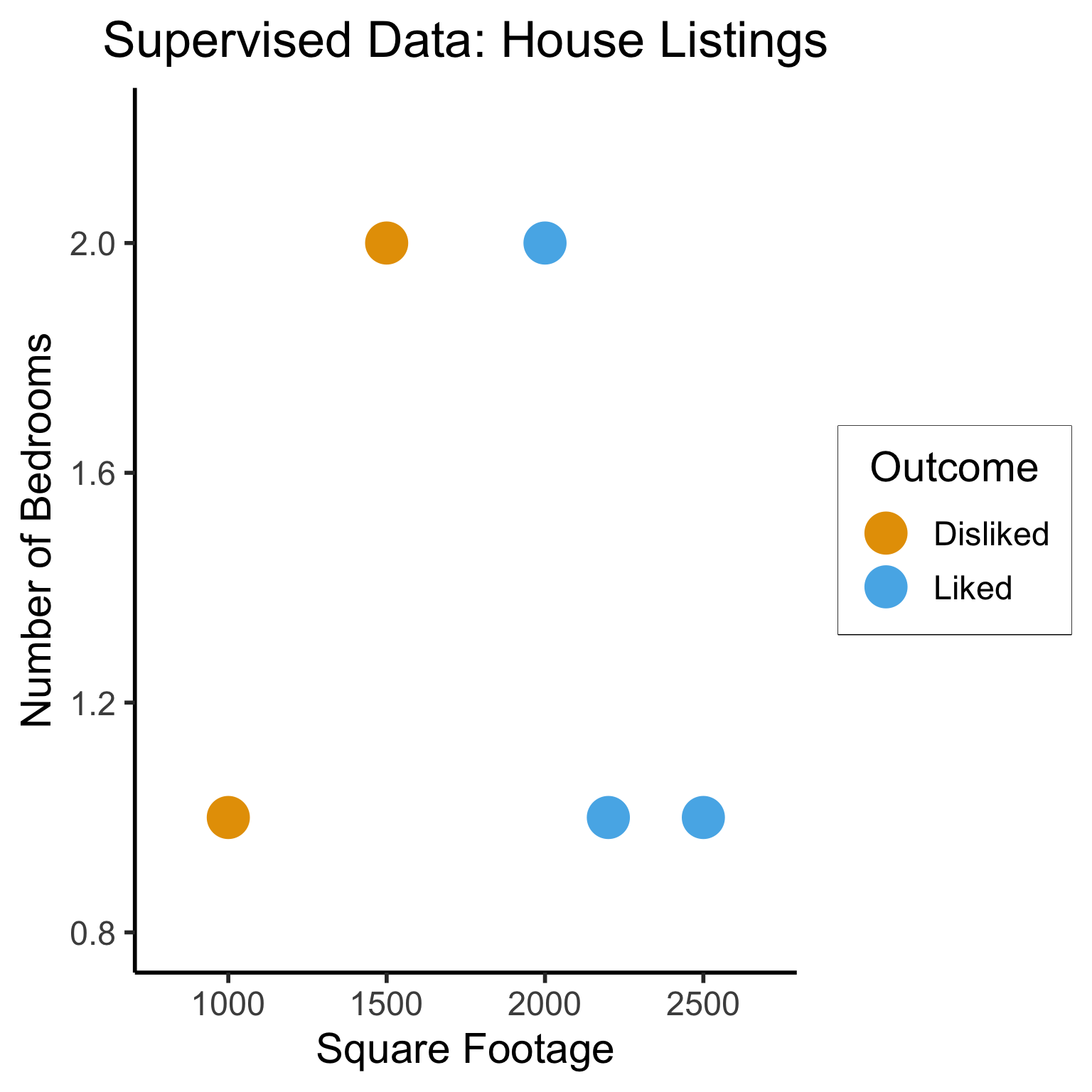
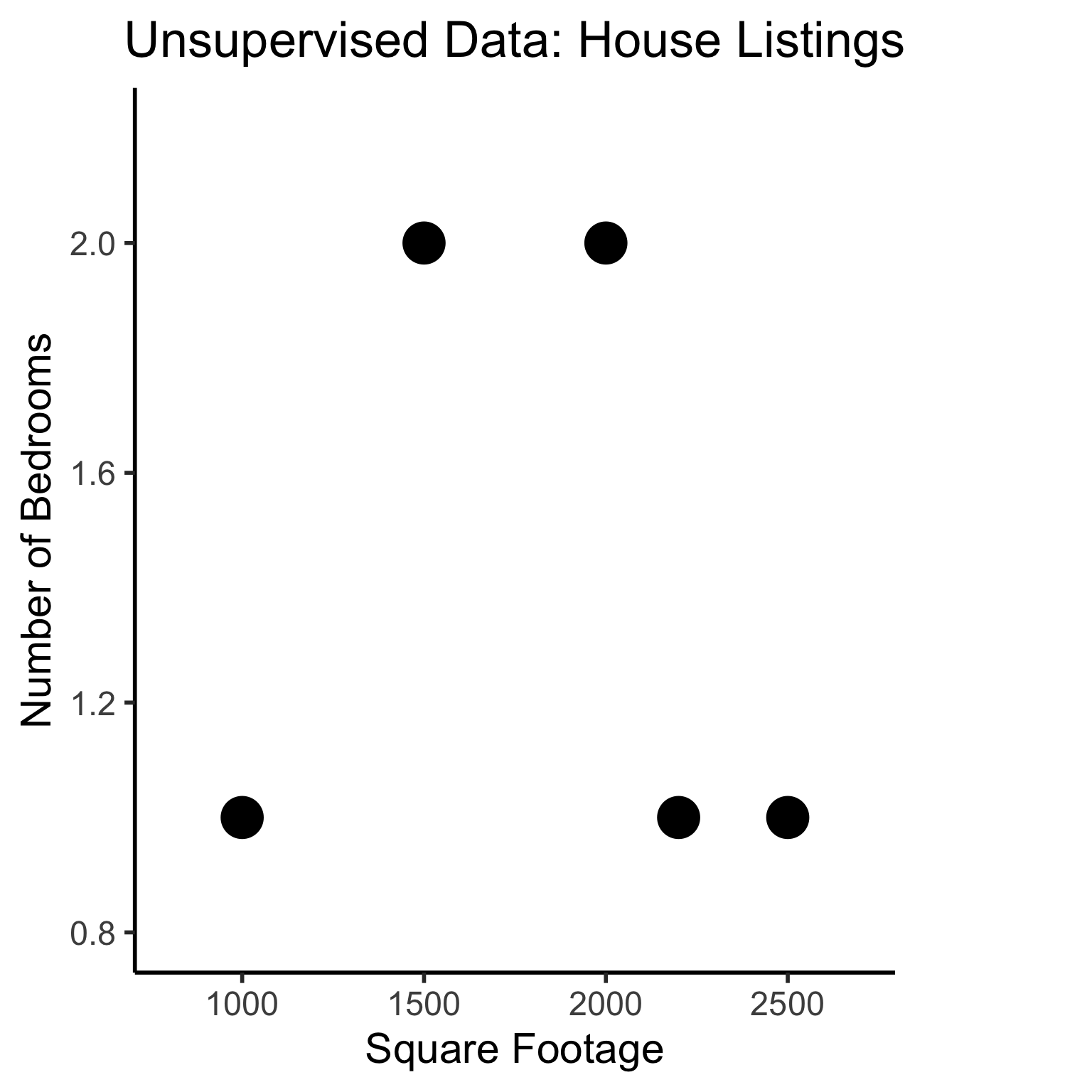
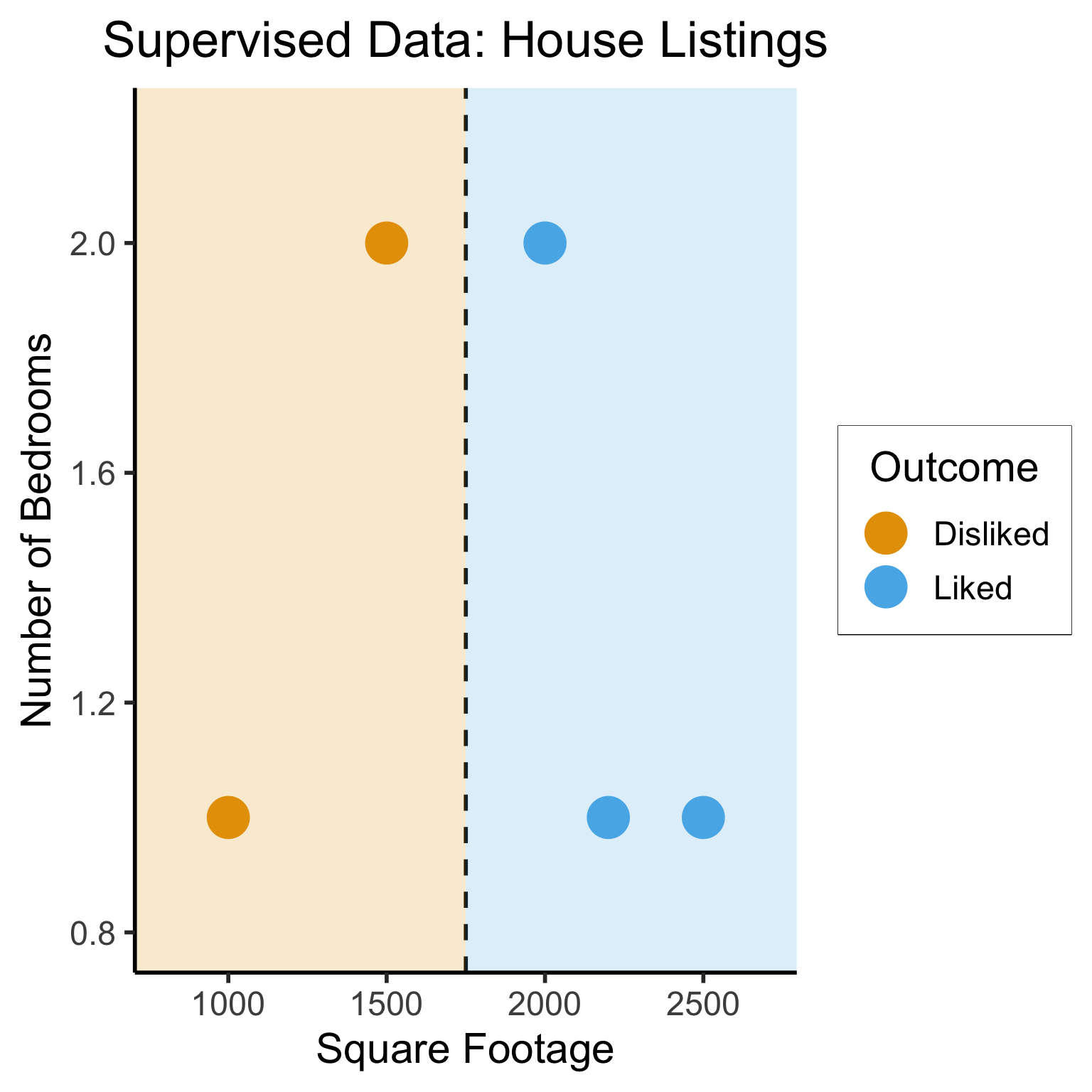
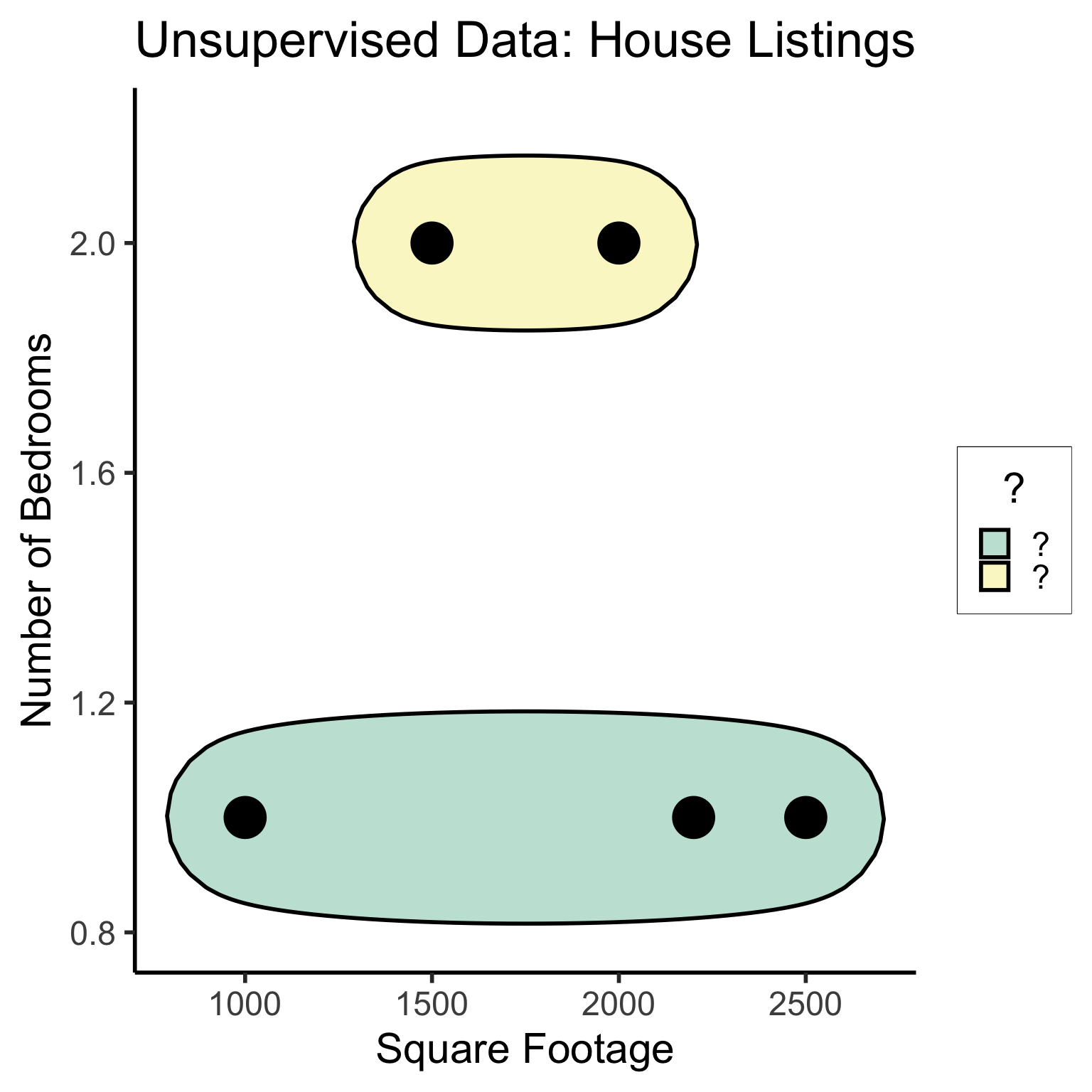
Supervised Learning: You want the computer to learn the existing pattern of how you are classifying1 observations
Discovering the relationship between properties of data and outcomes
Example (Binary Classification): I look at homes on Zillow, saving those I like to folder A and don’t like to folder B
Example (Regression): I assign a rating of 0-100 to each home
In both cases: I ask the computer to learn my schema (how I classify)
Unsupervised Learning: You want the computer to find patterns in a dataset, without any prior classification info
Typically: grouping or clustering observations based on shared properties
Example (Clustering): I save all the used car listings I can find, and ask the computer to “find a pattern” in this data, by clustering similar cars together
Dataset Structures
Supervised Learning: Dataset has both explanatory variables (“features”) and response variables (“labels”)
home_id
sqft
bedrooms
rating
0
1000
1
Disliked
1
2000
2
Liked
2
2500
1
Liked
3
1500
2
Disliked
4
2200
1
Liked
Unsupervised Learning: Dataset has only explanatory variables (“features”)
home_id
sqft
bedrooms
0
1000
1
1
2000
2
2
2500
1
3
1500
2
4
2200
1
Dataset Structures: Visualized
Different Goals
The “Learning” in Machine Learning
Given these datasets, how do we learn the patterns?
