useful takeaways/rules-of-thumb!
Train Your Brain for Functional Approach \(\implies\) Master Debugging!
In CS Theory: enables formal proofs of correctness
In CS practice:
When a program doesn’t work, each function is an interface point where you can check that the data are correct. You can look at the intermediate inputs and outputs to quickly isolate the function that’s responsible for a bug.
(from Python’s “Functional Programming HowTo”)
Code \(\rightarrow\) Pipelines \(\rightarrow\) Debuggable Pipelines
- Scenario: Run code, check the output, and… it’s wrong 😵 what do you do?
- Usual approach: Read lines one-by-one, figuring out what they do, seeing if something pops out that seems wrong; adding comments like
# Convert to lowercase
Easy case: found typo in punctuation removal code. Fix the error, add comment like
# Remove punctuationRule 1 of FP: transform these comments into function names
Hard case: Something in
load_text()modifies a variable that later on breaksremove_punct()(Called a side-effect)Rule 2 of FP: NO SIDE-EFFECTS!
- With side effects: ❌ \(\implies\) issue is somewhere earlier in the chain 😩🏃♂️
- No side effects: ❌ \(\implies\) issue must be in
remove_punct()!!! 😎 ⏱️ = 💰
If It’s So Useful, Why Doesn’t Everyone Do It?
- Trapped in imperative (sequential) coding mode: Path dependency / QWERTY
- We need to start thinking like this bc, 1000x harder to debug parallel code! So we need to be less ad hoc in how we write+debug, from here on out! 🙇♂️🙏

From Leskovec et al. (2014)
But… Why is All This Weird Mapping and Reducing Necessary?
- Without knowing a bit more of the internals of computing efficiency, it may seem like a huge cost in terms of overly-complicated overhead, not to mention learning curve…
The “Killer Application”: Matrix Multiplication
- (I learned from Jeff Ullman, who did the obnoxious Stanford thing of mentioning in passing how “two previous students in the class did this for a cool final project on web crawling and, well, it escalated quickly”, aka became Google)

From Leskovec et al. (2014), which is (legally) free online!
The Killer Way-To-Learn: Text Counts!
- (2014): Text counts (2.2) \(\rightarrow\) Matrix multiplication (2.3) \(\rightarrow \cdots \rightarrow\) PageRank (5.1)
- The goal: User searches “Denzel Curry”… How relevant is a given webpage?
- Scenario 1: Entire internet fits on CPU \(\implies\) We can just make a big dict:
If Everything Doesn’t Fit on CPU…
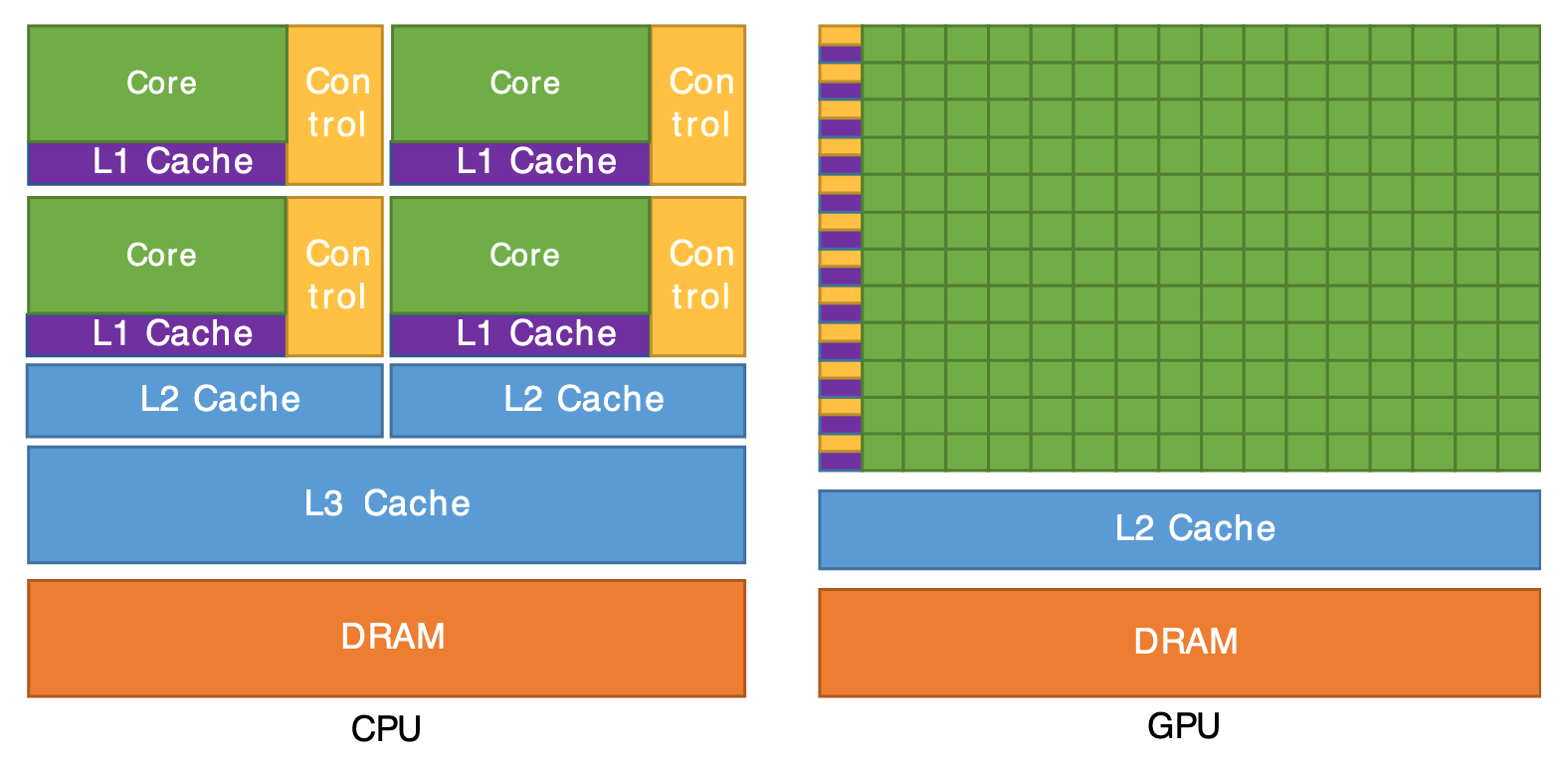
From Cornell Virtual Workshop, “Understanding GPU Architecture”
Break Problem into Chunks for the Green Bois!
- \(\implies\) Total = \(O(3n) = O(n)\)
- But also optimized in terms of constants, because of sequential memory reads
Lab Time!
References
DSAN 6000 Week 3: Parallelization Concepts