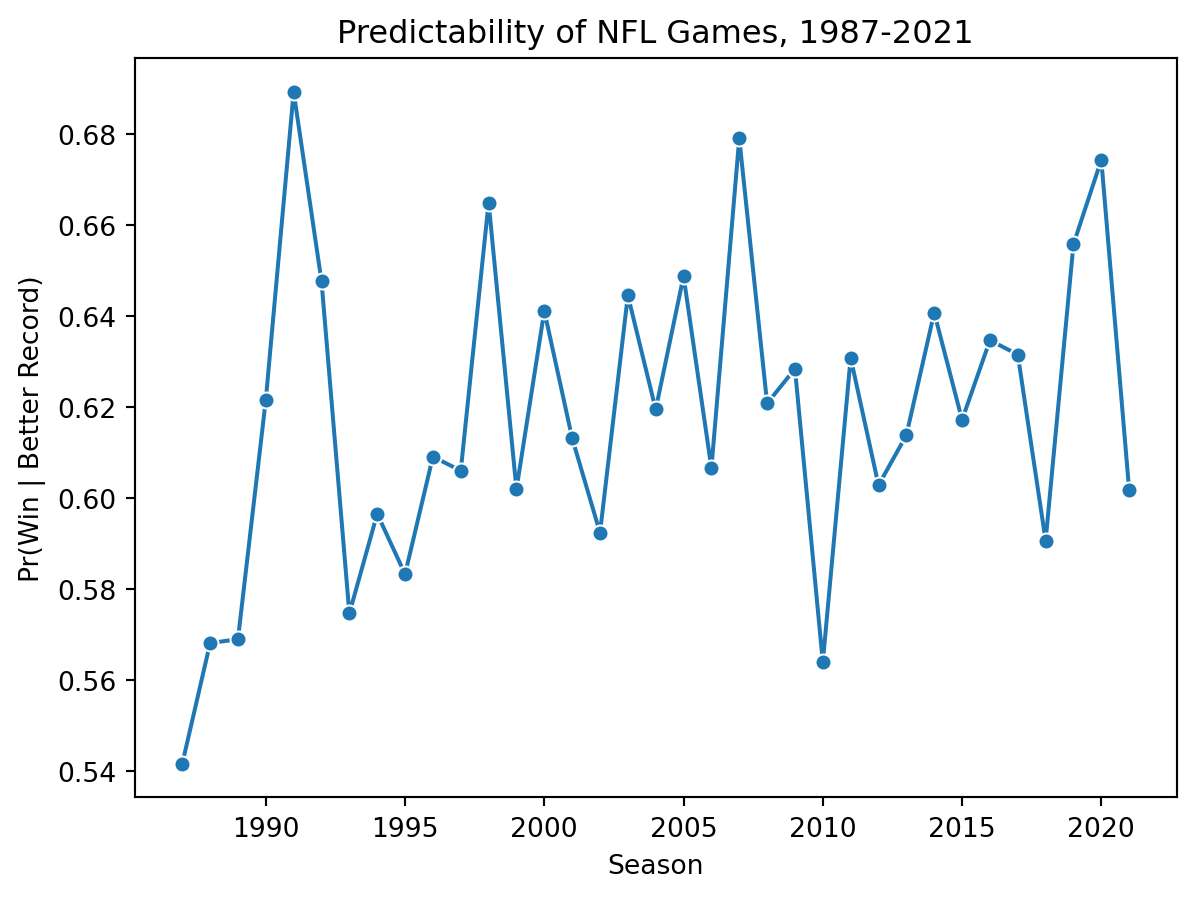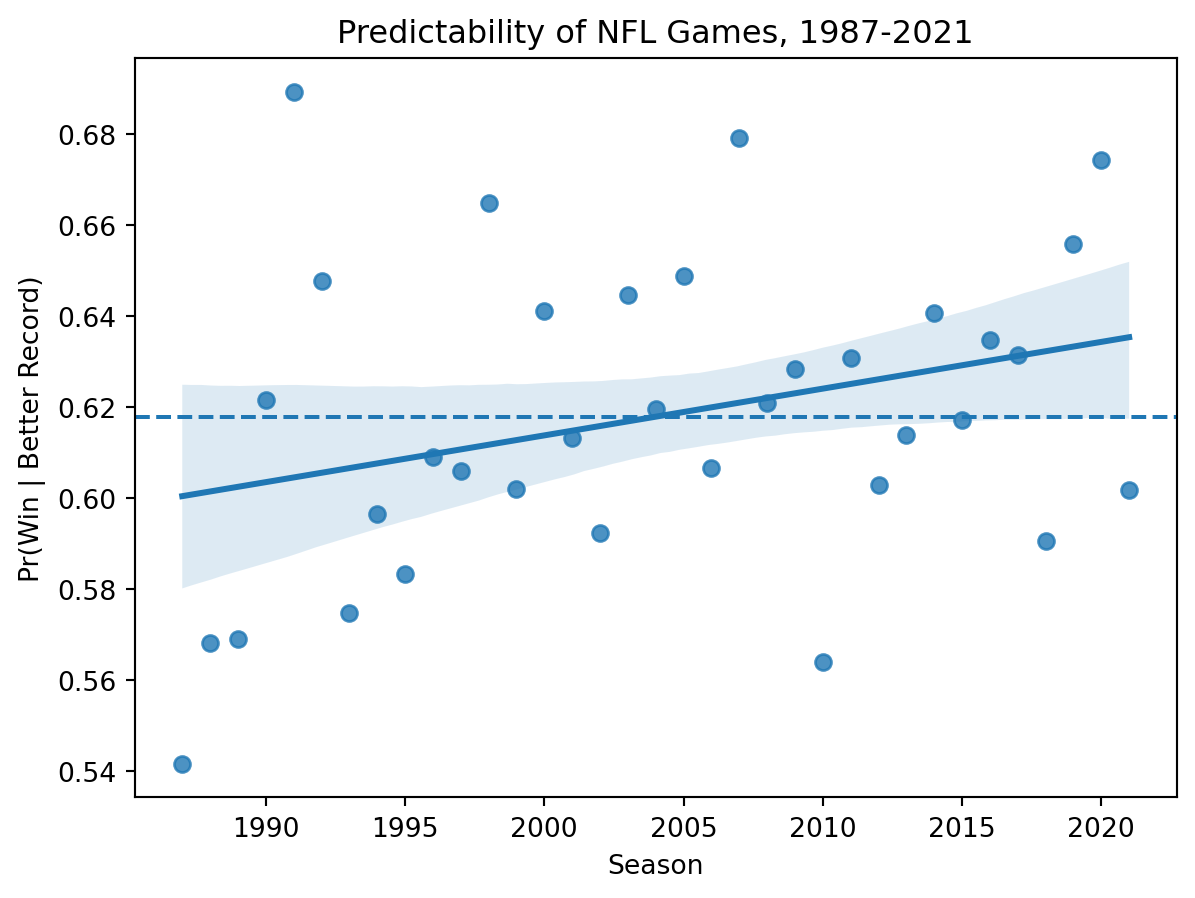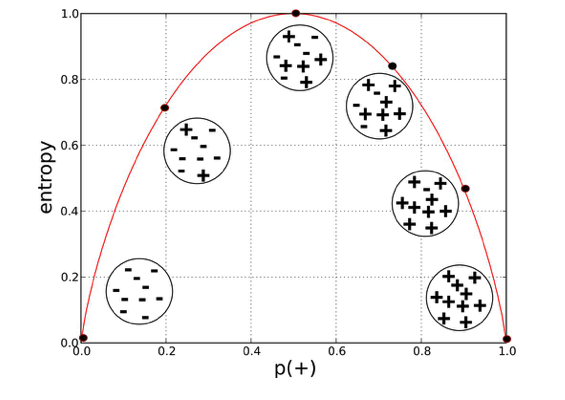
Code
import pandas as pd
import numpy as np
combined_df = pd.read_csv("assets/nfl_combined.csv")
combined_df.head()| game_id | season | game_type | week | gameday | weekday | gametime | away_team | away_score | home_team | ... | Winner/tie | at | Loser/tie | Unnamed: 7 | PtsW | PtsL | YdsW | TOW | YdsL | TOL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1999_01_MIN_ATL | 1999 | REG | 1.0 | 1999-09-12 | Sunday | NaN | MIN | 17.0 | ATL | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 1999_01_KC_CHI | 1999 | REG | 1.0 | 1999-09-12 | Sunday | NaN | KC | 17.0 | CHI | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 1999_01_PIT_CLE | 1999 | REG | 1.0 | 1999-09-12 | Sunday | NaN | PIT | 43.0 | CLE | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 1999_01_OAK_GB | 1999 | REG | 1.0 | 1999-09-12 | Sunday | NaN | OAK | 24.0 | GB | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 1999_01_BUF_IND | 1999 | REG | 1.0 | 1999-09-12 | Sunday | NaN | BUF | 14.0 | IND | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5 rows × 61 columns