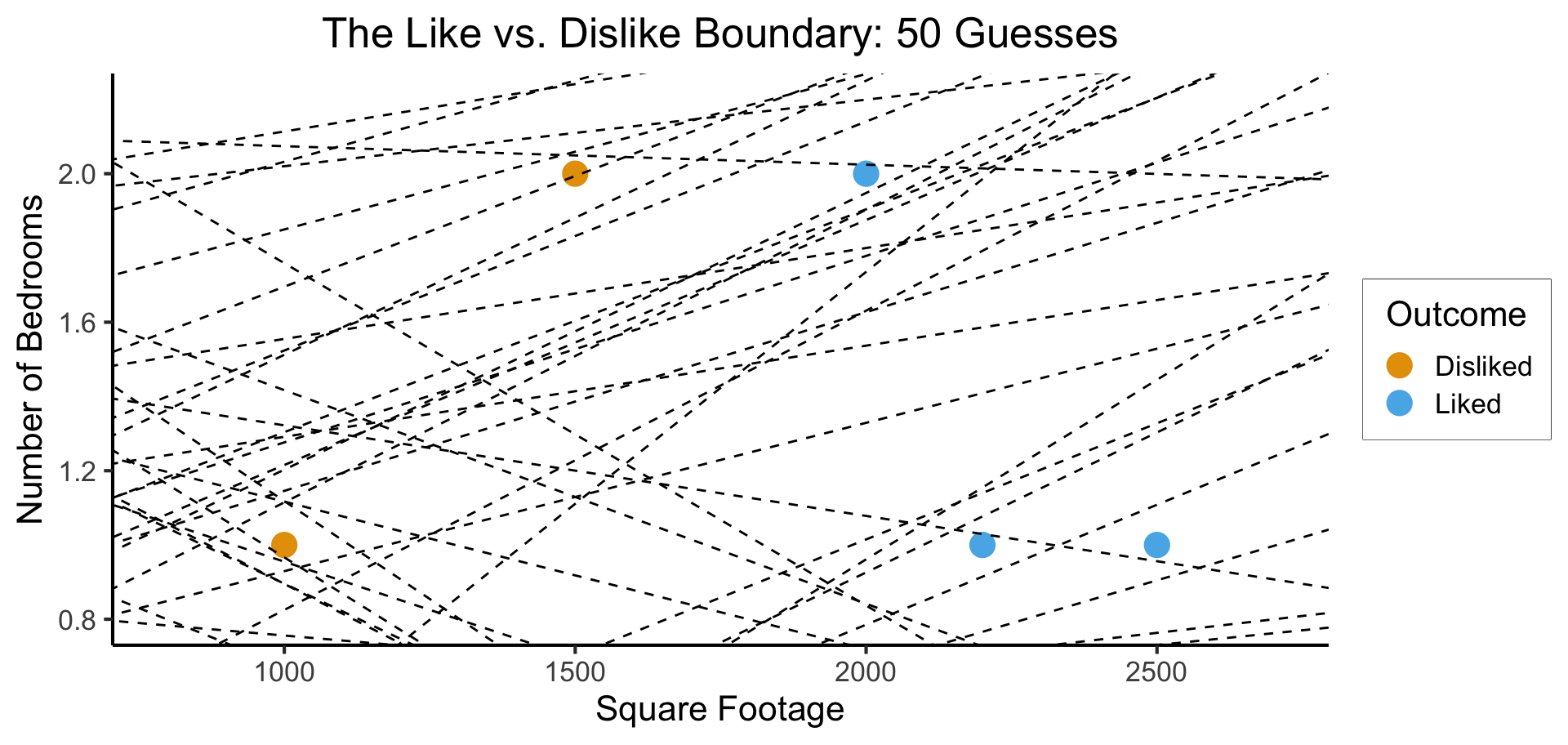
Naïve idea: Try random lines (each forming a decision boundary), pick “best” one
What parameters are we choosing when we draw a random line? Random curve?
