Week 10: Method of Moments and Bootstrap
DSAN 5100: Probabilistic Modeling and Statistical Computing
Section 01
Tuesday, November 4, 2025
The Bias-Variance Tradeoff
But modern Machine Learning basically gets us rly close to a free lunch
 Jeff
Jeff
Intuition
| Low Variance | High Variance | |
|---|---|---|
| Low Bias |  |
 |
| High Bias |  |
 |
In Practice
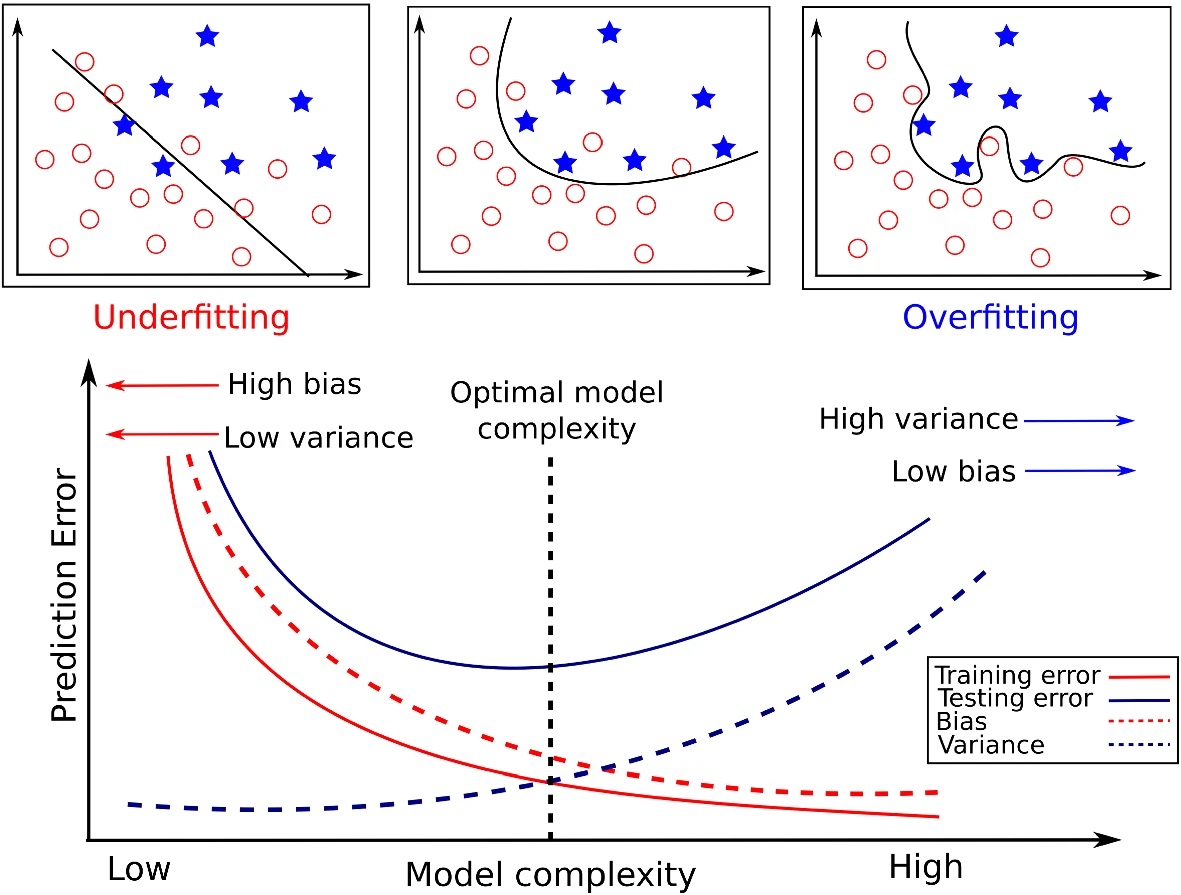
Figure from Tharwat (2019)
Building Intuition
Consider the following dataset:
Code
x <- seq(from = 0, to = 1, by = 0.1)
n <- length(x)
eps <- rnorm(n, 0, 0.04)
y <- x + eps
# But make one big outlier
midpoint <- ceiling((3/4)*n)
y[midpoint] <- 0
of_data <- tibble::tibble(x=x, y=y)
# Linear model
lin_model <- lm(y ~ x)
# But now polynomial regression
poly_model <- lm(y ~ poly(x, degree = 10, raw=TRUE))
ggplot(of_data, aes(x = x, y = y)) +
geom_point(size = g_pointsize / 1.5) +
dsan_theme("full")
Using All Observations
Fitting a linear model gives us:
Code
ggplot(of_data, aes(x = x, y = y)) +
geom_point(size = g_pointsize / 1.5) +
geom_smooth(aes(color="Linear"), method = lm, se = FALSE, show.legend=FALSE) +
# geom_abline(aes(intercept = 0, slope = 1, color = "Linear"), linewidth = 1, show.legend = FALSE) +
# stat_smooth(
# method = "lm",
# formula = y ~ poly(x, 10, raw = TRUE),
# se = FALSE, aes(color = "Polynomial")
# ) +
dsan_theme("full")
But is it Robust?
