Week 1: Course Overview
DSAN 6000: Big Data and Cloud Computing
Fall 2025
Thursday, August 28, 2025
Amit Arora, aa1603@georgetown.edu
- Principal Solutions Architect - AI/ML at AWS
- Adjunct Professor at Georgetown University
- Multiple patents in telecommunications and applications of ML in telecommunications
Fun Facts

- I am a self-published author https://blueberriesinmysalad.com/
- My book “Blueberries in my salad: my forever journey towards fitness & strength” is written as code in R and Markdown
- I love to read books about health and human performance, productivity, philosophy and Mathematics for ML. My reading list is online!
Jeff Jacobs, jj1088@georgetown.edu
- Full-time Professor at Georgetown (DSAN and Public Policy)
- Background in Computational Social Science (Comp Sci MS → Political Economy PhD → Labor Econ Postdoc)
Fun Facts
- Used Apache Airflow daily for PhD projects! (Example)

- Server admin for lab server → lab AWS account at Columbia (2015-2023) → new DSAN server (!) (2025-)
- Passion project 1: Code for Palestine (2015-2022) → YouthCode-Gaza (2023) → Ukraine Ministry of Digital Transformation (2024)
- Passion projects 2+3 [🤓]: Sample-based music production, web app frameworks
- Sleep disorder means lots of reading – mainly history! – at night
- Also teaching PPOL6805 / DSAN 6750: GIS for Spatial Data Science this semester
Binhui Chen, bc928@georgetown.edu
(Lead TA for the course!)

Pranav Sudhir Patil, pp755@georgetown.edu

Ofure Udabor, au195@georgetown.edu

Yifei Wu, yw924@georgetown.edu

Naomi Yamaguchi, ny159@georgetown.edu

Leqi Ying, ly290@georgetown.edu

Xinyue (Monica) Zhang, xz646@georgetown.edu

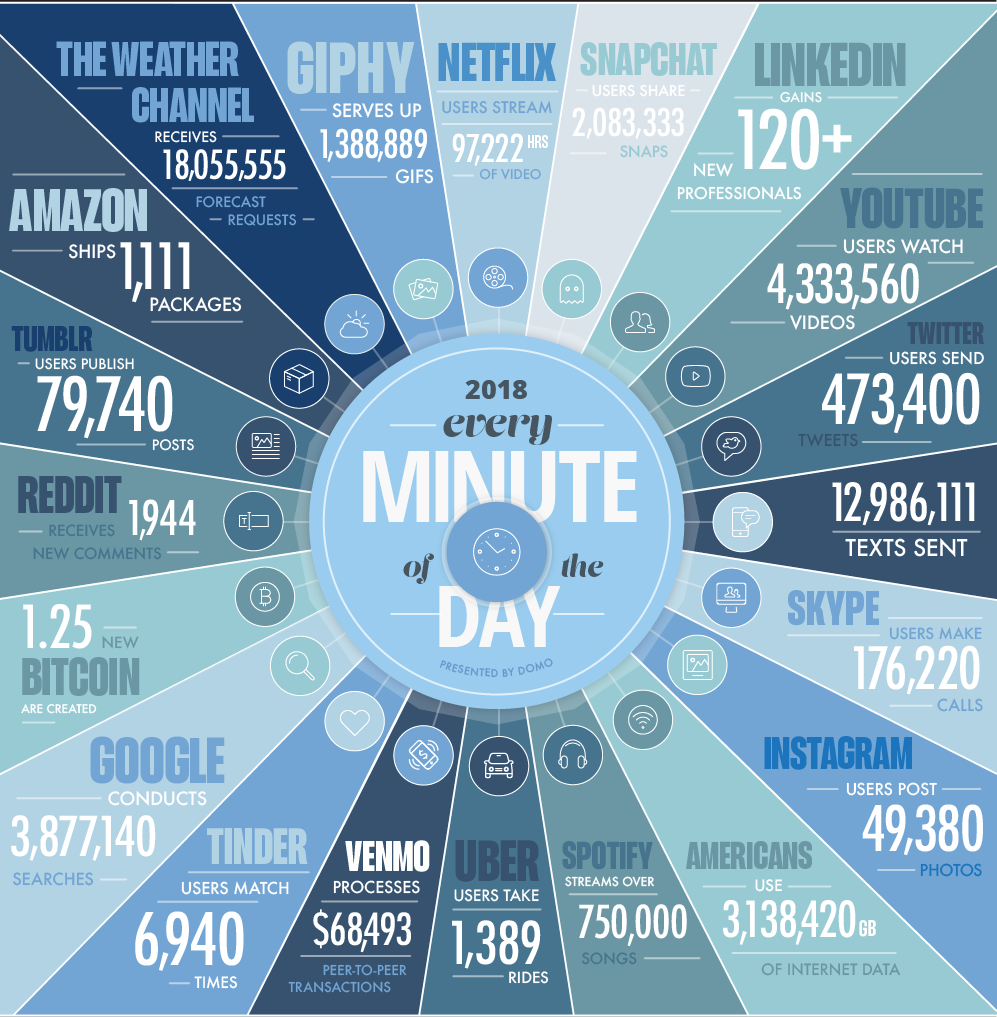
In one minute of time (2018)
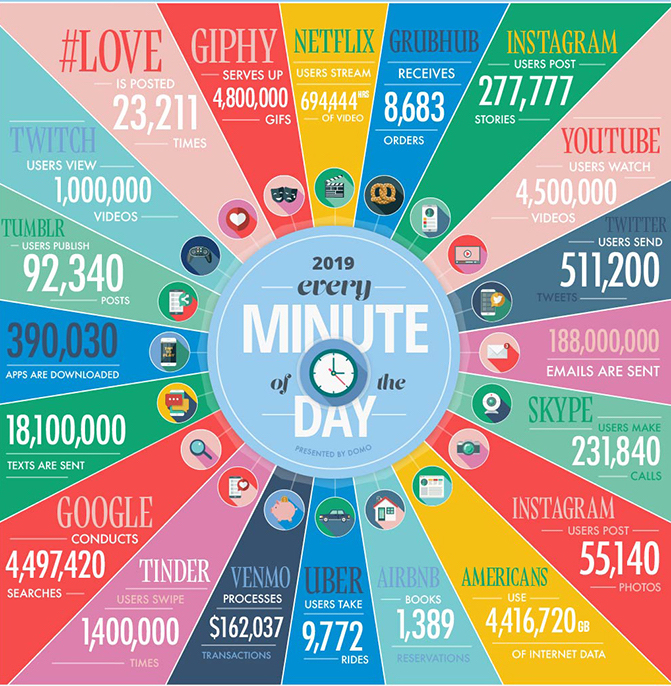
In one minute of time (2019)
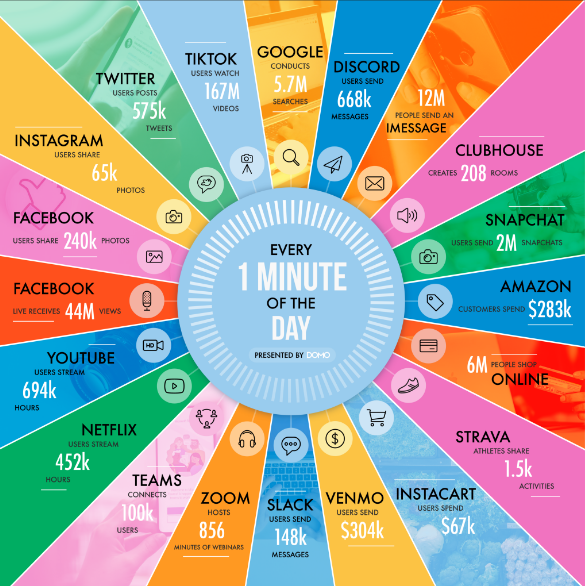
In one minute of time (2020)

