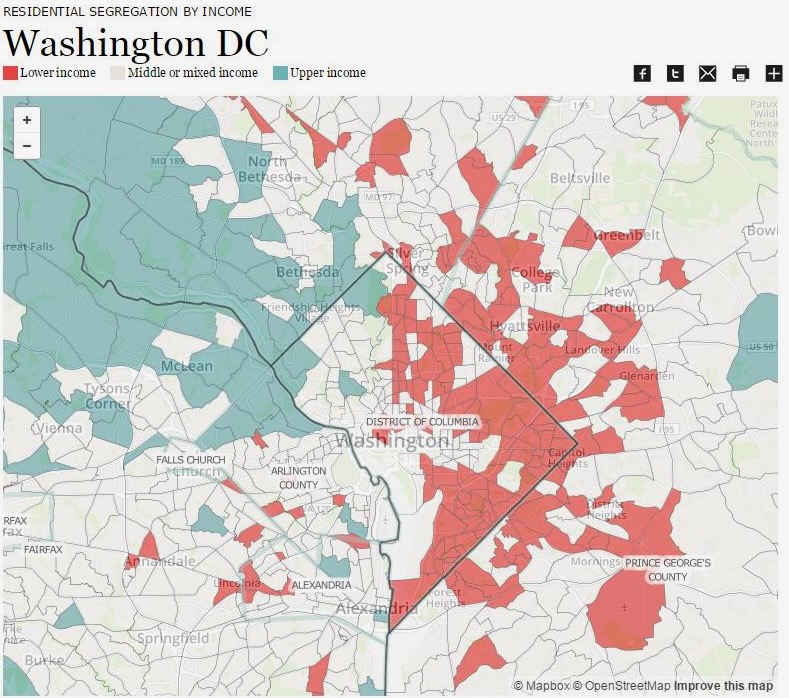
About ten years ago, Pew Research released an incredible set of maps visualizing how extreme segregation is in DC, race-wise as well as socioeconomic. A screenshot from this old set of visualizations shows what they used to look like:
Pew’s visualization of socioeconomic segregation in DC
Unfortunately, all of these visualizations used MapBox, which seems to just totally not exist anymore (at least, these particular maps are long gone), so that when you try to view these visualizations on Pew’s website nowadays, you just get a blank page.
So, in this document, I recreate the above maps, using open-source libraries in Python to (hopefully) allow interactive visualization of this important information that will last longer than the previous versions in MapBox’s proprietary format!
Data Overview
The data behind these maps is somewhat hard to find, but in a strange way that is the opposite of most hard-to-find data cases: here there are so many different data sources for income across the “DC Metro Area” (the definition of this region, itself, being subject to different interpretations by different data sources), that I ran into the following tradeoff at the start:
If we want data for just the District of Columbia itself, we can obtain very easy-to-use data directly from the DC government’s data portal, which is ready for immediate use in the sense that we can plug it into a mapping app and see the data without any need to tweak any settings! Clicking that link, for example, will show a preview of the map directly within the GitHub page! While the GitHub preview won’t show the income data for each tract, this geojson.io link (with the URL just pointing to that GitHub page) will!
Similarly, if we want data for just Maryland or just Virginia, we could obtain fairly easy-to-use geoJSON files from these states’ data portals
But, if we want data for the DC Metro Area, allowing apples-to-apples comparisons between (for example) census tracts within DC and in the Maryland suburbs, then we run into a bit of an issue since the relevant US Census data is far less ready-for-use in its raw form.
IPUMS Data: Median Income by Census Tract
First we load the data, which contains median household income for all census tracts in the US:
import pandas as pdipums_df = pd.read_csv("assets/nhgis0001_ds254_20215_tract.csv", encoding_errors='ignore')ipums_df.head()
GISJOIN
YEAR
STUSAB
REGIONA
DIVISIONA
STATE
STATEA
COUNTY
COUNTYA
COUSUBA
...
PCI
PUMAA
GEO_ID
BTTRA
BTBGA
TL_GEO_ID
NAME_E
AOQIE001
NAME_M
AOQIM001
0
G0100010020100
2017-2021
AL
NaN
NaN
Alabama
1
Autauga County
1
NaN
...
NaN
NaN
1400000US01001020100
NaN
NaN
1001020100
Census Tract 201, Autauga County, Alabama
57399.0
Census Tract 201, Autauga County, Alabama
10706.0
1
G0100010020200
2017-2021
AL
NaN
NaN
Alabama
1
Autauga County
1
NaN
...
NaN
NaN
1400000US01001020200
NaN
NaN
1001020200
Census Tract 202, Autauga County, Alabama
52176.0
Census Tract 202, Autauga County, Alabama
5849.0
2
G0100010020300
2017-2021
AL
NaN
NaN
Alabama
1
Autauga County
1
NaN
...
NaN
NaN
1400000US01001020300
NaN
NaN
1001020300
Census Tract 203, Autauga County, Alabama
63704.0
Census Tract 203, Autauga County, Alabama
11304.0
3
G0100010020400
2017-2021
AL
NaN
NaN
Alabama
1
Autauga County
1
NaN
...
