Week 8: Ecological Inference, Propensity Scores
DSAN 5650: Causal Inference for Computational Social Science
Summer 2026, Georgetown University
Wednesday, July 8, 2026
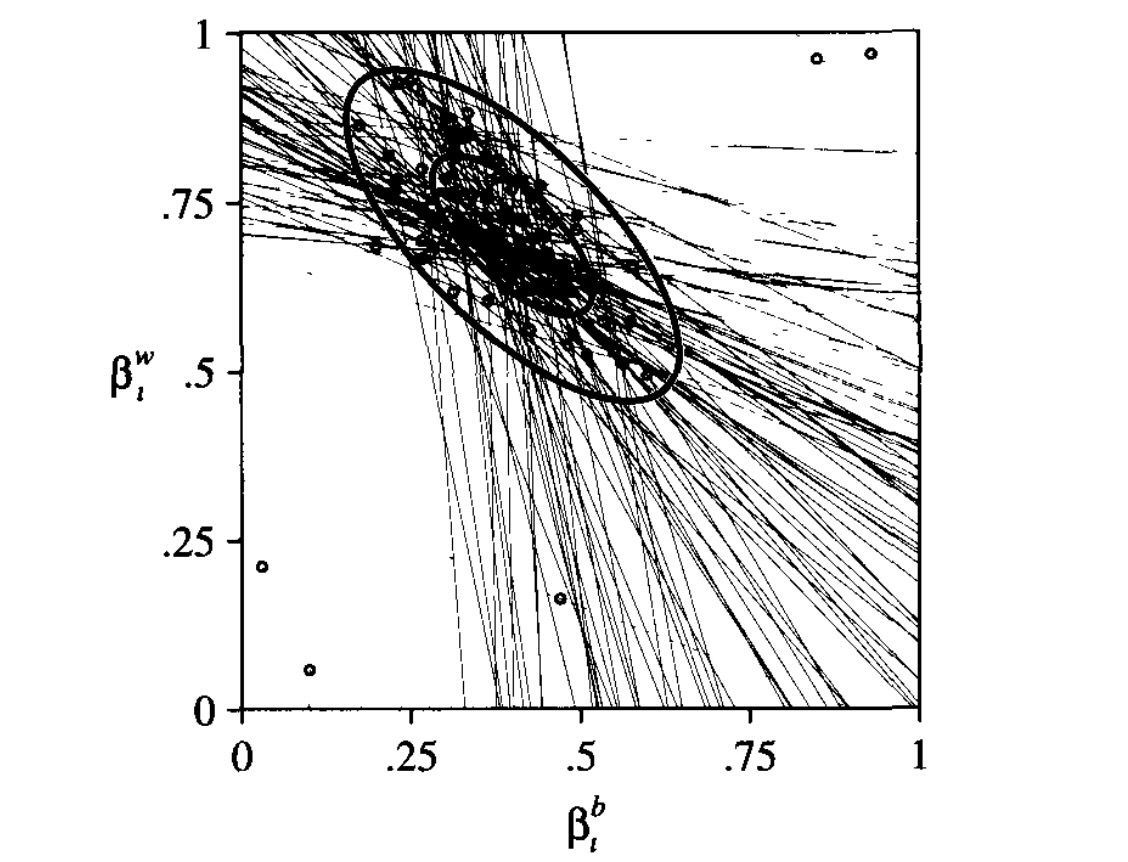
Ecological Inference (EI)
- Here, our priors will encode logical constraints (weakly-informative)
- Then, our statistical model will model probabilities of micro-level statistics subject to these constraints
Propensity Score Weighting
- HW1 matching: similarity either 1 (applied to same schools) or 0 (didn’t apply to same schools)
- Propensity scores: model quality of match
- \(\Rightarrow\) Opens up (literally) infinite possibilities between 0 and 1!
- \(\Rightarrow\) Use your unsupervised learning skills (matching via clustering)
- \(\Rightarrow\) Use your supervised learning skills (propensity scores = logistic regression coefficients!)