In one minute of time (2021)
A lot of it is hapenning online.
We can record every:
- click
- ad impression
- billing event
- video interaction
- server request
- transaction
- network message
- fault
- …

It can also be user-generated content:
- Instagram posts & Reels
- X (Twitter) posts & Threads
- TikTok videos
- YouTube Shorts
- Reddit discussions
- Discord conversations
- AI-generated content (text, images, code)
- …

But health and scientific computing create a lot too!
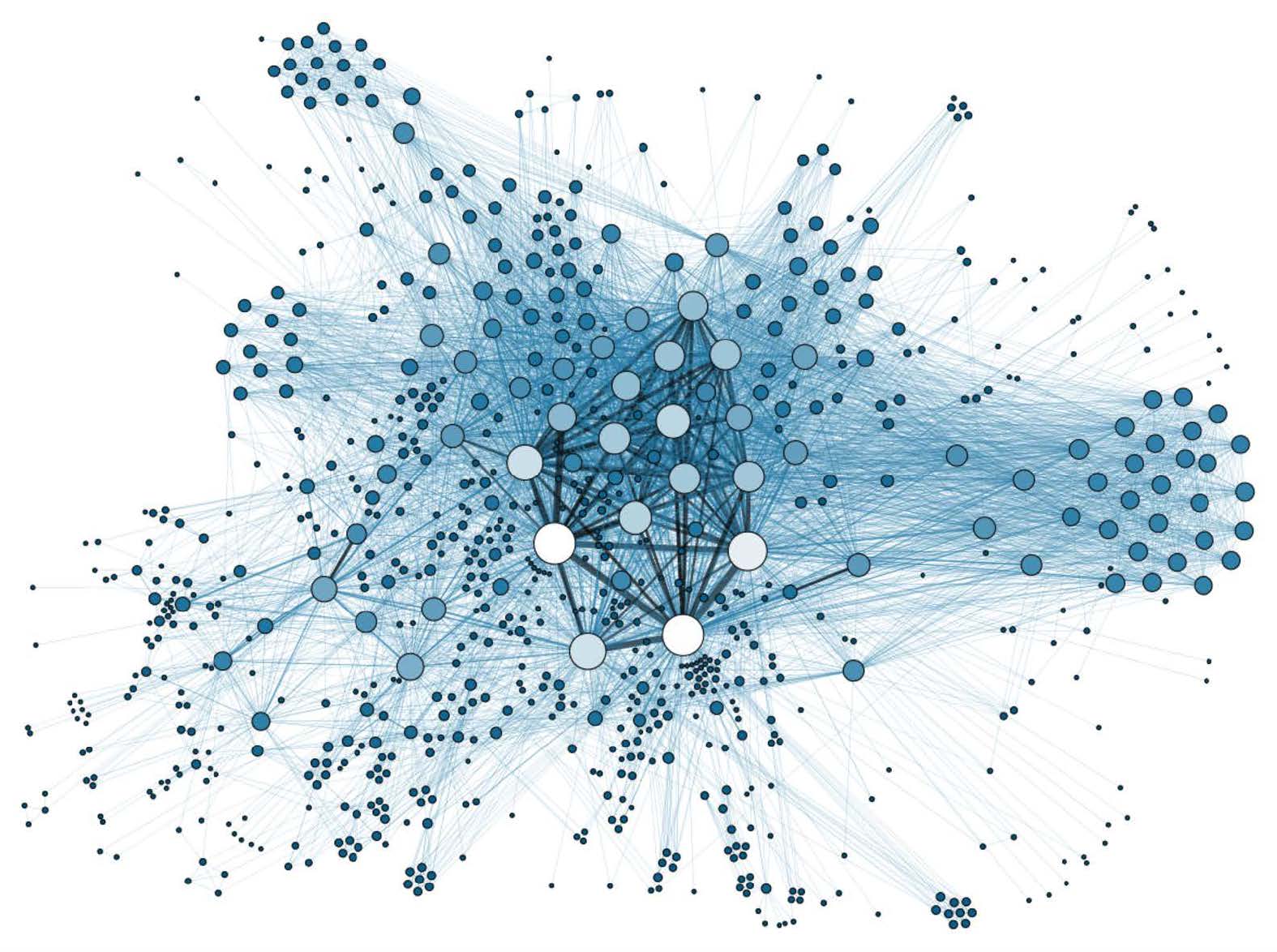
There’s lots of graph data too
Many interesting datasets have a graph structure:
- Social networks
- Google’s knowledge graph
- Telecom networks
- Computer networks
- Road networks
- Collaboration/relationships
Some of these are HUGE
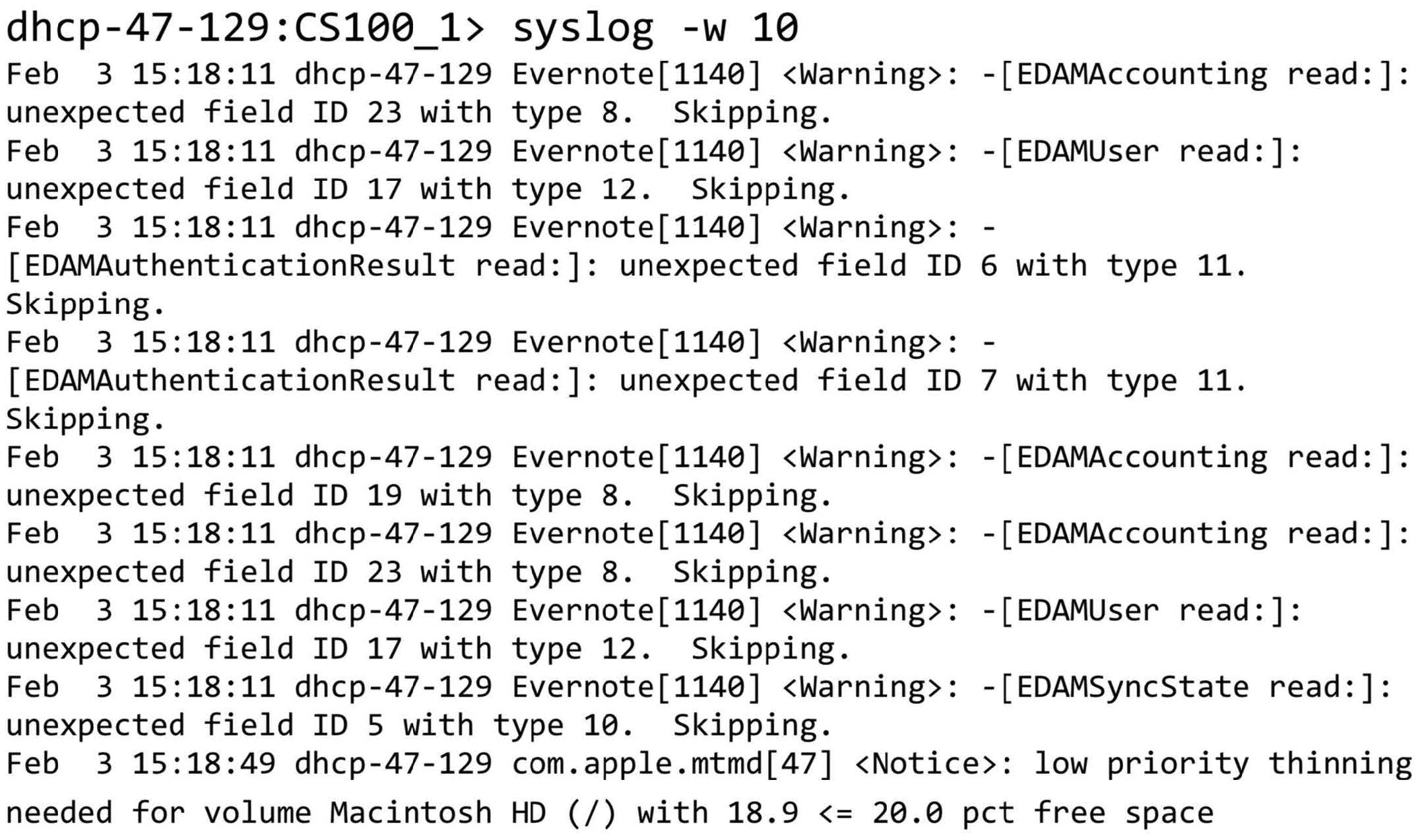
Apache (web server) log files