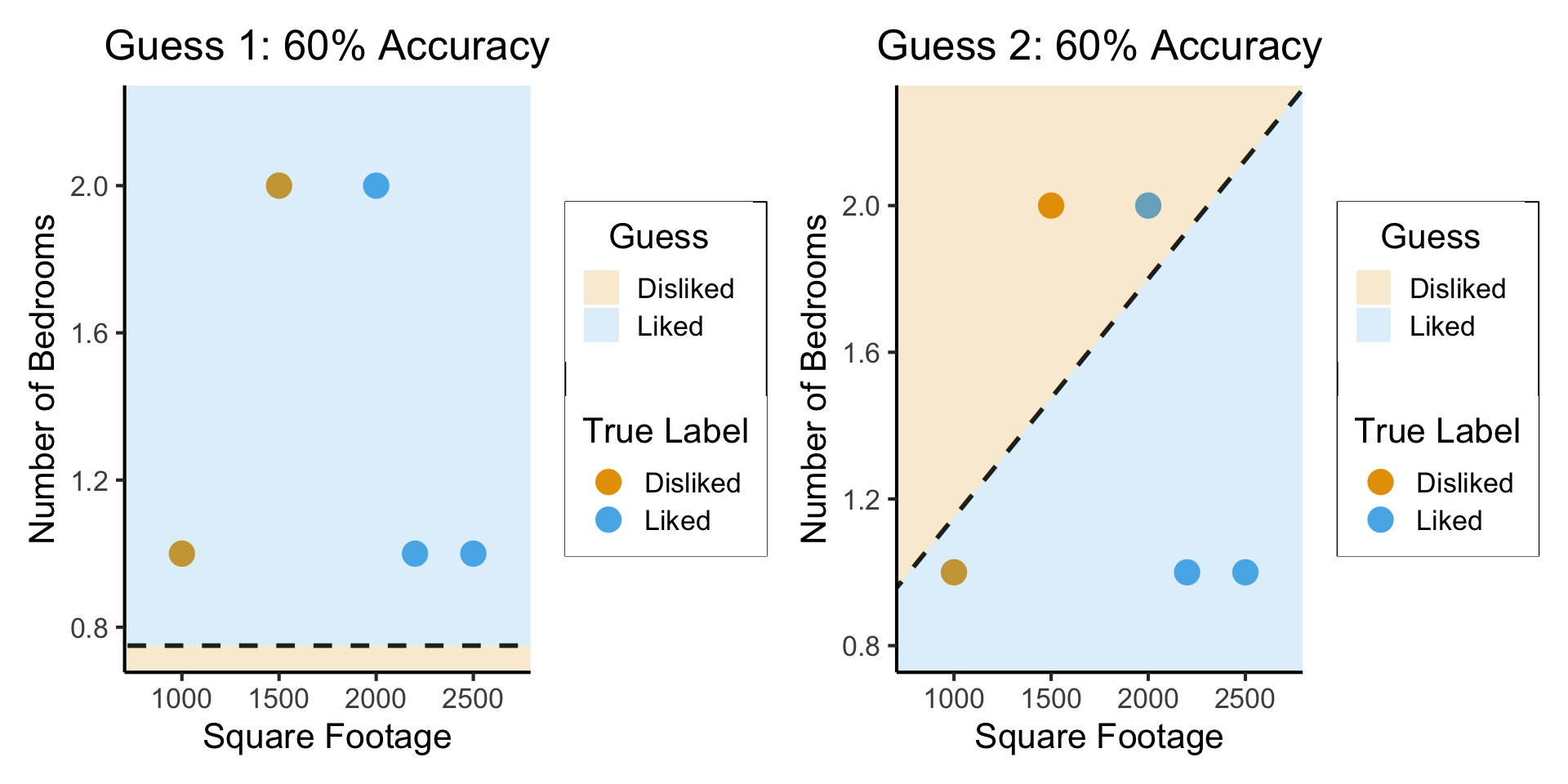
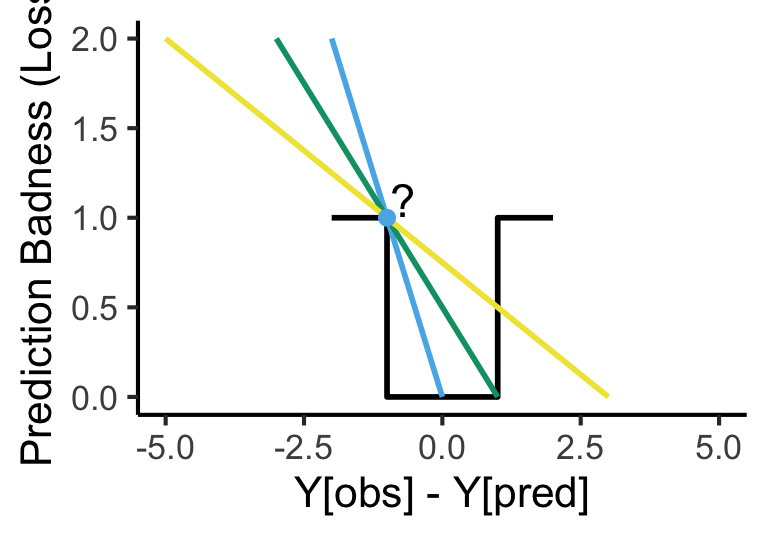
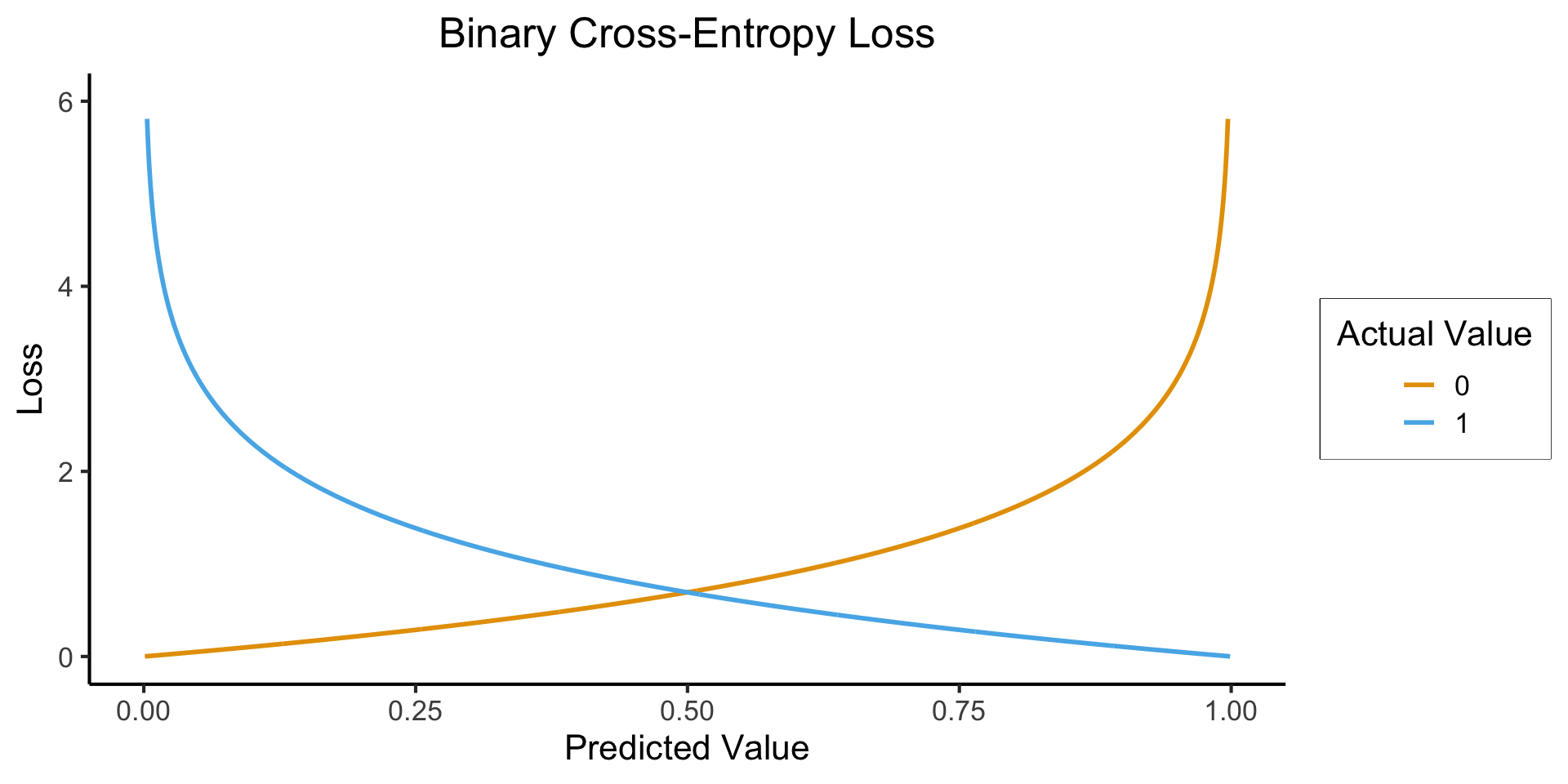
What Makes a “Good”/“Best” Guess?
What’s your intuition? How about accuracy… 🤔
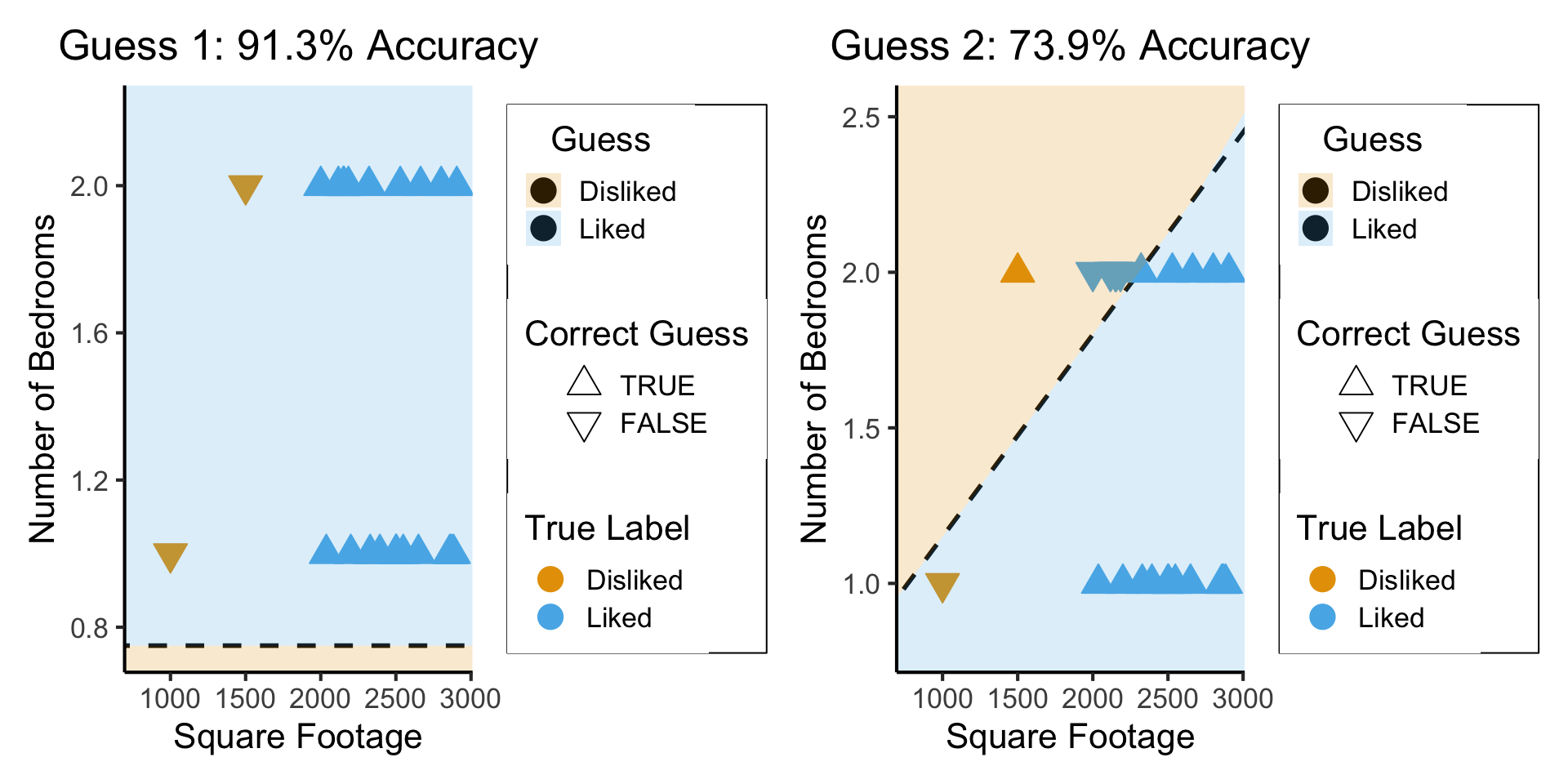
So… what’s wrong here?
What’s Wrong with Accuracy?
The (Oversimplified) Big Picture
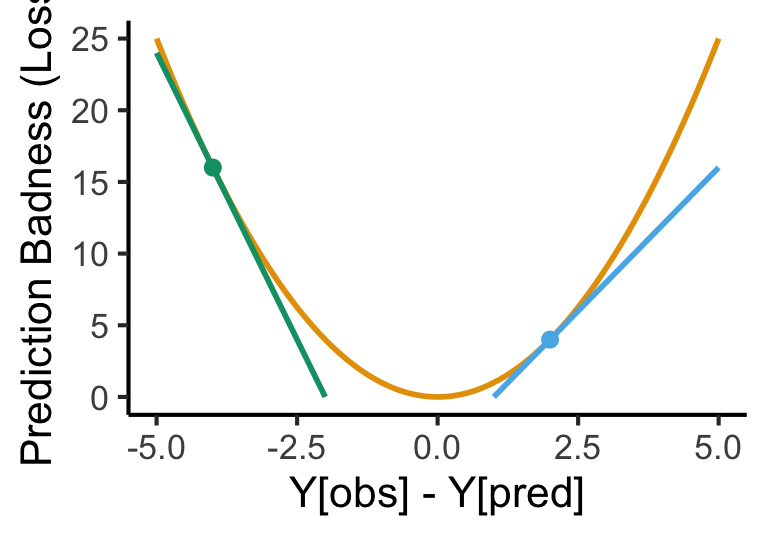
A model: some representation of something in the world
How well does our model represent the world?1\(\mathsf{Correspondence}(y_{obs}, \theta)\)