Code
## Part 1: Set up data
library(dplyr)
library(ggplot2)
library(tibble)
# subsample <- of_data |> sample_n() sample(of_data, size=5)
gen_subsamples <- function(obs_data, num_subsamples, subsample_size) {
#print(subsample_size)
subsample_ints <- c()
subsample_coefs <- c()
for (i in 1:num_subsamples) {
cur_subsample <- obs_data |> sample_n(subsample_size, replace = TRUE)
cur_lin_model <- lm(y ~ x, data = cur_subsample)
cur_int <- cur_lin_model$coefficients[1]
subsample_ints <- c(subsample_ints, cur_int)
cur_coef <- cur_lin_model$coefficients[2]
subsample_coefs <- c(subsample_coefs, cur_coef)
}
subsample_df <- tibble(intercept = subsample_ints, coef = subsample_coefs)
return(subsample_df)
}
num_subsamples <- 50
subsample_size <- floor(nrow(of_data) / 2)
subsample_df <- gen_subsamples(of_data, num_subsamples, subsample_size)
full_model <- lm(y ~ x, data = of_data)
full_int <- full_model$coefficients[1]
full_coef <- full_model$coefficients[2]
full_df <- tibble(intercept=full_int, coef=full_coef)
mean_df <- tibble(
intercept=mean(subsample_df$intercept),
coef = mean(subsample_df$coef)
)
## Part 2: Plot
ggplot(of_data, aes(x = x, y = y)) +
geom_point(size=g_pointsize) +
# The random lines
geom_abline(data = subsample_df, aes(slope = coef, intercept = intercept, color='Subsample Model'), linewidth=g_linewidth, linetype="solid", alpha=0.25) +
# The original regression line
geom_abline(data=full_df, aes(slope = coef, intercept = intercept, color='Full-Data Model'), linewidth=2*g_linewidth) +
# The average of the random lines
#geom_abline(data=mean_df, aes(slope = coef, intercept = intercept, color='mean'), linewidth=2*g_linewidth) +
labs(
title = paste0("Linear Models for ", num_subsamples, " Subsamples of Size n = ", subsample_size),
color = element_blank()
) +
dsan_theme("full") +
theme(
legend.title = element_blank(),
legend.spacing.y = unit(0, "mm")
)
What a Robust Model Looks Like
Code
x <- seq(from = 0, to = 1, by = 0.1)
n <- length(x)
eps <- rnorm(n, 0, 0.04)
y <- x + eps
robust_data <- tibble(x = x, y = y)
robust_sub_df <- gen_subsamples(robust_data, 30, 5)
#print(robust_sub_df)
full_model_robust <- lm(y ~ x, data = robust_data)
full_int_robust <- full_model_robust$coefficients[1]
full_coef_robust <- full_model_robust$coefficients[2]
full_df_robust <- tibble(intercept = full_int_robust, coef = full_coef_robust)
ggplot(robust_data, aes(x = x, y = y)) +
geom_point(size=g_pointsize) +
# The random lines
geom_abline(data = robust_sub_df, aes(slope = coef, intercept = intercept, color='Subsample Model'), linewidth=g_linewidth, linetype="solid", alpha=0.25) +
# The original regression line
geom_abline(data=full_df_robust, aes(slope = coef, intercept = intercept, color='Full-Data Model'), linewidth=2*g_linewidth) +
# The average of the random lines
#geom_abline(data=mean_df, aes(slope = coef, intercept = intercept, color='mean'), linewidth=2*g_linewidth) +
labs(
title = paste0("Linear Models for ", num_subsamples, " Subsamples of Size n = ", subsample_size),
color = element_blank()
) +
dsan_theme("full") +
theme(
legend.title = element_blank(),
legend.spacing.y = unit(0, "mm")
)
Here the model is not “misled” by outliers
In Pictures

How Well Does it Work?
Answer: Absurdly, unreasonably well.