System log files
Internet of Things (IoT) in 2025
75 billion connected devices generating data:
- Smart home devices (Alexa, Google Home, Apple HomePod)
- Wearables (Apple Watch, Fitbit, Oura rings)
- Connected vehicles & self-driving cars
- Industrial IoT sensors
- Smart city infrastructure
- Medical devices & remote patient monitoring
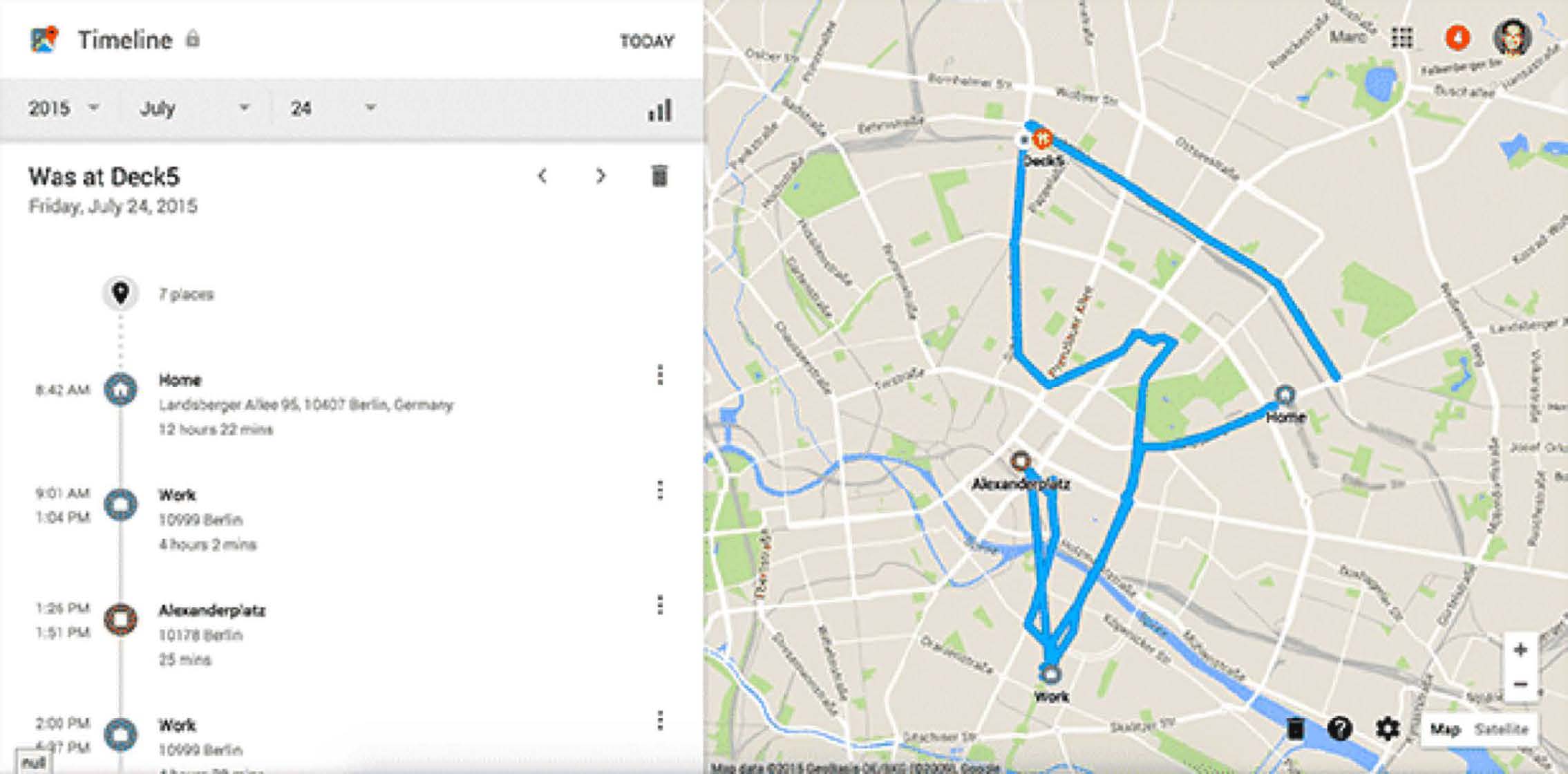
Smartphone Location Data
Let’s discuss!
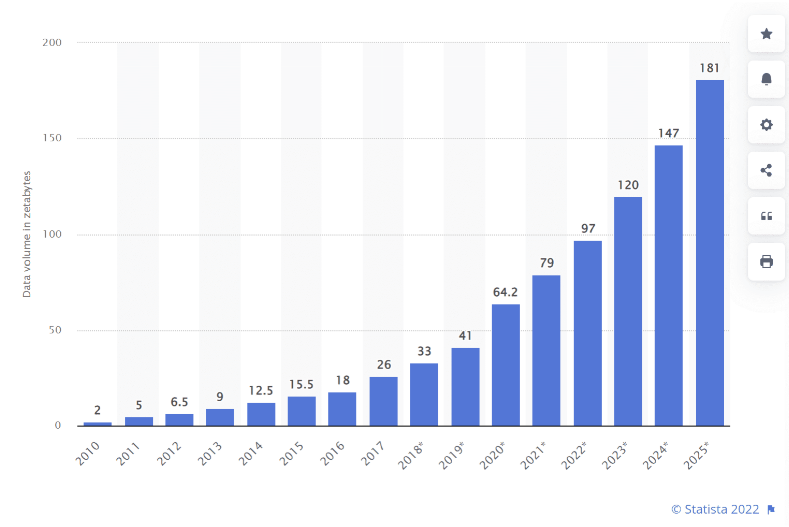
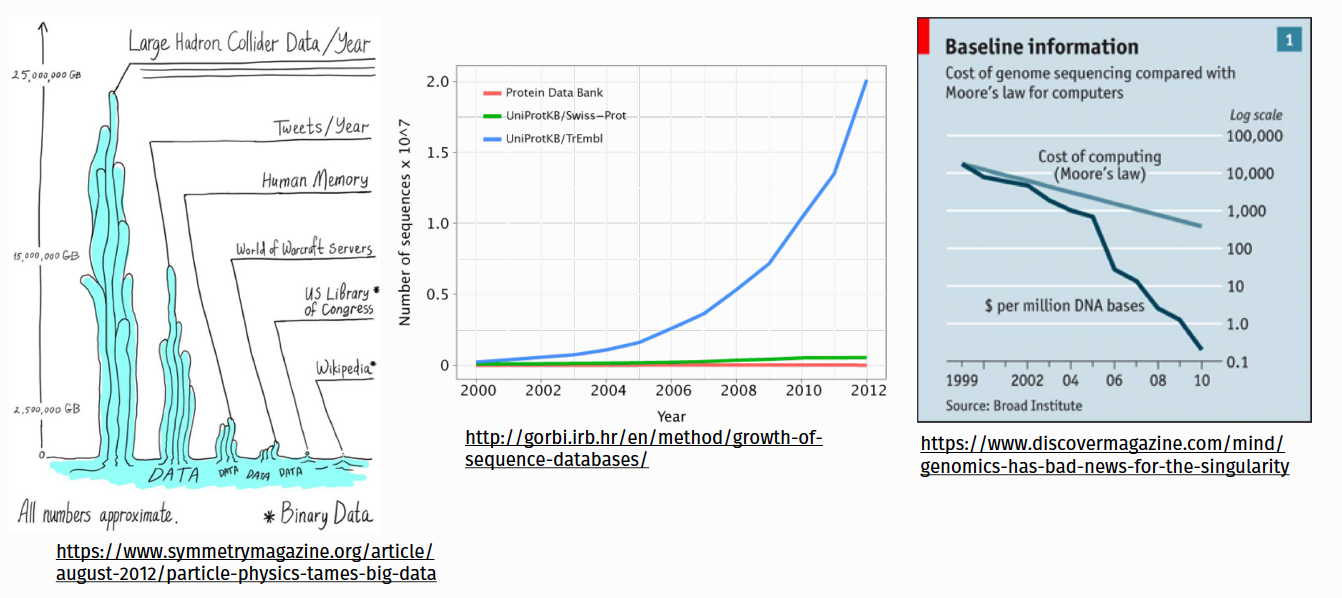
Exponential data growth
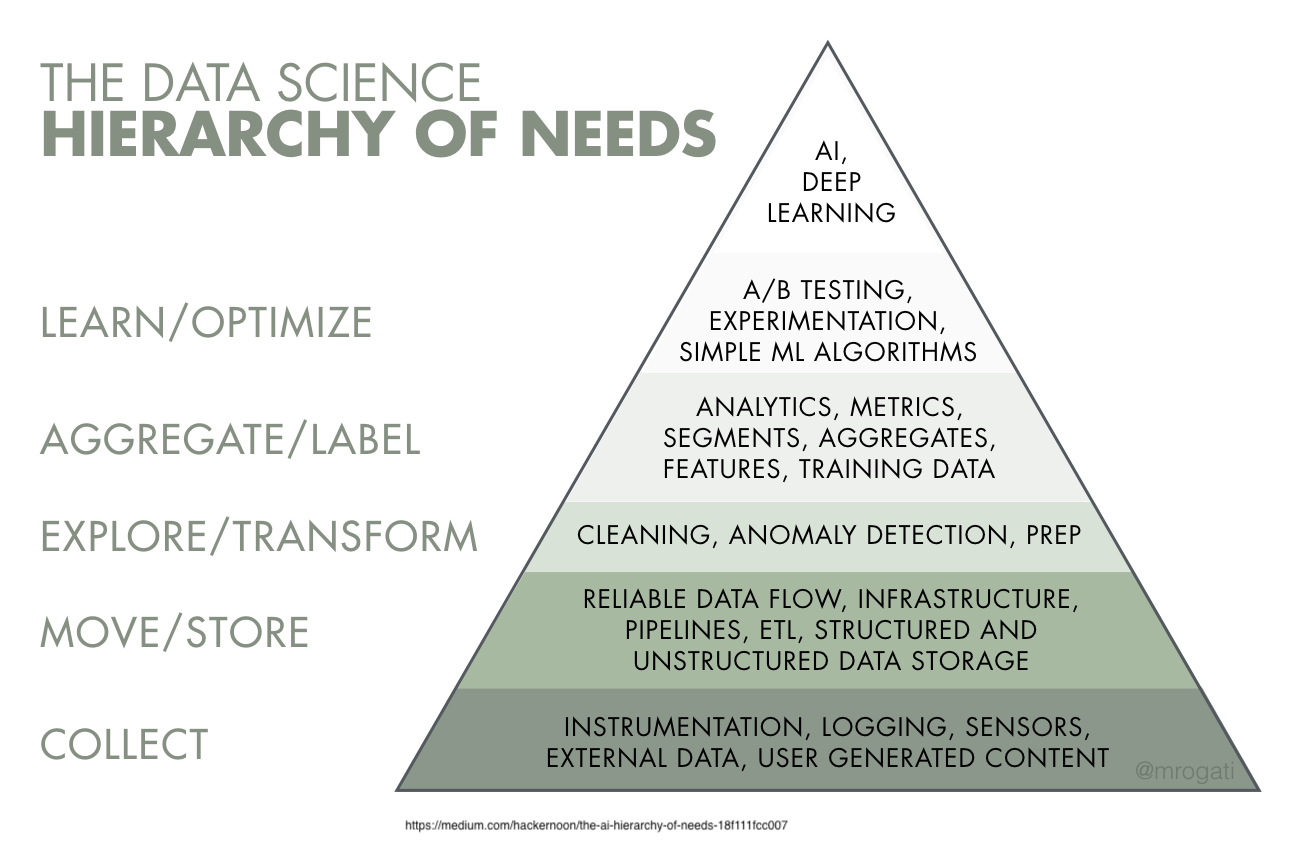
Data Scientist vs. Data Engineer
In this course, you’ll augment your data scientist skills with data engineering skills!

