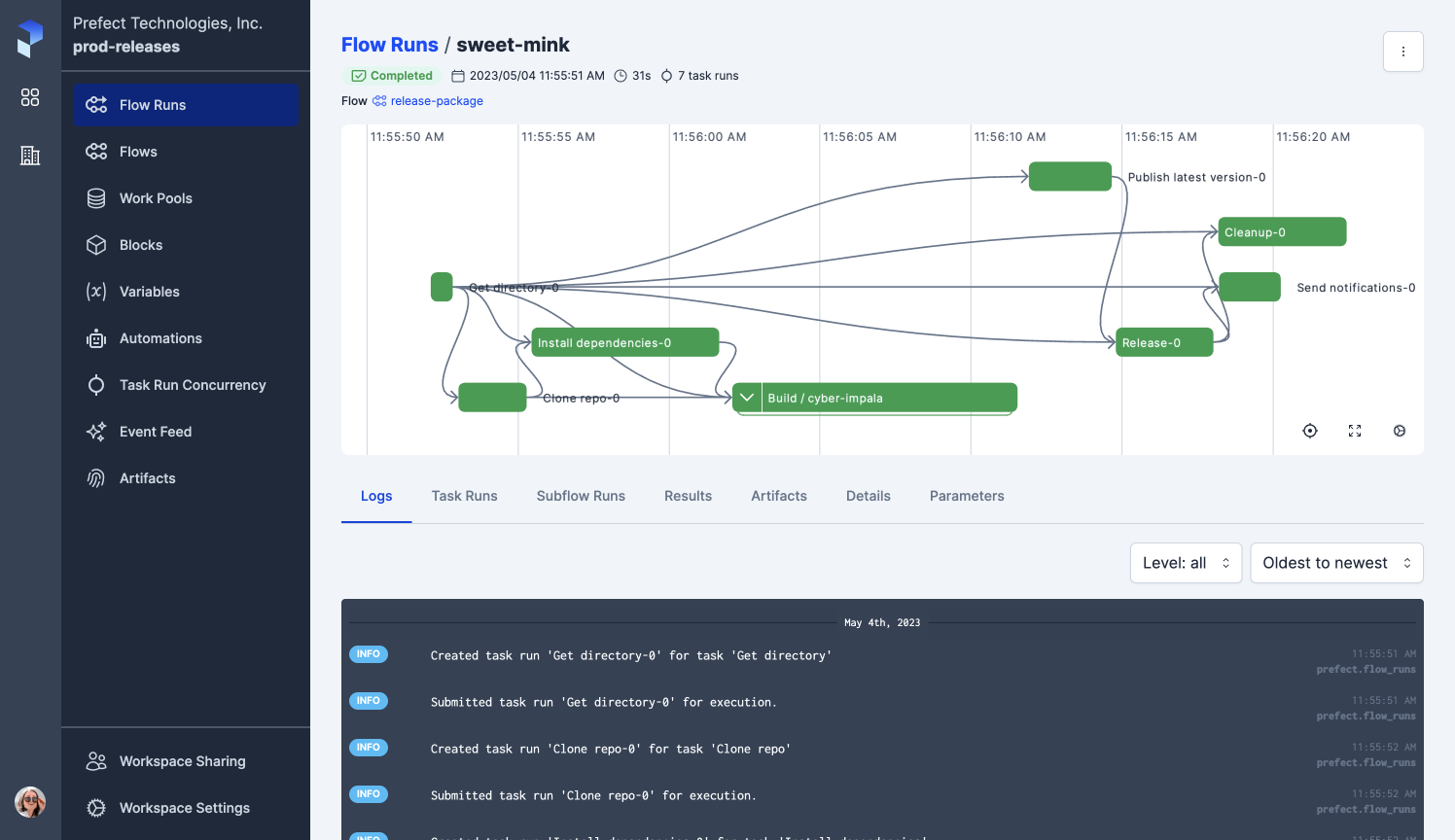
Code
InventoryItem(item_name='Banana', price=10.0)DSAN 5500: Data Structures, Objects, and Algorithms in Python
Monday, March 11, 2024
LinkedList, Merge-SortSwimmer class)
None → InventoryItem → BinarySearchTree)
InventoryItem(item_name='Banana', price=10.0)ValidationError: 1 validation error for InventoryItem
price
Input should be a valid number, unable to parse string as a number [type=float_parsing, input_value='100 dollar', input_type=str]
For further information visit https://errors.pydantic.dev/2.6/v/float_parsingValidationError: 1 validation error for Employee
email
value is not a valid email address: The email address is not valid. It must have exactly one @-sign. [type=value_error, input_value='fakeemail!!!', input_type=str]From Analytics Vidhya
Team objectInventoryItem object for each row)LogarithmicHashTablekey and value separately, or together?tuples or InventoryItems?InventoryItems: What type(s) for item_name? What type(s) for price? 😵txt, epub (can contain images), pdf (sometimes text is embedded, sometimes not), images of scans, audiobooksDSAN 5500 Week 8: Data Validation, Pipelines