Code
pop <- rnorm(1000000, mean = 3, sd = 1)
# Sampling 1k times
rand_samples <- replicate(
1000,
sample(pop, size=100, replace = FALSE)
)
sample_means <- colMeans(rand_samples)
sample_df <- tibble(est = sample_means, Method = "1000 Samples")
# Sampling 1 time and bootstrapping
bs_sample <- sample(pop, size = 100, replace = FALSE)
subsamples <- replicate(1000, sample(bs_sample, size=100, replace = TRUE))
bs_means <- colMeans(subsamples)
bs_df <- tibble(est = bs_means, Method = "Bootstrap (1 Sample)")
result_df <- bind_rows(sample_df, bs_df)
sim_dnorm <- function(x) dnorm(x, mean = 3, sd = 1)
ggplot(result_df, aes(x=est, fill=Method)) +
dsan_theme("full") +
geom_density(alpha=0.2, linewidth=g_linewidth) +
geom_vline(aes(xintercept=3, linetype="value"),linewidth=g_linewidth) +
scale_linetype_manual("", values=c("density"="solid", "value"="dashed"), labels=c("Population Mean", "testing")) +
theme(
legend.title = element_blank(),
legend.spacing.y = unit(0, "mm")
) +
labs(
title = "Bootstrap vs. Multiple Samples",
x = "Sample / Subsample Means",
y = "Density"
)
Code
sample_est <- mean(sample_means)
sample_str <- sprintf("%.3f", sample_est)
sample_err <- abs(sample_est - 3)
sample_err_str <- sprintf("%.3f", sample_err)
sample_output <- paste0("1K samples estimate: ", sample_str, " (abs. err: ", sample_err_str, ")")
bs_est <- mean(bs_means)
bs_str <- sprintf("%.3f", bs_est)
bs_err <- abs(bs_est - 3)
bs_err_str <- sprintf("%.3f", bs_err)
bs_output <- paste0("Bootstrap estimate: ", bs_str, " (abs. err: ", bs_err_str, ")")
writeLines(paste0(sample_output,"\n",bs_output))1K samples estimate: 3.001 (abs. err: 0.001)
Bootstrap estimate: 3.025 (abs. err: 0.025)So How Can We Determine Whether The Coin Is Fair?
Code
library(tidyverse)
num_replications <- 1000
coin_seqs <- replicate(num_replications, rbern(num_flips, p))
heads_per_seq <- colSums(coin_seqs)
heads_df <- tibble(num_heads = heads_per_seq)
highlight_3 <- c(rep("grey",2), rep(cbPalette[1],1), rep("grey",7))
ggplot(heads_df, aes(x=factor(num_heads))) +
geom_histogram(stat='count', fill=highlight_3) +
dsan_theme("quarter") +
labs(
title=paste0("Results From N=",num_replications," 10-Coin-Flip Trials")
)- We have to generate many sequences of coin flips, then look at the distribution of the number of heads in each sequence →

- Now we can quantify exactly how “fishy” it was to get 3 heads: if the coin was fair, this would happen about 10.7% of the time:
[1] 0.107Generating The Null Distribution
- This is the range of values we might expect to see (under our model!) if two schools had the same underlying dropout probabilities
- \(\Pr(D_\text{pub} - D_\text{ch} = v \mid H_0) \propto\) height of bar at \(x = v\):
Code
num_trials <- 10000000
bw <- 100
sim_df <- run_sims_same_p(num_trials)
# And plot the values of our test statistic
null_dist_plot <- ggplot(sim_df, aes(x=test_stat)) +
geom_histogram(binwidth=bw) +
geom_density(
aes(y = bw * after_stat(count)),
linewidth = g_linewidth,
fill = cbPalette[1],
alpha = 0.333
) +
dsan_theme() +
labs(
x = "Test Statistic (D_pub - D_ch)",
y = "Count",
title = paste0("(Public Dropouts - Charter Dropouts), ",format(num_trials,big.mark=' ', scientific=FALSE)," Simulations")
)
null_dist_plot
How Extreme Is Our Observed Value Relative To This Range?
- Same plot, with a vertical (red) line at our observed value:
Code
library(scales)
null_obs_plot <- ggplot(sim_df, aes(x=test_stat)) +
geom_histogram(binwidth=bw) +
geom_density(
aes(y = (bw/3) * after_stat(count)),
linewidth = g_linewidth,
fill = cbPalette[1],
alpha = 0.333
) +
geom_vline(
xintercept = 8500,
color='red',
linewidth = g_linewidth,
linetype = 'dashed'
) +
scale_x_continuous(breaks=seq(from=5000, to=35000, by=5000), limits=c(5000, 35000)) +
scale_y_continuous(labels = label_number(big.mark=' ')) +
dsan_theme() +
labs(
x = "Test Statistic (D_pub - D_ch)",
y = "Count",
title = paste0("(Public Dropouts - Charter Dropouts), ",format(num_trials,big.mark=' ',scientific=FALSE)," Simulations")
)
null_obs_plot
(Now You Can Present Your Findings In Congressional Testimony 😉)

(From The Guardian, 2016 Feb 21)