{kind=link}
- \(\Rightarrow\) Use your diagnostic skills: e.g., methods for evaluating clusters / preventing overfitting
Working Example: Growth Mindset(!)
- From Athey and Wager (2019)
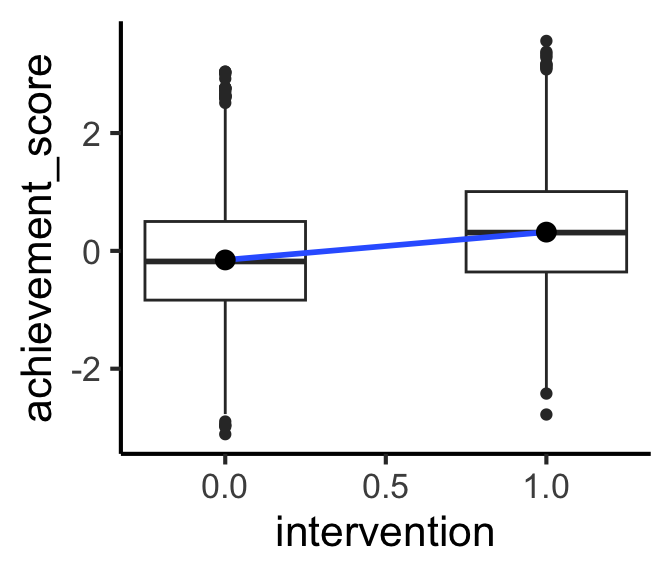
- Treatment \(T\), called
interventionin the dataset: a seminar on growth mindset for high school students - Outcome \(Y\), called
achievement_scorein the dataset: performance on state’s standardized test - In a perfect world, we could just compute
\[ \mathbb{E}[Y \mid T = 1] - \mathbb{E}[Y \mid T = 0] \]

Code
| intervention | mean_score |
|---|---|
| 0 | -0.1538030 |
| 1 | 0.3184686 |
Code
| term | estimate |
|---|---|
| (Intercept) | -0.1538030 |
| intervention | 0.4722717 |
Code
The Problem: Pesky Covariates
- Here the “blob” \(\mathbf{X}\) forms a fork, as drawn…
- But in reality the work of modeling is flying into the cloud and modeling the \(\mathbf{X}\)-\(T\) and \(\mathbf{X}\)-\(Y\) relationships (especially: figuring out which covariates \(X_j \in \mathbf{X}\) are colliders), so you can close the backdoors:


- This can be really difficult, for a bunch of reasons… What if there was an easier way?
If We Had Control Over Everything (Experiments vs. Observational Data Analysis)
- If we could intervene in the DGP, we could assign treatment randomly, thus removing the impact of Covariates on \(T\)!

- Alas, we are data scientists, not (necessarily) experiment-conductors, plus there are often ethical reasons to not perform experiments!
- …There’s still another approach!
Closing Backdoors the Too-Good-To-Be-True Way
- Key insight from causal thinking: Transformation of the problem from “control for all covariates” to “close all backdoor paths”…
- For the goal of just closing these paths, we have an alternative1:
- Rosenbaum and Rubin (1983): there exists a statistic \(\mathtt{e}(\mathbf{X}) = \Pr(T \mid \mathbf{X})\), the propensity score, which “captures” info in \(\textbf{X}\) relevant to \(T\) such that
- Conditioning on \(\mathtt{e}(\mathbf{X})\) closes \(\mathbf{X} \Rightarrow \mathtt{e}(\mathbf{X}) \rightarrow T\) (\(\mathtt{e}(\mathbf{X})\) is a pipe)

- This would close backdoor path \(T \leftarrow \mathtt{e}(\mathbf{X}) \Leftarrow \mathbf{X} \rightarrow Y\), leaving only direct effect \(T \rightarrow Y\)! There’s one remaining complication…
Closing Backdoors via Propensity Score Estimation
- Sadly we don’t observe true probability of being treated for all possible values of \(\mathbf{X}\)
- But, we can derive an estimate \(\hat{\mathtt{e}}(\mathbf{X})\) using our machine learning skills 😎
- We now have that \(\hat{\mathtt{e}}(\mathbf{X})\), as a proxy relative to the pipe \(\mathbf{X} \Rightarrow \mathtt{e}(\mathbf{X}) \rightarrow T\), blocks the pipe to the extent that it captures the true probability \(\mathtt{e}(\mathbf{X}) = \Pr(T \mid \mathbf{X})\)

- Backdoor Path: \(T \leftarrow \mathtt{e}(\mathbf{X}) \Leftarrow \mathbf{X} \rightarrow Y\)
- Closed in proportion to \(\left[ \text{Cor}(\hat{\mathtt{e}}(\mathbf{X}), \mathtt{e}(\mathbf{X})) \right]^2 = ❓\)
Sometimes-Helpful Thought Experiment
- Back in our basic confounding scenario:
- If there was only one covariate (\(\mathbf{X} = X\)), and it was a constant (\(\Pr(X = c) = 1\)), then all the variation in \(Y\) would be due to variation in \(T\)
- Less extreme: if person \(i\) has covariates \(\mathbf{X}_i\) and person \(j\) has covariates \(\mathbf{X}_j\), but \(\mathbf{X}_i = \mathbf{X}_j\), then variation in their outcomes is due solely to \(T\)
- Part of the logic of propensity score is that, if person \(i\) has covariates \(\mathbf{X}_i\) and person \(j\) has covariates \(\mathbf{X}_j\), but \(\mathtt{e}(\mathbf{X}_i) = \mathtt{e}(\mathbf{X}_j)\), then \(i\) and \(j\) are perfectly matched
- \(\Rightarrow\) (by fun math proof) variation in their outcomes is due solely to \(T\)