Data Engineer Responsibilities

Data Engineering: Levels 2 and 3
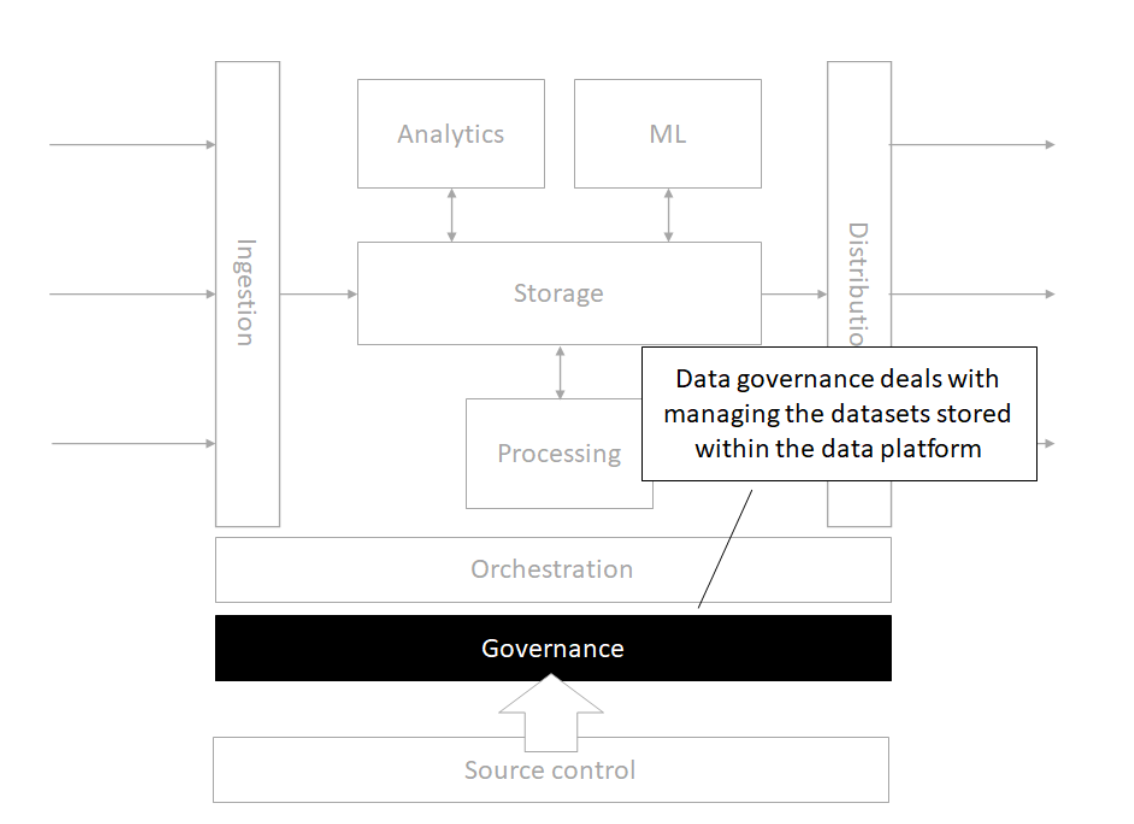
Architecture
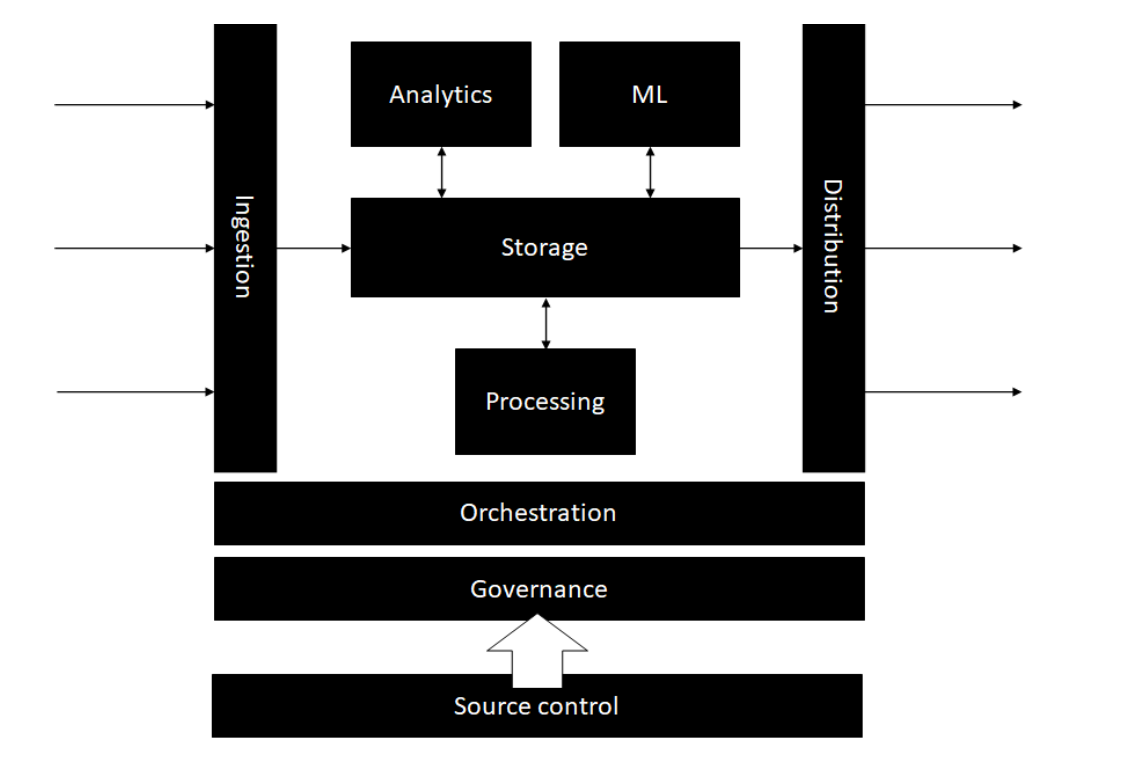
Storage
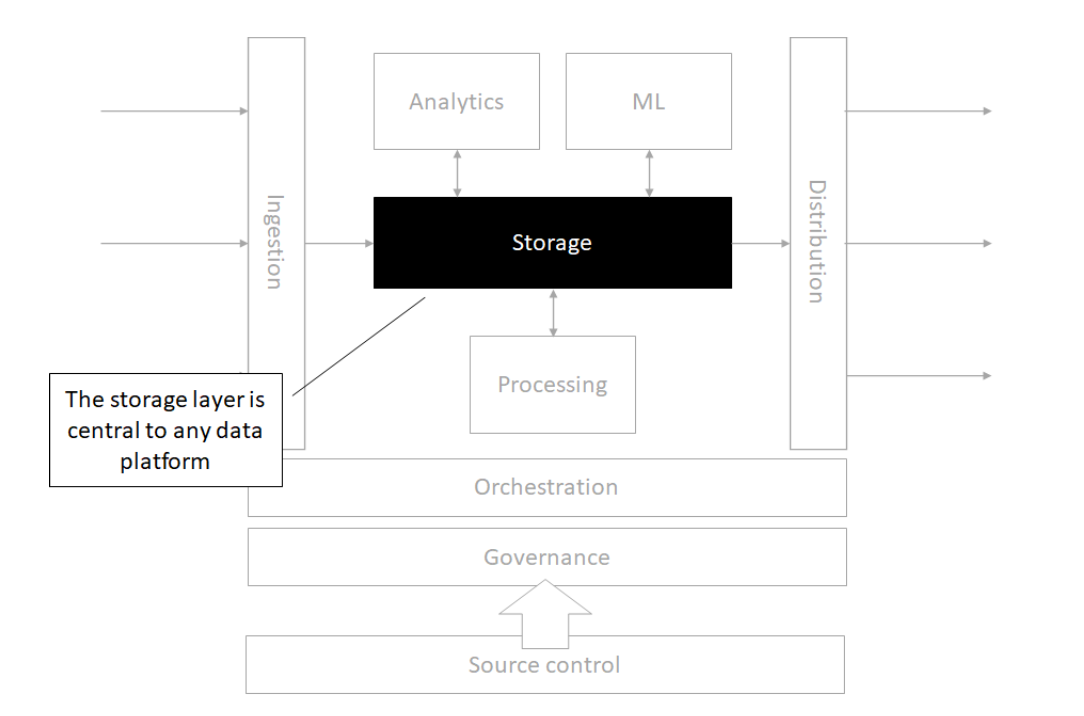
Source control