NaN
NaN
1400000US01001020400
NaN
NaN
1001020400
Census Tract 204, Autauga County, Alabama
70000.0
Census Tract 204, Autauga County, Alabama
12155.0
4
G0100010020501
2017-2021
AL
NaN
NaN
Alabama
1
Autauga County
1
NaN
...
NaN
NaN
1400000US01001020501
NaN
NaN
1001020501
Census Tract 205.01, Autauga County, Alabama
60917.0
Census Tract 205.01, Autauga County, Alabama
29232.0
5 rows × 45 columns
We can get a sense of how many Census Tracts there are across different states, before we restrict ourselves to just the DMV:
# Here you can uncomment the following to install itables,# if it is not already installed in your environment!# We just use this to display nice HTML tables with pagination,# so it's optional and you don't need to worry if it# fails to install for whatever reason.#!pip install itables
from itables import showtract_counts = ipums_df['STUSAB'].value_counts().to_frame().reset_index()show(tract_counts)
Loading ITables v2.8.1 from the internet...
(need help?)
But now we can restrict our analysis to just DC, Maryland, and Virginia:
states_to_include = ['District of Columbia','Maryland','Virginia']dmv_df = ipums_df[ipums_df['STATE'].isin(states_to_include)].copy()
And we can look at the 153 unique values that are listed in the “County” field for these states, where you’ll see that this corresponds not only to “counties” in the standard colloquial sense but also to areas that have not been incorporated into any counties: places like Alexandria city:
And now, since we’re about to merge this data with the shapefiles for Maryland, DC, and Virginia, which have a GEOID field of type string, we’ll need to create a string version of the TL_GEO_ID variable from IPUMS, for merging:
# String version for mergingdmv_df['TL_GEO_ID_str'] = dmv_df['TL_GEO_ID'].apply(str)
TIGER Shapefiles for DC, Maryland, and Virginia
Next we’ll load the TIGER shapefiles provided by the Census website, for DC (FIPS code 11), Maryland (FIPS code 24), and Virginia (FIPS code 51).
Here we use the amazing GeoPandas library, which essentially lets us keep using Pandas as we’ve been using it, but also maintains a GIS representation of the data “under the hood”, so that when we’re ready to plot our data we can plug the GeoDataFrame object into (for example) Plotly or any other data visualization library that supports mapping!
# Uncomment the following to install geopandas, if it is# not already installed in your environment!#!pip install geopandas
Now, since our original dmv_df and the GeoPandas-managed dmv_shape_df both have GEO_ID variables (with slightly different names), we can merge them into a single DataFrame and then tell GeoPandas to track all of this information!
And now, finally, we can make use of Plotly’s Cloropethmapbox object to create a Cloropeth map of the different income levels:
# Uncomment the following to install Plotly, if it is not already# installed on your machine!#!pip install plotly
import plotly.express as pximport plotly.io as piopio.renderers.default ="notebook"median_income_var ="AOQIE001"# Capitol Building#capitol_lat = 38.889805#capitol_lon = -77.009056# White House#center_lat = 38.8977#center_lon = -77.0365# Scott Statuecenter_lat =38.907278946266466center_lon =-77.03651807332851income_fig = px.choropleth_mapbox( geo_df, geojson=geo_df.geometry, locations=geo_df.index,#z=geo_df[median_income_var], color=median_income_var,#autocolorscale=True, opacity=0.7, mapbox_style='carto-positron', zoom =10.4, center = {"lat": center_lat,"lon": center_lon, },# width=800,# height=800)income_fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})income_fig.show()
Notice anything? …I feel like the raw median income distribution pretty much tells the whole story, but if we want to fully recreate the Pew maps, we could collapse these income levels down into (low, medium, high) using the methodology from the report’s appendix to produce a map of categorical income levels. For 2021, the most recent year for which IPUMS had the 5-year ACS data, the median income for the DC metro area was $110,355 (for comparison, the national median household income was $70,784), so that (letting \(M\) represent this metro-area median)
The cutoff for low-income (using Pew’s methodology) is \(\frac{2}{3}\cdot M\) = $73,570
The cutoff for high-income (again using Pew’s methodology) is \(2M\) = $220,710
median_income_var ="AOQIE001"# Capitol Building#capitol_lat = 38.889805#capitol_lon = -77.009056# White Housecenter_lat =38.8977center_lon =-77.0365# Here we'll drop NA, since Plotly doesn't handle# NA values as well as NaN valuesgeo_df_nona = geo_df[~pd.isna(geo_df[median_income_var])].copy()# Cutpoints#natl_median = 70000metro_median =110355low_cutoff = (2/3) * metro_medianhigh_cutoff =2* metro_mediandef get_income_level(income):# If NA, we want to keep its category as NAif pd.isna(income):return pd.NAif income < low_cutoff:return"Low"if income > high_cutoff:return"High"return"Medium"geo_df_nona['income_level'] = geo_df_nona[median_income_var].apply(get_income_level)level_fig = px.choropleth_mapbox(geo_df_nona, geojson=geo_df_nona.geometry, color="income_level", locations=geo_df_nona.index,#featureidkey="properties.district", center={"lat": center_lat, "lon": center_lon}, mapbox_style="carto-positron", hover_data=[median_income_var], zoom=10, color_discrete_map={'High': 'green','Medium': 'lightgrey','Low': 'red' })level_fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})level_fig.show()