Lecture 10: Visualizing Big Data
DSAN 5200-03: Advanced Data Visualization
Tuesday, January 30, 2024
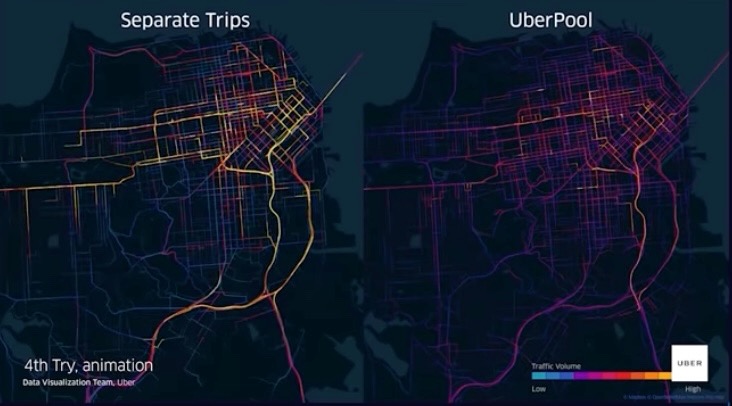
What Makes Big Data Visualization Different?
(…Let’s brainstorm!)

Client-Side vs. Server-Side Memory
In Chrome, check JS heap size (in GB) by running:
| My Chrome JS Heap | 4.2947 GB |
| 2020 US Census data | 4.3487 GB |
| Google Maps (2012) | 20 000 000.0000 GB |

The General Idea
- Ad hoc approach, figuring out what to do server-side vs. client-side “on the fly” ❌
- Instead, we can use systems which integrate them, drawing on respective strengths!
- Data Visualization Management System (DVMS)

Precomputation: Designing for an Audience