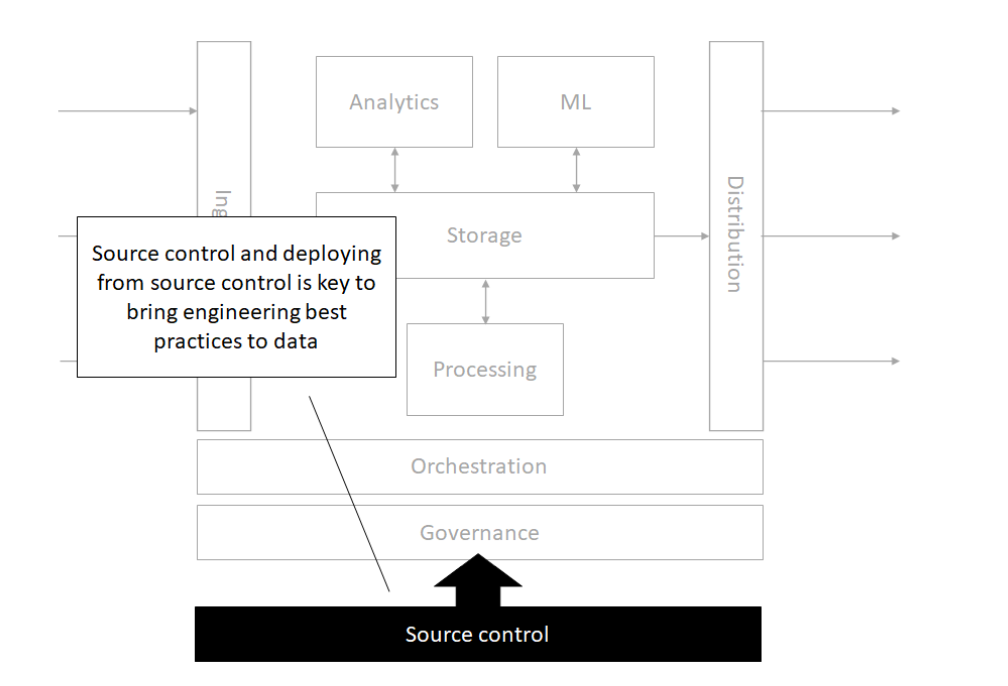
Orchestration
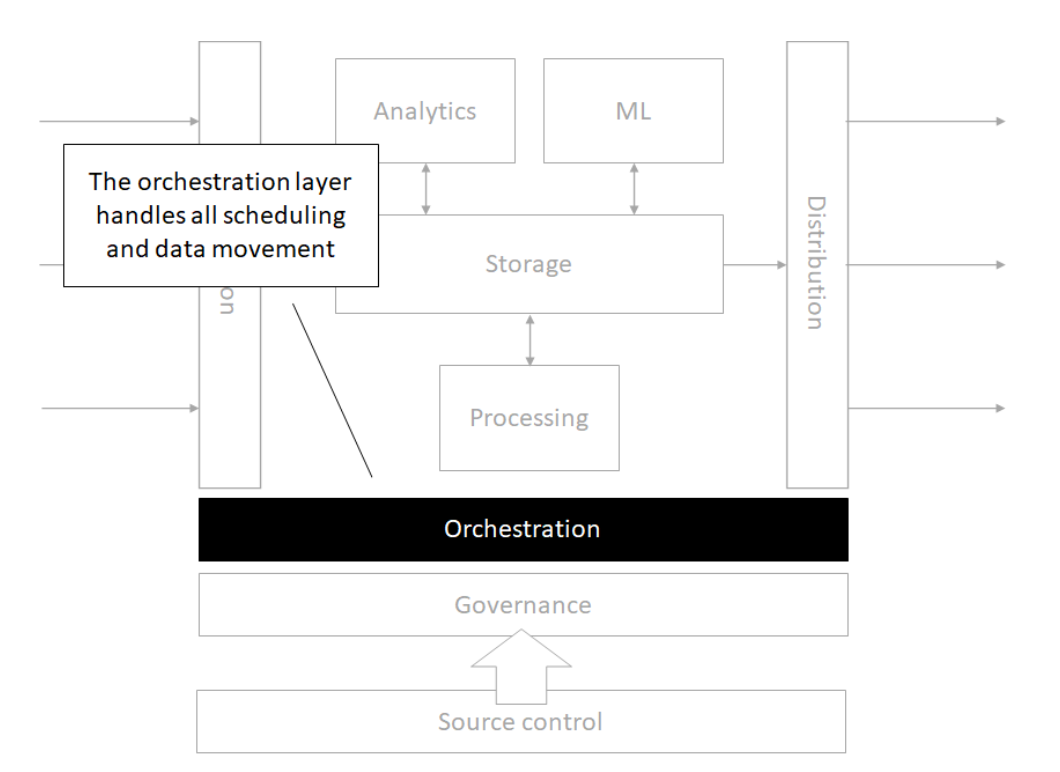
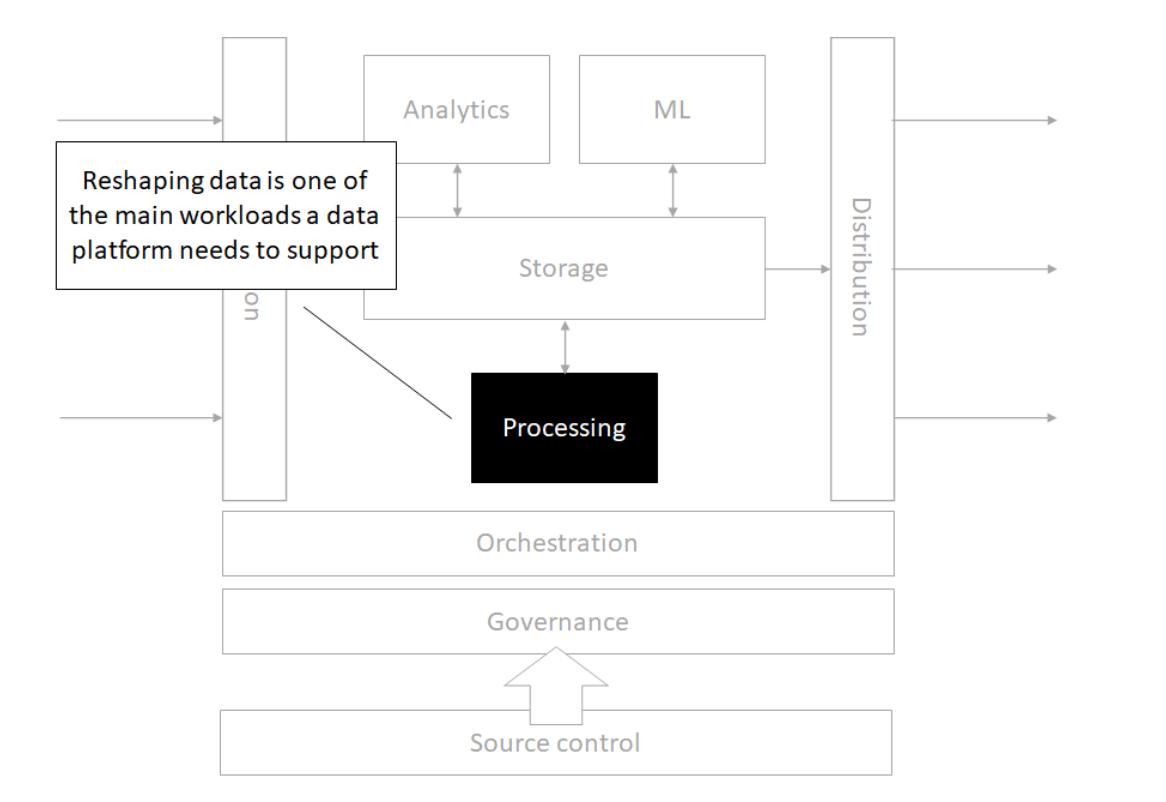
Processing
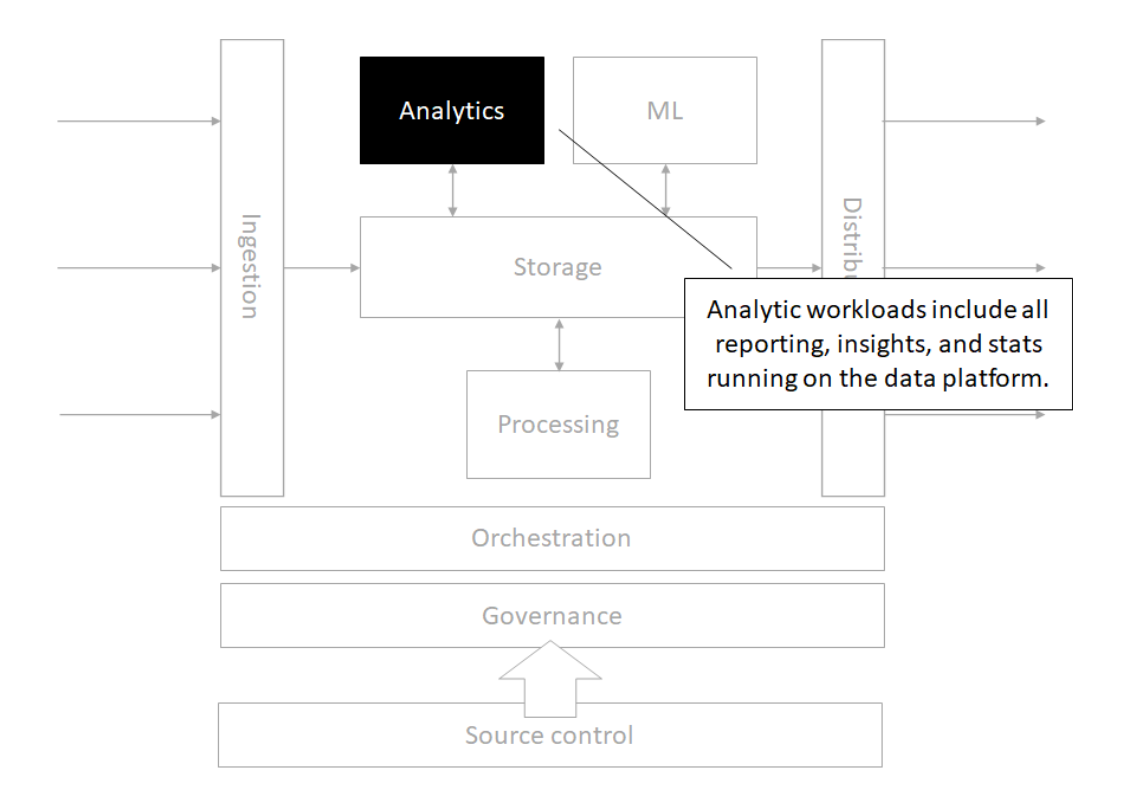
Analytics
Machine Learning
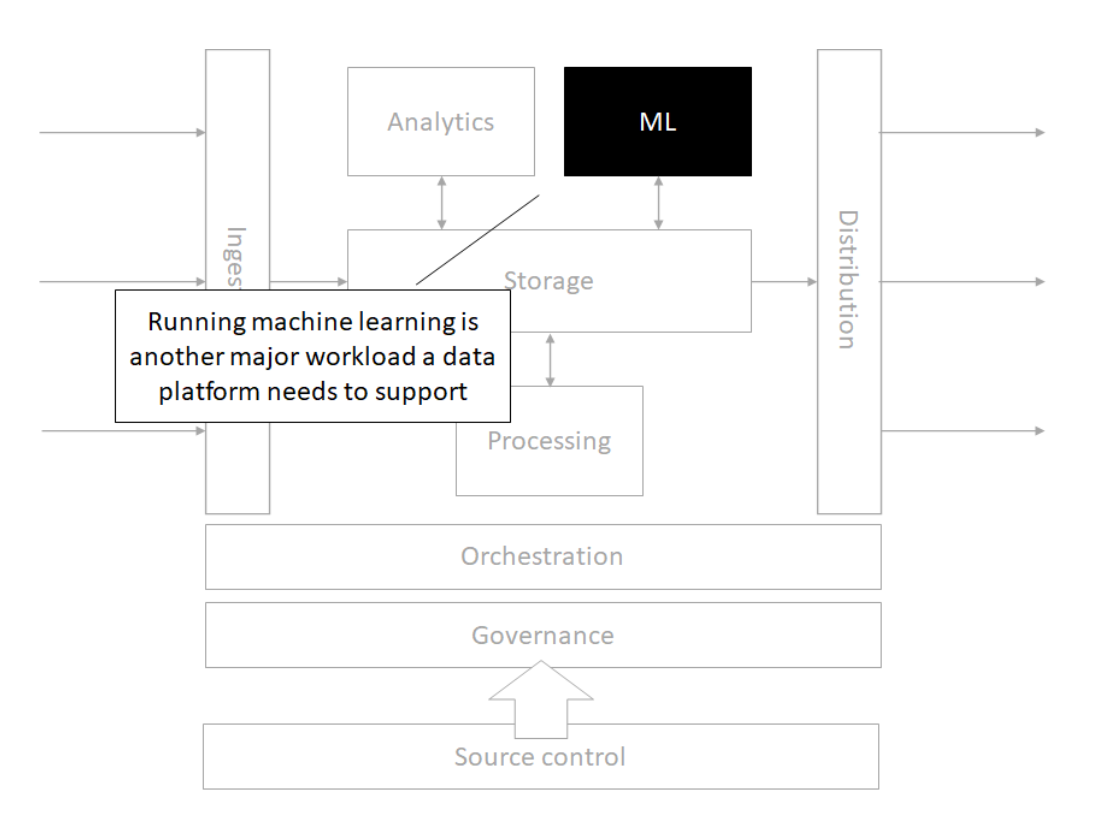
Governance
The Terminal
- Terminal access was THE ONLY way to do programming
- No GUIs! No Spyder, Jupyter, RStudio, etc.
- Coding is still more powerful than graphical interfaces for complex jobs
- Coding makes work repeatable
BASH
- Created in 1989 by Brian Fox: “Bourne-Again Shell”
- Brian Fox also built the first online interactive banking software
- BASH is a command processor
- Connection between you and the machine language and hardware