(Ensures a unique global minimum! Note that \(\lambda_2 = 0, \lambda_1 = 1 \implies \beta^*_{LASSO} = \beta^*_{EN}\))
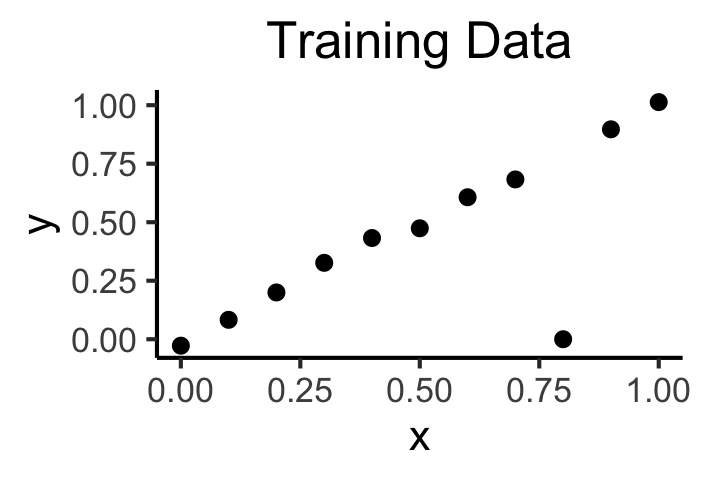
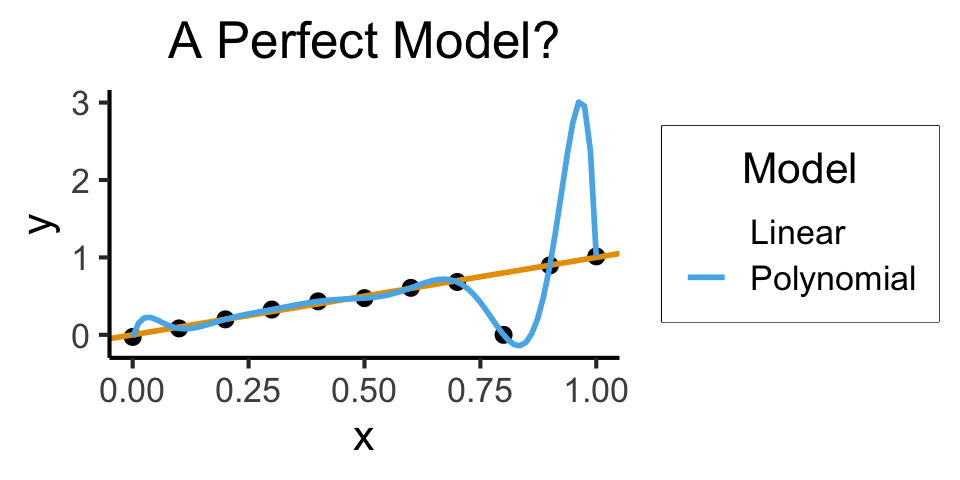
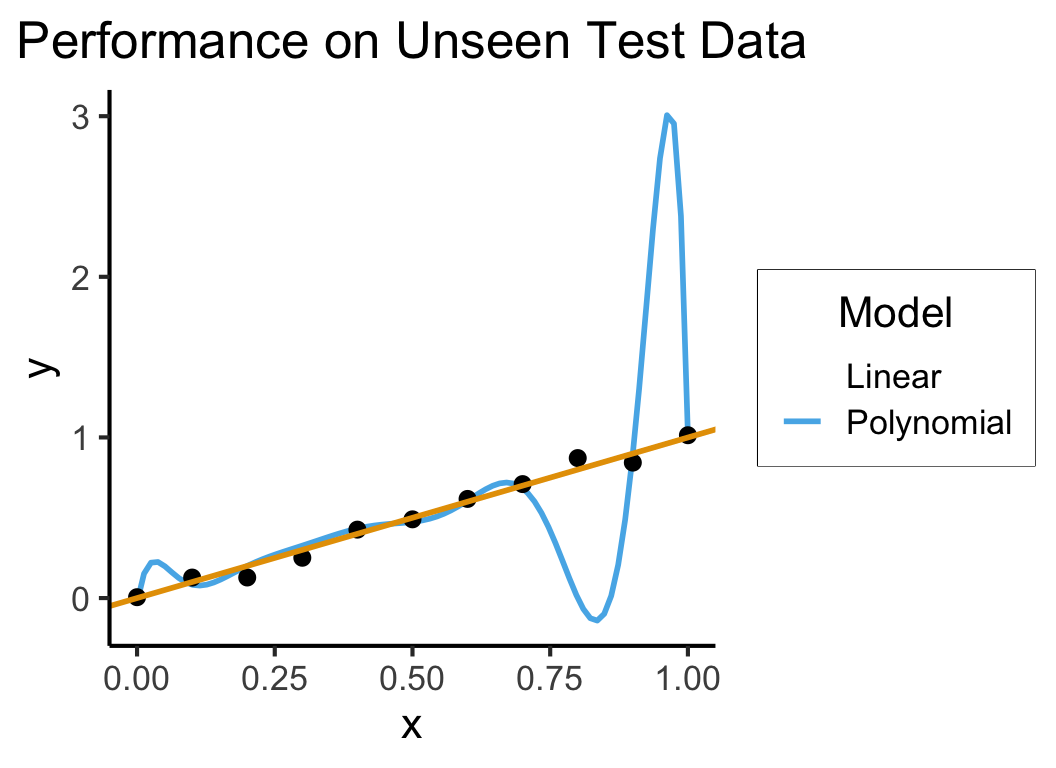
Training vs. Test Data
Cross-Validation
The idea that good models generalize well is crucial!
What if we could leverage this insight to optimize over our training data?
The key: Validation Sets
Hyperparameters
The unspoken (but highly consequential!) “settings” for our learning procedure (that we haven’t optimized via gradient descent)
There are several we’ve already seen – can you name them?
Unsupervised Clustering: The number of clusters we want (\(K\))
Gradient Descent: The step size\(\gamma\)
LASSO/Elastic Net: \(\lambda\)
The train/validation/test split!
Hyperparameter Selection
Every model comes with its own hyperparameters:
Neural Networks: Number of layers, number of nodes per layer
Decision Trees: Maximum tree depth, max number of features to include
Topic Models: Number of topics, document/topic priors
So, how do we choose?
Often more art than science
Principled, universally applicable, but slow: grid search
Specific methods for specific algorithms: ADAM [@kingma_adam_2017] for Neural Network learning rates)
Appendix: Harmonic Mean
\(\mathsf{HMean}\) is the harmonic mean, an alternative to the standard (arithmetic) mean
Penalizes greater “gaps” between precision and recall: if precision is 0 and recall is 1, for example, their arithmetic mean is 0.5 while their harmonic mean is 0.
For the curious: given numbers \(X = \{x_1, \ldots, x_n\}\), \(\mathsf{HMean}(X) = \frac{n}{\sum_{i=1}^nx_i^{-1}}\)